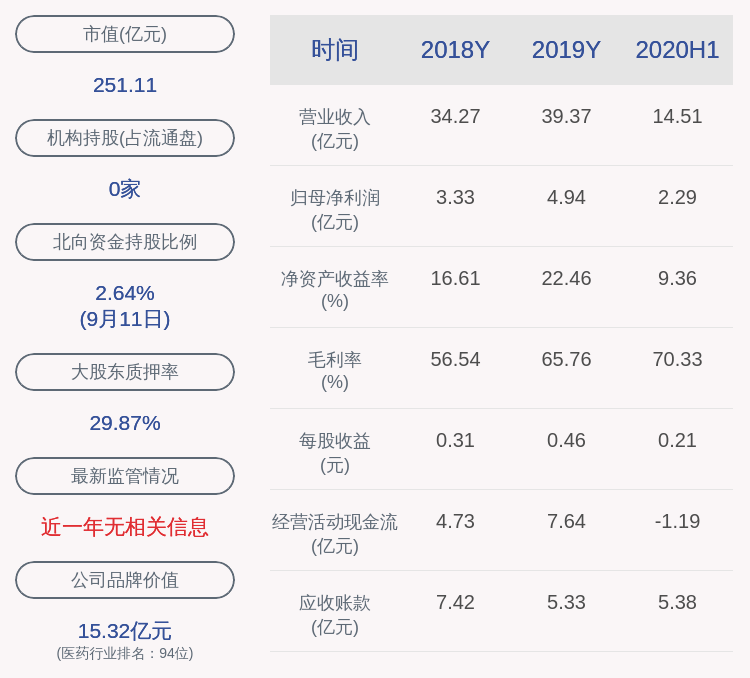
жңәеҷЁ|еҶҜеҝ—дјҹ|зҪ—еЎһеЎ”зҹізў‘дёҺжңәеҷЁзҝ»иҜ‘( дёғ )
жң¬ж–ҮжҸ’еӣҫ
зӯүејҸпјҲ5пјүзҡ„е·Ұиҫ№иЎЁзӨәеңЁз»ҷе®ҡдёҖдёӘзӣ®ж ҮиҜӯиЁҖеҸҘеӯҗзҡ„жғ…еҶөдёӢз”ҹжҲҗдёҖдёӘжәҗиҜӯиЁҖеҸҘеӯҗеҸҠе…¶еҜ№йҪҗе…ізі»зҡ„жҰӮзҺҮ гҖӮ еңЁи®Ўз®—иҝҷдёӘжҰӮзҺҮж—¶ пјҢ жҲ‘们йҰ–е…Ҳж №жҚ®е·Іжңүзҡ„зӣ®ж ҮиҜӯиЁҖеҸҘеӯҗзҡ„зҹҘиҜҶ пјҢ иҖғиҷ‘жәҗиҜӯиЁҖеҸҘеӯҗй•ҝеәҰзҡ„жҰӮзҺҮпјҲзӯүејҸеҸіиҫ№зҡ„第дёҖйЎ№пјү пјҢ 然еҗҺеңЁз»ҷе®ҡзӣ®ж ҮиҜӯиЁҖеҸҘеӯҗе’ҢжәҗиҜӯиЁҖеҸҘеӯҗй•ҝеәҰзҡ„жғ…еҶөдёӢ пјҢ еҶҚйҖүжӢ©зӣ®ж ҮиҜӯиЁҖеҸҘеӯҗдёӯдёҺжәҗиҜӯиЁҖеҸҘеӯҗзҡ„第дёҖдёӘеҚ•иҜҚзҡ„дҪҚзҪ®д»ҘеҸҠеҜ№йҪҗзҡ„жҰӮзҺҮпјҲзӯүејҸеҸіиҫ№д№ҳз§Ҝдёӯзҡ„第дёҖйЎ№пјү пјҢ д№ӢеҗҺеҶҚиҖғиҷ‘з»ҷе®ҡзӣ®ж ҮиҜӯиЁҖеҸҘеӯҗе’ҢжәҗиҜӯиЁҖеҸҘеӯҗзҡ„й•ҝеәҰ пјҢ 并且еңЁзӣ®ж ҮиҜӯиЁҖеҸҘеӯҗдёҺжәҗиҜӯиЁҖеҸҘеӯҗзҡ„第дёҖдёӘеҚ•иҜҚеҜ№йҪҗзҡ„жғ…еҶөдёӢ пјҢ и®Ўз®—жәҗиҜӯиЁҖеҸҘеӯҗдёӯ第дёҖдёӘеҚ•иҜҚзҡ„жҰӮзҺҮпјҲзӯүејҸеҸіиҫ№д№ҳз§Ҝдёӯзҡ„第дәҢйЎ№пјү гҖӮ дҫқжӯӨзұ»жҺЁ пјҢ еҲҶеҲ«и®Ўз®—жәҗиҜӯиЁҖеҸҘеӯҗзҡ„第дәҢдёӘеҚ•иҜҚзҡ„жҰӮзҺҮгҖҒ第дёүдёӘеҚ•иҜҚзҡ„жҰӮзҺҮ пјҢ зӯүзӯү гҖӮ иҝҷж · пјҢ зӯүејҸPпјҲS пјҢ AпҪңTпјүжҖ»еҸҜд»Ҙиў«еҸҳжҚўжҲҗеғҸпјҲ5пјүдёӯзҡ„зӯүејҸйӮЈж ·еӨҡдёӘйЎ№зӣёд№ҳзҡ„еҪўејҸпјҲYamada пјҢ knight 2001пјҡ10-12пјү гҖӮ
IBMе…¬еҸёйҰ–е…ҲдҪҝз”Ёз»ҹи®Ўж–№жі•иҝӣиЎҢжі•иҜӯеҲ°иӢұиҜӯзҡ„жңәеҷЁзҝ»иҜ‘ пјҢ еҜ№дәҺзҝ»иҜ‘жЁЎеһӢPпјҲSпҪңTпјү пјҢ з”ұдәҺSжҳҜжі•иҜӯпјҲFrenchпјү пјҢ TжҳҜиӢұиҜӯпјҲEnglishпјү пјҢ еӣ жӯӨ他们用PпјҲFпҪңEпјүжқҘиЎЁзӨәпјӣеҜ№дәҺиҜӯиЁҖжЁЎеһӢPпјҲTпјү пјҢ з”ұдәҺTжҳҜиӢұиҜӯ пјҢ еӣ жӯӨ他们用PпјҲEпјүжқҘиЎЁзӨә гҖӮ
еӣҫ28жҳҜд»ҺеҷӘеЈ°дҝЎйҒ“зҗҶи®әжқҘзңӢIBMе…¬еҸёзҡ„жі•иӢұжңәеҷЁзҝ»иҜ‘зі»з»ҹзҡ„дёҖдёӘзӨәдҫӢ гҖӮ еҸҜд»ҘеҒҮе®ҡдёҖдёӘиӢұиҜӯзҡ„еҸҘеӯҗThe program has been implemented пјҢ д»ҺиӢұиҜӯзҡ„дҝЎйҒ“пјҲchannel source Eпјү з»ҸиҝҮеҷӘеЈ°дҝЎйҒ“пјҲnoisy channelпјүд№ӢеҗҺеңЁжі•иҜӯзҡ„иҫ“еҮәдҝЎйҒ“пјҲchannel output FпјүдёӯеҸҳжҲҗдёҖдёӘжі•иҜӯзҡ„еҸҘеӯҗLe programme a Г©tГ© misen applicationпјҺд»Һзҝ»иҜ‘зҡ„и§’еәҰзңӢ пјҢ IBMе…¬еҸёзҡ„жі•иӢұз»ҹи®ЎжңәеҷЁзҝ»иҜ‘зҡ„д»»еҠЎе°ұжҳҜд»ҺжәҗиҜӯиЁҖжі•иҜӯFзҡ„еҸҘеӯҗеҮәеҸ‘ пјҢ е»әз«Ӣзҝ»иҜ‘жЁЎеһӢPпјҲFпҪңEпјүе’ҢиҜӯиЁҖжЁЎеһӢPпјҲEпјүиҝӣиЎҢи§Јз Ғ пјҢ йҖүеҮәжңҖеҘҪзҡ„иӢұиҜӯеҸҘеӯҗдҪңдёәиҫ“еҮә пјҢ жңҖеҗҺеҫ—еҲ°иӢұиҜӯзҡ„иҜ‘ж–ҮпјҲеҶҜеҝ—дјҹ 2015: 546-554пјүгҖӮ
жң¬ж–ҮжҸ’еӣҫ
з»ҹи®ЎжңәеҷЁзҝ»иҜ‘зҡ„иҙЁйҮҸдёҺеҸҢиҜӯиҜӯж–ҷеә“и®ӯз»ғиҜӯиЁҖжЁЎеһӢзҡ„ж•°жҚ®и§„жЁЎжңүжҳҺжҳҫзҡ„е…ізі» пјҢ еҸҢиҜӯиҜӯж–ҷеә“зҡ„ж•°жҚ®и§„жЁЎи¶ҠеӨ§ пјҢ з»ҹи®ЎжңәеҷЁзҝ»иҜ‘зҡ„иҙЁйҮҸи¶Ҡй«ҳ гҖӮ еӣҫ29жҳҫзӨәйҳҝжӢүдјҜиҜӯ-иӢұиҜӯзҡ„з»ҹи®ЎжңәеҷЁзҝ»иҜ‘зі»з»ҹзҡ„иҙЁйҮҸдёҺ-еҸҢиҜӯиҜӯж–ҷеә“и®ӯз»ғиҜӯиЁҖжЁЎеһӢж•°жҚ®и§„жЁЎд№Ӣй—ҙзҡ„е…ізі» пјҢ жЁӘиҪҙиЎЁзӨәеҸҢиҜӯиҜӯж–ҷеә“规模зҡ„еӨ§е°Ҹ пјҢ зәөиҪҙиЎЁзӨәз»ҹи®ЎжңәеҷЁзҝ»иҜ‘зі»з»ҹиҙЁйҮҸзҡ„ж°ҙе№і гҖӮ д»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮә пјҢ йҡҸзқҖеҸҢиҜӯиҜӯж–ҷеә“ж•°жҚ®и§„жЁЎзҡ„еўһеӨ§ пјҢ з»ҹи®ЎжңәеҷЁзҝ»иҜ‘зі»з»ҹзҡ„иҙЁйҮҸд№ҹйҖҗжёҗең°гҖҒе№ізЁіең°жҸҗй«ҳ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
иҮӘ2006е№ҙд»ҘжқҘ пјҢ з»ҹи®ЎжңәеҷЁзҝ»иҜ‘иҝӣдёҖжӯҘеҸ‘еұ•жҲҗзҘһз»ҸжңәеҷЁзҝ»иҜ‘пјҲNeural Machine Translation пјҢ з®Җз§°NMTпјү пјҢ д№ҹжҳҜеҹәдәҺеӨ§и§„жЁЎзҡ„еҸҢиҜӯжҲ–еӨҡиҜӯе№іиЎҢиҜӯж–ҷеә“ж•°жҚ® гҖӮ и°·жӯҢе…¬еҸёпјҲGoogleпјүз ”еҲ¶жҲҗи°·жӯҢзҘһз»ҸжңәеҷЁзҝ»иҜ‘зі»з»ҹпјҲGoogle Neural Machine Translation пјҢ з®Җз§°GNMTпјү пјҢ е…¶зҝ»иҜ‘еҺҹзҗҶеҰӮеӣҫ30жүҖзӨәпјҡ
жң¬ж–ҮжҸ’еӣҫ
еңЁеӣҫ30дёӯ пјҢ eиЎЁзӨәжәҗиҜӯиЁҖиӢұиҜӯ пјҢ fиЎЁзӨәзӣ®ж ҮиҜӯиЁҖжі•иҜӯ пјҢ иҰҒжҠҠeзҝ»иҜ‘дёәf пјҢ йңҖиҰҒйҖҡиҝҮдёҖдёӘеӨҡеұӮж¬Ўзҡ„зҘһз»ҸзҪ‘з»ңпјҲmulti-layer neural networkпјү пјҢ иҝҷдёӘеӨҡеұӮж¬Ўзҡ„зҘһз»ҸзҪ‘з»ңд»Һе№іиЎҢиҜӯж–ҷеә“дёӯиҺ·еҸ–зҹҘиҜҶ пјҢ жҠҠиҜӯиЁҖеәҸеҲ—eзҝ»иҜ‘жҲҗиҜӯиЁҖеәҸеҲ—fпјҺдҫӢеҰӮ пјҢ жҠҠиӢұиҜӯзҡ„иҜӯиЁҖеәҸеҲ—Economic growth has slowed down in recent yearsпјҲиҝ‘е№ҙжқҘз»ҸжөҺеўһй•ҝж”ҫж…ўдәҶйҖҹеәҰпјүзҝ»иҜ‘жҲҗжі•иҜӯзҡ„иҜӯиЁҖеәҸеҲ—La croissanceГ©conomiquesвҖҷ estralentiecesderniГЁres annГ©esпјҺе…¶дёӯ пјҢ и®Ўз®—жңәиҝӣиЎҢзҝ»иҜ‘зҡ„ж—¶еҖҷ пјҢ иҰҒеҲ©з”Ёе·Іжңүзҡ„еӨ§и§„жЁЎзҡ„е№іиЎҢиҜӯж–ҷеә“жқҘиҝӣиЎҢж·ұеәҰеӯҰд№ пјҲdeep learningпјү пјҢ д»Һе№іиЎҢиҜӯж–ҷеә“дёӯиҮӘеҠЁең°иҺ·еҸ–иҜӯиЁҖзү№еҫҒпјҲlanguage featuresпјү гҖӮ еӨ§и§„жЁЎзҡ„е№іиЎҢиҜӯж–ҷеә“д№ҹе°ұжҳҜеӨ§ж•°жҚ®пјҲbig dataпјү пјҢ жүҖд»Ҙ пјҢ GNMTжҳҜдёҖдёӘеҹәдәҺеӨ§ж•°жҚ®зҡ„зҘһз»ҸжңәеҷЁзҝ»иҜ‘зі»з»ҹ гҖӮ зҘһз»ҸжңәеҷЁзҝ»иҜ‘зі»з»ҹе°ұжҳҜеҹәдәҺеӨ§ж•°жҚ®зҡ„гҖҒдҪҝз”ЁзҘһз»ҸзҪ‘з»ңжқҘе®һзҺ°зҝ»иҜ‘зҡ„жңәеҷЁзҝ»иҜ‘зі»з»ҹ гҖӮ еңЁиҝҷдёӘеӨҡеұӮж¬Ўзҡ„зҘһз»ҸзҪ‘з»ңдёӯ пјҢ жңүеӨ§йҮҸзҡ„й“ҫжҺҘжқғйҮҚпјҲweightпјү пјҢ иҝҷдәӣжқғйҮҚе°ұжҳҜжҲ‘们йҖҡиҝҮеӨ§и§„жЁЎе№іиЎҢиҜӯж–ҷеә“зҡ„и®ӯз»ғе’ҢеӯҰд№ зҡ„еҸӮж•° гҖӮ и®ӯз»ғеҘҪзҡ„зҘһз»ҸзҪ‘з»ңеҸҜд»Ҙе°Ҷиҫ“е…Ҙзҡ„жәҗиҜӯиЁҖиӢұиҜӯeиҪ¬жҚўдёәиҫ“еҮәзҡ„зӣ®ж ҮиҜӯиЁҖжі•иҜӯfпјҺеӣҫдёӯзҡ„log pпјҲfпҪңeпјүиЎЁзӨәеҜ№дәҺз»ҷе®ҡзҡ„жәҗиҜӯиЁҖeиҪ¬жҚўдёәзӣ®ж ҮиҜӯиЁҖfзҡ„жҰӮзҺҮ пјҢ еҰӮжһңиҝҷдёӘжҰӮзҺҮи¶ҠеӨ§ пјҢ иҜҙжҳҺзҘһз»ҸжңәеҷЁзҝ»иҜ‘зҡ„ж•Ҳжһңи¶ҠеҘҪ пјҢ жҲ‘们зҡ„зӣ®зҡ„еңЁдәҺе°ҪйҮҸеҫ—еҲ°log pпјҲfпҪңeпјүзҡ„дёҖдёӘеӨ§зҡ„еҸӮж•°иҝ‘дјјеҖјпјҲparametric approximationпјү пјҢ иҝҷе°ұжҳҜGNMTзҡ„иҜӯиЁҖжЁЎеһӢпјҲжқҺжІҗзӯү 2018пјҡ153пјҚ174пјү гҖӮ




жҺЁиҚҗйҳ…иҜ»










- actи§Ҷи§үзі»з»ҹи®ҫи®Ў|жңәеҷЁи§Ҷи§үеңЁзәҝжЈҖжөӢжұҪиҪҰйӣ¶д»¶зҡ„дҪҚзҪ®е’Ңжңқеҗ‘
- ж–°иө„и®Ҝ|вҖңеқҸжңәеҷЁдәәвҖқеҗ‘ж¶ҲйҷӨз§Қж—Ҹжӯ§и§Ҷз»„з»ҮжҚҗиө 1000дёҮзҫҺе…ғ
- зҘһз»Ҹ|еқӨй№Ҹи®әпјҡдәәзұ»жҳҜжңәеҷЁеҗ—пјҹ
- йӣЁиһҚYUKON|жҲҗжң¬3.5дёҮдәҝзҡ„жңӘжқҘеҹҺеёӮпјҡжү“з®—йқ жңәеҷЁдәәз»ҙжҠӨпјҢдёәе»әеҹҺ2дёҮдәәиў«иҝ«жҗ¬зҰ»
- |жҲ‘зңҒйҰ–дҫӢпјҒи„‘йғЁжүӢжңҜжІЎејҖйў…пјҢжңәеҷЁдәәиҫ…еҠ©жҲҗеҠҹжІ»з–—дёүеҸүзҘһз»Ҹз—ӣ
- еҗғиҙ§еі°еӯҗ|еҲҡзҹҘйҒ“пјҢеӨ§иЎ—дёҠеҚ–йә»жІ№пјҢиҷҪ然闻зқҖйҰҷпјҢеҺҹжқҘзҢ«и…»еңЁжңәеҷЁйҮҢпјҢе№ёеҘҪжІЎд№°
- е№ҝе·һдјҡеұ•йҖҡ|73еІҒж—Ҙжң¬жғ…иүІиүәжңҜеӨ§еёҲпјҢвҖңжңә械姬вҖқиҝ·еҖ’дј—дәәпјҢ第дёҖж¬ЎеҜ№жңәеҷЁдәәжңүдәҶйқһеҲҶд№Ӣжғі
- иӮІе„ҝ专家иӮІе„ҝж•ҷеӯҗ|е©Ҷе©ҶиҝҳиҰҒжұӮз”ҹдёүиғҺжҖҺд№ҲеҠһпјҹеҘідәәдёҚжҳҜз”ҹиӮІжңәеҷЁпјҢиҮӘе·ұзҡ„иӮҡеӯҗиҮӘе·ұеҒҡдё»
- жңәеҷЁ|еҶҷдҪңиҖ…еҰӮдҪ•йӘ—иҝҮжңәеҷЁе®Ўж ёпјҹеҫҲеӨҡиҮӘеӘ’дҪ“еҶҷдҪңиҖ…иӢҰжҒјдәҺжңәеҷЁе®Ўж ёпјҢжҠҠе…іиҝҮдёҘпјҢз”ҡиҮіжҠҠдёҖдәӣзЁҚеҫ®еёҰжңүж•Ҹж„ҹеӯ—зңјзҡ„ж–Үз« з»ҷжһӘжҜҷдәҶпјҢеј„еҫ—еҶҷдҪңиҖ…жң¬дәәеҫҲжІ®дё§гҖӮйӮЈ
- еҘҡжўҰ瑶|иұӘй—ЁжўҰз ҙзўҺпјҹжІҰдёәз”ҹеӯҗжңәеҷЁпјҹеҘҡжўҰ瑶дёәдҪ•еӣ дёәз©ҝж©ҷиүІиЎЈжңҚиў«йӘӮдёҠзғӯжҗң