【算法】8比特数值也能训练模型?商汤提训练加速新算法丨CVPR 2020( 二 )
本文插图
相反的 , 将8bit量化数变换回浮点的过程称之为反量化 。 反量化公式如下所示 , 其中q为量化计算结果 , s为量化系数 , 为反量化后的结果 。
本文插图
上图的上半部分展示了标准的卷积神经网络量化计算前向过程 , 该过程被广泛应用在INT8部署加速中 。 在卷积计算之前 , 量化器会对输入和权重进行量化操作 , 将浮点数量化到8bit数值上 , 通过INT8卷积计算核心 , 即可完成一次INT8前向计算 , 最终将求和得到的32bit数进行反量化操作回算到浮点数域中 , 以供给下一层计算使用 。
INT8训练的一个核心的加速点在于卷积计算的反向过程 , 上图展示了INT8训练中卷积计算在反向传播过程中的计算细节 。 在卷积的反向梯度传播过程 , 同样的将梯度进行浮点量化操作 , 不过为了降低量化的误差 , 针对梯度的量化采用了随机取整操作 。 通过INT8的反向卷积计算核心 , 可以得到下一层所需的回传梯度 , 以及当前层的权重所需的梯度 。 由于INT8反向卷积输出的是32bit数 , 与前传类似 , 需要引入一次反量化操作 , 将32bit数反算回到浮点数域中 。
本文插图
梯度为何难以量化
为什么对梯度进行量化会给网络训练带来如此大的影响?我们可以观察训练过程中的梯度分布情况来进一步的分析 。
本文插图
通过图(a)中对比梯度和输入、权重的分布 , 可以发现:梯度分布相比输入和权重分布更加尖锐 , 同时范围更大 。 相比于输入和权重 , 梯度有更多的值集中在0附近 , 但同时梯度还有许多较大值 , 让梯度的分布范围变得相当广 , 这些特征都会导致梯度量化的量化误差比输入和权重更大 。
本文插图
图(b)展示的是layers16随着训练 , 其梯度从epoch 0到epoch 300的变化情况 。 从中可以看出 , 随着训练的进行 , 梯度分布越变得更加尖锐 , 同时仍然保持着较广的分布范围 , 这意味着梯度量化的误差会随着训练的进行变得越来越大 。
本文插图
梯度的分布随网络深度变化情况从图(c)中可以看出 。 很容易发现 , 卷积层的深度越浅 , 梯度分布越尖锐 , 这也会导致梯度量化的误差更大 。
本文插图
从图(d)中可以看出卷积的结构也会影响梯度分布 , 对于MobileNetV2来说 , conv2为depthwise卷积其相比conv1和conv3具有更加尖锐的分布 。
由于卷积神经网络的梯度具有如上四个特点 , 所以当我们直接在训练中对梯度进行量化时 , 训练精度非常容易出现突发的崩溃情况 。 下图展示了在CIFAR-10数据集上进行实验的精度和损失函数变化曲线 , 以MobileNetv2在CIFAR-10数据集上训练为例 , 其训练的精度曲线和loss曲线如下图 , 从图中可以发现INT8训练的loss在训练初期正常下降 , 但随后迅速上升 , 对应的精度也不断下降 。
本文插图









推荐阅读










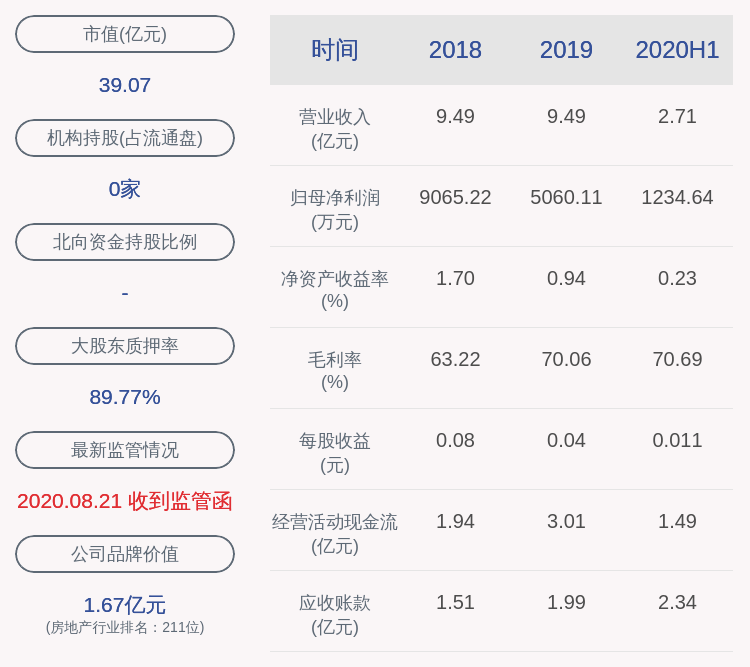





- #大华股份#大华股份AI荣获双目立体匹配算法评测全球排名第一
- ■1580枚比特币!欧洲能源巨头EDP集团惨遭黑客勒索
- [比特币]最新研究:比特币闪电网络上的钱包余额可实现去匿名化,但并非坏事
- 『大比特商务网』可伸缩柔性电路的连接
- 比特币■比特币秘史:那些对比特币改观的人
- ■矿池巨头比特大陆与币印诉讼还有第二幕:究竟是谁动了谁的奶酪?
- 「奥迪」奥迪也拼了!新车比特斯拉酷炫,长超4米9+6块液晶屏,爆408马力
- 「比特币」比特币的火爆绝非偶然,一文看懂比特币的前世今生
- [学点EXCEL不加班]EXCEL批量删除非数值数据,这么多方法你用哪一个?
- #IT168#联芸科技发布新算法,QLC闪存迎来春天