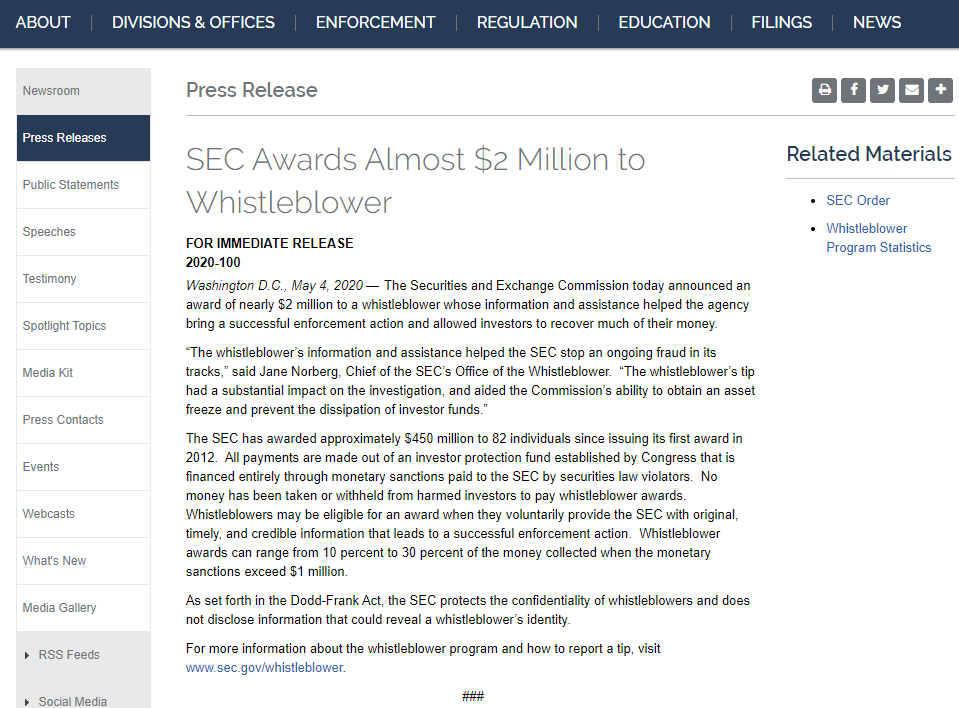
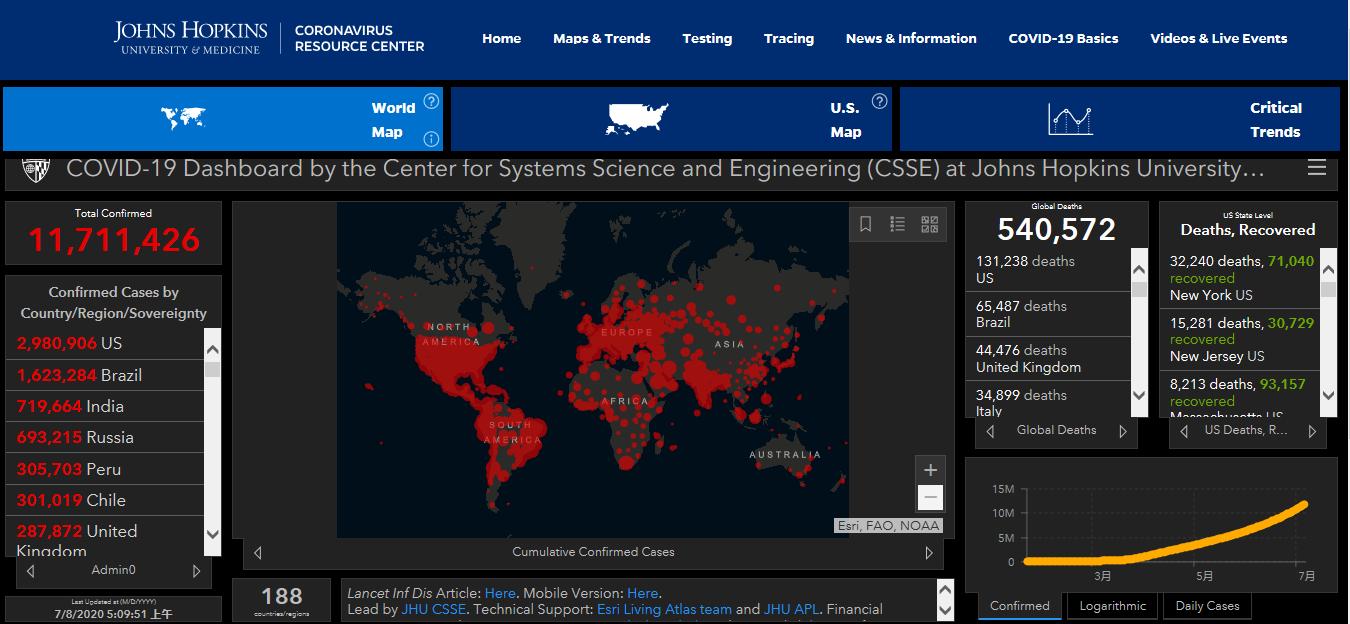
智东西54页PPT全解联邦学习中的同态运算与密文传输【附PPT下载】( 四 )
通过前面的分析 , 我们可以总结下它带来的技术挑战 , 在传统机器学习里面一般会用32位 , 尤其是现有神经网络可能有时会用16位、8位来做为核心的指令 。 因为有芯片级的硬件层面支持 , 所以它的加速的效果是很不错的 。 而联邦机器学习带的挑战就不一样 , 它一般进行计算的是一个大整数 , 刚刚在前面提到 , 如果私钥是1k , 那对于Paillier其实要取平方 , 所以它的计算量再翻一倍 , 同时也有RSA这样的计算 , 并且它们做这些计算不是简单的大数加法或减法 , 而是在大数的基础上做模幂等复杂运算 。 除了参数聚合与使用内网传输之外 , 它还有一个跨方的传输 , 而对于跨方的传输 , 一是迭代轮数会增加 , 二是因为加密 , 体积也会增加 , 所以带来很大的挑战 。
我们可以看下它总体的效果 , 相比于明文计算 , 使用部分同态进行计算 , 计算量大概增长1000倍 。 而使用传统方法 , 根据相关的研究表明要慢一千倍 , 也就是说最终会有慢上100万倍 。 对于密文传输 , 刚刚提到密文体积的膨胀以及传输轮数的增多 , 它实际上把整个传输的数据就增大了成百上千倍 。
根据刚刚说的这些挑战 , 我们跟星云进行了很多探索 , 然后下面请星云的胡总为大家进行下面内容的介绍 。
大家好 , 我是来自星云Clustar的胡水海 。 今天很高兴跟大家分享下我们在使用GPU加速同态运算以及高速网络助力联邦学习密文传输效力的一些探索成果 。
GPU加速同态运算
首先 , 从使用GPU加速同态运算方面来介绍一些探索成果 。 我们对使用GPU加速联邦学习计算做了一些可行性分析 , 主要有四点观察 , 第一个是联邦学习里面所涉及的数据加解密及密态计算 , 不同数据的计算基本是互不影响的 , 所以它满足计算高度可并行的特点 , 而这个特点非常适合用GPU来加速;第二个是联邦学习里面的计算公式本身并不复杂 , 但重复执行的次数巨大 , 所以满足重复的轻量级运算的特点 , 而GPU适合用来加速重复的轻量级计算;第三个是联邦学习中 , 数据IO的时间不到计算时间的0.1% , 因此就属于计算密集型的任务 , 那GPU正好适合用来加速计算密集型任务;最后是联邦学习里面的数据是以批量形式产生 , 并且数据量巨大 , 因此满足批量大数据的特征 , 而GPU也正好适用来加速海量数据的批量计算 。 基于这4点观察 , 认为使用GPU来加速联邦学习是非常可行的一件事情 。
虽然联邦学习有很多性质适合于GPU加速 , 当然也面临着一些挑战 。 我们主要总结了三个挑战 , 第一个是联邦学习需要做大整数的运算 , 大整数指的是1024bit、2048 bit , 甚至是更大的一些大整数 , 但问题是GPU的流处理器在硬件上并不直接支持大整数的直接计算 。 第二个问题是联邦学习里面涉及大量的模幂运算 , 但是GPU并不擅长做模幂运算 , 若让GPU直接做模幂运算 , 它的代价是非常大的 。 第三个是联邦学习的计算需要保存大量的中间计算结果 , 但是由于成本跟能耗的限制 , GPU的显存非常有限 。
本文插图
针对第一个问题 , 我们采用的解决方案是基于分治思想来做元素级并行 。 我以计算大整数乘法a*b为例来讲下我们是如何以分治思想来做数据并行 , 首先将a与b分解成高位跟低位两部分 , 如上图左边的两个公式所示 , 那a*b可以表示为下边所示的一个表达式 , 观察这个表达式发现它里面除了加法以外 , 还有4个紫色标注的乘法子项 , 并且这四个乘法子项并不存在数据关联性 , 因此是可以进行并行计算 。
基于这个思想 , 可以通过递归将大整数乘分解成并行计算的很多小整数乘法 , 这样就可以使用GPU直接进行小整数乘法的运算 。 对于联邦学习涉及的其它运算 , 也可以做类似的元素级并行 。

推荐阅读




![[爆笑影视江小虾]二货夫妻笑话很有味](https://imgcdn.toutiaoyule.com/20200405/20200405203033257911a_t.jpeg)




![[北京日报客户端]人气回暖!北京市购物中心等实体商业客流回暖率接近50%](https://imgcdn.toutiaoyule.com/20200505/20200505235931858447a_t.jpeg)






- 健康plus|因一根鱼刺他差点错失高考!医生:这几种东西先别给考生吃了
- |姐姐说,你头上不能没有这东西
- 进阶▲S20中388点券你可以得到这么多东西~
- 趣味社会学|我也只能放行,忘带驾驶证就算“无证驾驶”?交警:能拿出这东西
- 远藤周作如何通过小说来反思东西方文化的碰撞?
- 低价|3块钱包邮买一个快递盲盒,卖家声称无人认领低价处理,杭州姑娘拆开后里面是这东西
- 美食杰官方|这东西是肉类之王,脂肪极少,夏天常吃不怕胖,比羊肉还养人
- 钱江晚报|4岁孩子耳朵里掉出一颗白色小珠子,惊魂竟来自孩子爱玩的这东西
- 蓝迪潮搭美妆达人|明星之所以穿的如此吸睛,是因为衣服上多了这些东西
- 中国新闻网|东西部协作电商产业节在津闭幕“直播带货”十天销售额超千万元