жҗңзҙўеј•ж“Һ|зҷҫеәҰжҗңзҙўеј•ж“Һзҡ„жҺ’еҗҚеҺҹзҗҶжҳҜжҖҺж ·зҡ„пјҹ
_еҺҹйўҳдёә зҷҫеәҰжҗңзҙўеј•ж“Һзҡ„жҺ’еҗҚеҺҹзҗҶжҳҜжҖҺж ·зҡ„пјҹ
жҗңзҙўеј•ж“Һзҡ„жҺ’еҗҚеҺҹзҗҶжҳҜжҖҺж ·зҡ„пјҹеӨ§е®¶еҒҡSEOдјҳеҢ–еүҚдёҖе®ҡиҰҒе…ҲдәҶи§Јжё…жҘҡжҗңзҙўеј•ж“Һзҡ„жҺ’еҗҚеҺҹзҗҶ пјҢ еҗҰеҲҷж—ҘеҗҺеҰӮдҪ•еҠӘеҠӣд№ҹеҫҲйҡҫеҒҡеҮәзҗҶжғізҡ„ж•Ҳжһң гҖӮ еҫҲеӨҡз«ҷй•ҝи®Өдёәжҗңзҙўеј•ж“ҺеҜ№е…ій”®иҜҚжҺ’еҗҚзҡ„и®Ўз®—еҺҹзҗҶдјҡеҚҒеҲҶж·ұеҘҘ пјҢ е…¶е®һдёҚ然 пјҢ еҸӘйңҖеӯҰеҘҪд»ҘдёӢдёүдёӘйҳ¶ж®ө пјҢ еӨ§е®¶е°ұеҸҜд»ҘиҪ»жқҫжҺҢжҸЎ гҖӮ дёӢйқў пјҢ жӣҫеәҶе№іSEOе°ұдёәеӨ§е®¶и®ІдёҖдёӢжҗңзҙўеј•ж“Һзҡ„жҺ’еҗҚеҺҹзҗҶжҳҜжҖҺж ·зҡ„ пјҢ еёҢжңӣеҸҜд»Ҙеё®еҲ°дҪ пјҒ
第дёҖйҳ¶ж®өпјҡзҲ¬иЎҢе’ҢжҠ“еҸ–
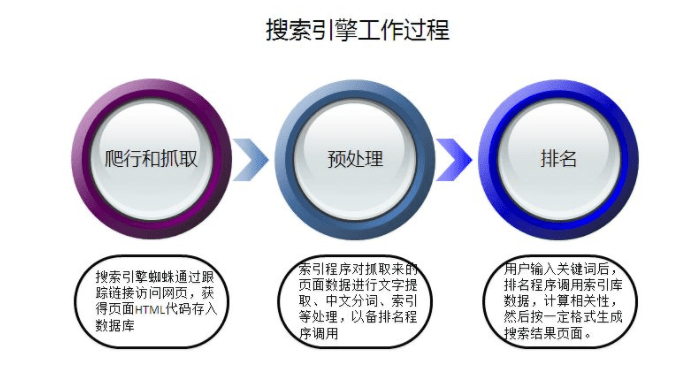
жҗңзҙўеј•ж“Һе·ҘдҪңзҡ„第дёҖжӯҘеҪ“然е°ұжҳҜзҲ¬иЎҢдәҺжҠ“еҸ–пјӣжҗңзҙўеј•ж“ҺиңҳиӣӣеңЁзҲ¬еҸ–зҪ‘з«ҷйЎөйқўж—¶зӣёеҪ“дәҺжҷ®йҖҡз”ЁжҲ·дҪҝз”Ёзҡ„жөҸи§ҲеҷЁ гҖӮ жҗңзҙўеј•ж“ҺеңЁи®ҝй—®йЎөйқўзҡ„ж—¶еҖҷ пјҢ жңҚеҠЎеҷЁиҝ”еӣһHTMLд»Јз Ғ пјҢ иңҳиӣӣзЁӢеәҸжҠҠ收еҲ°зҡ„д»Јз Ғеӯҳе…ҘеҺҹе§ӢйЎөйқўж•°жҚ®еә“ гҖӮ жҗңзҙўеј•ж“ҺдёәдәҶжҸҗй«ҳзҲ¬иЎҢе’ҢжҠ“еҸ–йҖҹеәҰ пјҢ йғҪдҪҝз”ЁеӨҡдёӘиңҳиӣӣ并еҸ‘еҲҶеёғзҲ¬иЎҢ гҖӮ

ж–Үз« еӣҫзүҮ
жҺ’еҗҚеҺҹзҗҶ
е…·дҪ“дәҶи§ЈзҷҫеәҰиңҳиӣӣзҲ¬иЎҢ规еҲҷзҡ„з«ҷй•ҝеҸҜд»ҘзңӢдёҖдёӢиҝҷзҜҮж–Үз« пјҡзҷҫеәҰиңҳиӣӣжҠ“еҸ–规еҲҷжҳҜжҖҺж ·зҡ„ пјҢ жӣҫеәҶе№ід№ӢеүҚе·Із»ҸиҜҰз»Ҷзҡ„еңЁиҝҷзҜҮж–Үз« еҶ…и®ІдәҶзҷҫеәҰиңҳиӣӣжҳҜеҰӮдҪ•зҲ¬иЎҢзҪ‘з«ҷзҡ„ гҖӮ
гҖҗжҗңзҙўеј•ж“Һ|зҷҫеәҰжҗңзҙўеј•ж“Һзҡ„жҺ’еҗҚеҺҹзҗҶжҳҜжҖҺж ·зҡ„пјҹгҖ‘ж•ҙдёӘдә’иҒ”зҪ‘е°ұжҳҜз”ұзӣёдә’й“ҫжҺҘзҡ„зҪ‘з«ҷе’ҢзҪ‘йЎөз»„жҲҗзҡ„ гҖӮ д»ҺзҗҶи®әдёҠиҜҙ пјҢ иңҳиӣӣд»Һд»»дҪ•дёҖдёӘйЎөйқўеҮәеҸ‘ пјҢ йЎәзқҖй“ҫжҺҘйғҪеҸҜд»ҘзҲ¬иЎҢеҲ°зҪ‘з«ҷдёҠзҡ„жүҖжңүйЎөйқў гҖӮ е…¶дёӯ пјҢ жңҖз®ҖеҚ•зҡ„зҲ¬иЎҢйҒҚеҺҶзӯ–з•ҘеҲҶдёәдёӨз§Қ пјҢ дёҖз§ҚжҳҜж·ұеәҰдјҳе…Ҳ пјҢ дёҖз§ҚжҳҜе№ҝеәҰдјҳе…Ҳ гҖӮ ж— и®әжҳҜж·ұеәҰдјҳе…ҲиҝҳжҳҜе№ҝеәҰдјҳе…Ҳзӯ–з•Ҙ пјҢ еҸӘиҰҒз»ҷиңҳиӣӣи¶іеӨҹзҡ„ж—¶й—ҙ пјҢ йғҪиғҪзҲ¬е®Ңж•ҙдёӘдә’иҒ”зҪ‘ гҖӮ еңЁе®һйҷ…е·ҘдҪңдёӯ пјҢ иңҳиӣӣзҡ„еёҰе®Ҫиө„жәҗгҖҒж—¶й—ҙйғҪдёҚжҳҜж— йҷҗзҡ„ пјҢ д№ҹдёҚеҸҜиғҪзҲ¬е®ҢеӨҡжңүйЎөйқў гҖӮ жҗңзҙўеј•ж“ҺиңҳиӣӣжҠ“еҸ–зҡ„ж•°жҚ®еӯҳе…ҘеҺҹе§ӢйЎөйқўж•°жҚ®еә“ гҖӮ е…¶дёӯзҡ„йЎөйқўж•°жҚ®дёҺз”ЁжҲ·жөҸи§ҲеҷЁеҫ—еҲ°зҡ„HTMLжҳҜе®Ңе…ЁдёҖж ·зҡ„ гҖӮ жҜҸдёӘURLйғҪжңүдёҖдёӘзӢ¬зү№зҡ„ж–Ү件编еҸ· гҖӮ
第дәҢйҳ¶ж®өпјҡйў„еӨ„зҗҶ
вҖңйў„еӨ„зҗҶвҖңд№ҹиў«з§°дҪңдёәвҖқзҙўеј•вҖң пјҢ еӣ дёәзҙўеј•жҳҜйў„еӨ„зҗҶжңҖдё»иҰҒзҡ„жӯҘйӘӨ гҖӮ жҗңзҙўеј•ж“ҺиңҳиӣӣжҠ“еҸ–зҡ„еҺҹе§ӢйЎөйқў пјҢ 并дёҚиғҪзӣҙжҺҘз”ЁдәҺжҹҘиҜўжҺ’еҗҚеӨ„зҗҶ гҖӮ еҝ…йЎ»з»ҸиҝҮйў„еӨ„зҗҶйҳ¶ж®ө пјҢ д»ҺHTMLж–Ү件дёӯеҺ»йҷӨж ҮзӯҫгҖҒзЁӢеәҸ пјҢ жҸҗеҸ–еҮәеҸҜд»Ҙз”ЁдәҺжҺ’еҗҚеӨ„зҗҶзҡ„зҪ‘йЎөж–Үеӯ—еҶ…е®№ гҖӮ иңҳиӣӣдјҡе°ҶжҸҗеҸ–еҮәжқҘзҡ„ж–Үеӯ—иҝӣиЎҢдёӯж–ҮеҲҶиҜҚгҖҒеҺ»йҷӨеҒңжӯўиҜҚгҖҒж¶ҲйҷӨеҷӘеЈ°гҖҒеҺ»йҮҚзӯүеӨ„зҗҶ пјҢ жҸҗеҸ–еҮәйЎөйқўдёӯйҮҚиҰҒзҡ„ж–Үеӯ— пјҢ е»әз«Ӣе…ій”®иҜҚдёҺйЎөйқўзҡ„зҙўеј• пјҢ еҪўжҲҗзҙўеј•иҜҚеә“иЎЁ гҖӮ е»әз«Ӣзҙўеј•зҡ„иҝҮзЁӢдёӯжңүжӯЈеҗ‘зҙўеј•е’ҢеҖ’жҺ’зҙўеј•дёӨз§ҚжҺ’еәҸж–№ејҸ пјҢ дҪҝеҫ—жҺ’еәҸжӣҙеҠ еҮҶзЎ® гҖӮ
еҸҰеӨ– пјҢ й“ҫжҺҘе…ізі»и®Ўз®—д№ҹжҳҜйў„еӨ„зҗҶдёӯеҫҲйҮҚиҰҒзҡ„дёҖйғЁеҲҶ гҖӮ зҺ°еңЁжүҖжңүзҡ„дё»жөҒжҗңзҙўеј•ж“ҺжҺ’еҗҚеӣ зҙ дёӯйғҪеҢ…еҗ«зҪ‘йЎөд№Ӣй—ҙзҡ„й“ҫжҺҘжөҒеҠЁдҝЎжҒҜ гҖӮ жҗңзҙўеј•ж“ҺеңЁжҠ“еҸ–йЎөйқўеҶ…е®№еҗҺ пјҢ еҝ…йЎ»дәӢеүҚи®Ўз®—еҮәпјҡйЎөйқўдёҠжңүе“Әдәӣй“ҫжҺҘжҢҮеҗ‘е“Әдәӣе…¶д»–йЎөйқў пјҢ жҜҸдёӘйЎөйқўжңүе“ӘдәӣеҜје…Ҙй“ҫжҺҘ пјҢ й“ҫжҺҘдҪҝз”ЁдәҶд»Җд№ҲжҸҸж–Үеӯ— пјҢ иҝҷдәӣеӨҚжқӮзҡ„й“ҫжҺҘжҢҮеҗ‘е…ізі»еҪўжҲҗдәҶзҪ‘з«ҷе’ҢйЎөйқўзҡ„й“ҫжҺҘжқғйҮҚ гҖӮ
ж–Үз« еӣҫзүҮ
жҺ’еҗҚеҺҹзҗҶ
第дёүйҳ¶ж®өпјҡе…ій”®иҜҚжҺ’еҗҚ
з»ҸиҝҮжҗңзҙўеј•ж“ҺиңҳиӣӣжҠ“еҸ–йЎөйқў пјҢ зҙўеј•зЁӢеәҸи®Ўз®—еҫ—еҲ°еҖ’жҺ’зҙўеј•еҗҺ пјҢ жҗңзҙўеј•ж“Һе°ұеҮҶеӨҮйҡҸж—¶еӨ„зҗҶз”ЁжҲ·зҡ„жҗңзҙўйңҖжұӮдәҶ гҖӮ жҗңзҙўеј•ж“Һдё»иҰҒеҜ№з”ЁжҲ·зҡ„жҗңзҙўиҜҚиҝӣиЎҢдёӯж–ҮеҲҶиҜҚеӨ„зҗҶ пјҢ еҺ»еҒңжӯўиҜҚеӨ„зҗҶгҖҒжҢҮд»ӨеӨ„зҗҶгҖҒжӢјеҶҷй”ҷиҜҜзҹ«жӯЈгҖҒж•ҙеҗҲжҗңзҙўеӨ„зҪҡзӯүеӨ„зҗҶиҝӣиЎҢз”ЁжҲ·жҗңзҙўиҜҚжңүжҗңзҙўеј•ж“Һзҙўеј•иҜҚеә“зҡ„еҢ№й…Қ пјҢ е»әз«Ӣе…ій”®иҜҚжҺ’еҗҚ гҖӮ
жҖ»з»“пјҡеҰӮд»ҠжүҖжңүжҗңзҙўеј•ж“Һзҡ„еҹәжң¬жҺ’еҗҚеҺҹзҗҶе°ұжҳҜдёҠйқўжұҮжҖ»зҡ„дёүдёӘйҳ¶ж®ө пјҢ дҪҶйҡҸзқҖжҗңзҙўеј•ж“Һзҡ„规иҢғеҢ– пјҢ ж ҮеҮҶеҢ– пјҢ зҺ°еңЁжҗңзҙўеј•ж“Һи¶ҠжқҘи¶ҠжіЁйҮҚзҪ‘з«ҷзҡ„еҶ…е®№иҙЁйҮҸ пјҢ еңЁжҗңзҙўеј•зңӢжқҘ пјҢ еҸӘжңүзңҹжӯЈи§ЈеҶіеҘҪз”ЁжҲ·йңҖжұӮзҡ„зҪ‘з«ҷжүҚдјҡиў«жҗңзҙўеј•ж“Һи®ӨдёәжҳҜеҜ№зӣёе…іе…ій”®иҜҚиҙЎзҢ®жңҖеӨ§зҡ„зҪ‘з«ҷ пјҢ иҙЎзҢ®и¶ҠеӨҡ пјҢ е…ій”®иҜҚжҺ’еҗҚз»“жһңе°ұдјҡи¶ҠеҘҪ гҖӮ
жң¬ж–ҮеҺҹеҲӣжқҘжәҗдәҺе…ій”®иҜҚжҺ’еҗҚwww.tianying888.comиҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҒ
жҺЁиҚҗйҳ…иҜ»


















- з»јиүәиҠӮзӣ®|иүәдәәж–°еӘ’дҪ“жҢҮж•°з»јиүәжҺ’еҗҚпјҢеӣӣдҪҚжҳҺжҳҹиғҪиҝӣеүҚеҚҒпјҢиҝҷиҠӮзӣ®еұ…еҠҹиҮідјҹпјҒ
- зү№жң—жҷ®|зҡ®е°Өпјҡ14еӣҪж°‘дј—з»ҷиҮӘе·ұеӣҪ家жҠ—з–«жү“еҲҶ зҫҺеӣҪжҺ’еҗҚеһ«еә•
- зҡ®е°Ө|зҡ®е°Өпјҡ14еӣҪж°‘дј—з»ҷиҮӘе·ұеӣҪ家жҠ—з–«жү“еҲҶ зҫҺеӣҪжҺ’еҗҚеһ«еә•
- зҡ®е°Өпјҡ14еӣҪж°‘дј—з»ҷиҮӘе·ұеӣҪ家жҠ—з–«жү“еҲҶ зҫҺеӣҪжҺ’еҗҚеһ«еә•
- еҗҢжҜ”|зҷҫеәҰApolloжҲ–е°ҶеңЁе№ҝе·һеҗҢж—¶иҗҪең°RobotaxiгҖҒRobobus пјӣдёӯеӣҪз”өеҪұдёҠеҚҠе№ҙеҮҖеҲ©дәҸжҚҹ5.02дәҝе…ғпјӣеҫ®дҝЎеҶ…жөӢвҖңзҫӨ
- еј йӣЁ|еӯҹдҪіи§Ӯдј—е–ңзҲұжҺ’еҗҚ第дёҖ, й•ңеӨҙжү«иҝҮеј йӣЁз»®, зңӢжё…иЎЁжғ…, 笑еҲ°иӮҡеӯҗжҠҪзӯӢ
- з»јиүә|еҫ·дә‘зӨҫзҝ»иҪҰпјҹж–°з»јиүәжҺ’еҗҚеһ«еә•пјҢйғӯеҫ·зәІдәҺи°Ұжҙ»жӢӣзүҢдёҚеҘҪдҪҝдәҶпјҹ
- еј иүәеҮЎ|еҫҗиүәжҙӢдёҚиғҪеҮәйҒ“ й»„еӯҗйҹ¬дәӢе…Ҳ并дёҚзҹҘжғ… е…¬еёғжҺ’еҗҚж—¶зҡ„иЎЁжғ…иҜҙжҳҺдёҖеҲҮ
- еұ•зҫҪ|гҖҠе°‘е№ҙд№ӢеҗҚгҖӢйҰ–ж¬ЎйЎәдҪҚжҺ’еҗҚпјҡе·Ұжһ—жқ°2гҖҒе·ҰеҸ¶5гҖҒйғӯйңҮ7гҖҒжһ—жҹ“8гҖҒеұ•зҫҪ15
- [дёӯеӣҪз»ҸиҗҘжҠҘ]зҷҫеәҰзҪ‘зӣҳпјҡеёғеұҖдёӘдәәвҖңдә‘ж—¶д»ЈвҖқдёӯеӣҪз»ҸиҗҘжҠҘ2020-08-29 06:46:310йҳ…