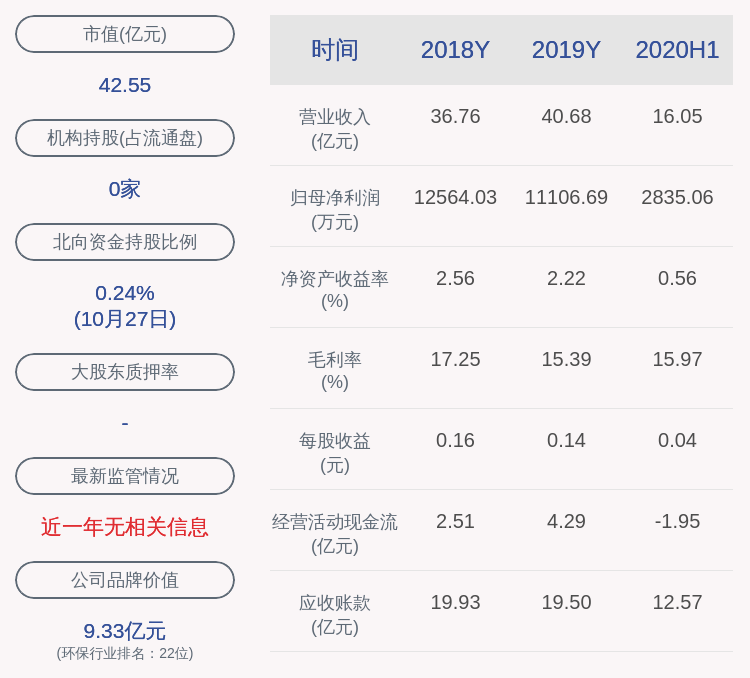
дёӯе№ҙ|еҫ®иҪҜдәҡжҙІз ”究йҷўзҺӢдә•дёңпјҡдёӢдёҖд»Ји§Ҷи§үиҜҶеҲ«зҡ„еҹәжң¬зҪ‘з»ңз»“жһ„жҳҜд»Җд№Ҳж ·зҡ„пјҹ | CCF-GAIR 2020( дәҢ )
дҪҶжҳҜеңЁе…¶е®ғд»»еҠЎдёӯ пјҢ жҜ”еҰӮжЈҖжөӢ пјҢ жҲ‘们йңҖиҰҒзҹҘйҒ“жЈҖжөӢжЎҶзҡ„з©әй—ҙдҪҚзҪ® пјҢ жҜ”еҰӮеҲҶеүІ пјҢ жҲ‘们йңҖиҰҒжҜҸдёӘеғҸзҙ зҡ„ж Үзӯҫ пјҢ еңЁдәәи„ёе’ҢдәәдҪ“зҡ„е…ій”®зӮ№зҡ„жЈҖжөӢдёӯ пјҢ жҲ‘们йңҖиҰҒе…ій”®зӮ№зҡ„з©әй—ҙдҪҚзҪ® пјҢ иҝҷж ·дёҖзі»еҲ—зҡ„д»»еҠЎе®һйҷ…дёҠйңҖиҰҒз©әй—ҙзІҫеәҰжҜ”иҫғй«ҳзҡ„иЎЁеҫҒ пјҢ жҲ‘们称д№Ӣдёәй«ҳеҲҶиҫЁзҺҮиЎЁеҫҒ гҖӮ
зӣ®еүҚдёҡеҶ…еӯҰд№ й«ҳеҲҶиҫЁзҺҮиЎЁеҫҒжңүеҮ дёӘеҺҹеҲҷ пјҢ дёҖиҲ¬жҳҜд»ҘеҲҶзұ»зҡ„зҪ‘з»ңжһ¶жһ„дҪңдёәдё»е№ІзҪ‘з»ң пјҢ еңЁжӯӨеҹәзЎҖдёҠеӯҰд№ дёҖдәӣй«ҳеҲҶиҫЁзҺҮзҡ„иЎЁеҫҒ гҖӮ
еӯҰд№ й«ҳеҲҶиҫЁзҺҮиЎЁеҫҒ пјҢ жңүдёҖз§ҚдёҠйҮҮж ·зҡ„ж–№жі• пјҢ еҢ…жӢ¬дёӨдёӘжӯҘйӘӨ пјҢ 第дёҖдёӘжӯҘйӘӨжҳҜеҲҶзұ»зҡ„зҪ‘з»ңжһ¶жһ„ пјҢ иЎЁеҫҒејҖе§ӢжҜ”иҫғеӨ§ пјҢ 然еҗҺж…ўж…ўеҸҳе°Ҹпјӣ第дәҢдёӘжӯҘйӘӨ пјҢ йҖҡиҝҮдёҠйҮҮж ·зҡ„ж–№жі•йҖҗжӯҘд»ҺдҪҺеҲҶиҫЁзҺҮжҒўеӨҚй«ҳеҲҶиҫЁзҺҮ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еёёи§Ғзҡ„зҪ‘з»ңжһ¶жһ„ пјҢ жҜ”еҰӮU-Net пјҢ дё»иҰҒеә”з”ЁеңЁеҢ»еӯҰеӣҫеғҸ пјҢ SegNetдё»иҰҒжҳҜз”ЁдәҺи®Ўз®—жңәи§Ҷи§үйўҶеҹҹ пјҢ иҝҷеҮ дёӘз»“жһ„зңӢиө·жқҘеҫҲдёҚеҗҢ пјҢ е…¶е®һжң¬иҙЁйғҪдёҖж · гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еҰӮжӯӨдёҖжқҘ пјҢ еҲҶиҫЁзҺҮејҖе§Ӣй«ҳ пјҢ 然еҗҺйҷҚдҪҺдәҶ пјҢ 然еҗҺеҚҮй«ҳ гҖӮ иҝҮзЁӢдёӯ пјҢ е…ҲеӨұеҺ»дәҶз©әй—ҙзІҫеәҰ пјҢ 然еҗҺж…ўж…ўжҒўеӨҚ пјҢ жңҖз»ҲеӯҰеҲ°зҡ„зү№еҫҒз©әй—ҙзІҫеәҰиҫғејұ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳ пјҢ жҲ‘们жҸҗеҮәдәҶдёҖз§Қж–°еһӢзҡ„й«ҳеҲҶиҫЁзҺҮиЎЁеҫҒеӯҰд№ ж–№жі• пјҢ з®Җз§°дёәHRNet гҖӮ HRNetеҸҜд»Ҙи§ЈеҶіеүҚйқўжҸҗеҲ°зҡ„д»ҺAlexNetеҲ°DenseNetйғҪеӯҳеңЁзҡ„й—®йўҳ пјҢ жҲ‘们и®ӨдёәдёӢдёҖдёӘзҪ‘з»ңз»“жһ„жҳҜHRNet гҖӮ
HRNetдёҺд»ҘеүҚзҡ„зҪ‘з»ңз»“жһ„дёҚеҗҢ пјҢ е®ғдёҚжҳҜд»ҺеҲҶзұ»д»»еҠЎеҮәеҸ‘ пјҢ е®ғеҸҜд»Ҙи§ЈеҶіжӣҙе№ҝжіӣзҡ„и®Ўз®—жңәи§Ҷи§үй—®йўҳ гҖӮ
жҲ‘们зҡ„зӣ®зҡ„жҳҜеӯҰд№ дёҖдёӘз©әй—ҙзІҫеәҰејәзҡ„иЎЁеҫҒ пјҢ жҲ‘们и®ҫи®Ўзҡ„HRNetдёҚжҳҜжІҝз”Ёд»ҘеүҚзҡ„еҲҶзұ»з»“жһ„ пјҢ д№ҹдёҚжҳҜд»ҺдҪҺеҲҶиҫЁзҺҮжҒўеӨҚеҲ°й«ҳеҲҶиҫЁзҺҮ пјҢ иҖҢжҳҜд»Һйӣ¶ејҖе§Ӣ пјҢ иҮӘе§ӢиҮіз»ҲйғҪз»ҙжҢҒй«ҳеҲҶиҫЁзҺҮ пјҢ дҪ“зҺ°дәҶз©әй—ҙеҲҶиҫЁзҺҮиҫғејәзҡ„иЎЁеҫҒ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
иҝҷдёӘз»“жһ„жҳҜеҰӮдҪ•и®ҫи®ЎпјҹдҪңдёәеҜ№жҜ” пјҢ жҲ‘们е…ҲеҲҶжһҗеҲҶзұ»зҡ„зҪ‘з»ңз»“жһ„еҺҹзҗҶ гҖӮ
еңЁдёӢеӣҫзҡ„дҫӢеӯҗйҮҢ пјҢ жңүй«ҳеҲҶиҫЁзҺҮзҡ„еҚ·з§ҜпјҲз®ӯеӨҙд»ЈиЎЁеҚ·з§Ҝзӯүзҡ„и®Ўз®—ж“ҚдҪң пјҢ иҝҷдәӣжЎҶжҳҜиЎЁеҫҒпјү пјҢ жңүдёӯзӯүеҲҶиҫЁзҺҮзҡ„еҚ·з§Ҝ пјҢ жңҖз»Ҳеҫ—еҲ°дҪҺеҲҶиҫЁзҺҮзҡ„иЎЁеҫҒ гҖӮ еҲҶзұ»зҪ‘з»ңдёӯ пјҢ иҝҷдёүи·ҜжҳҜдёІиҒ”зҡ„ пјҢ зҺ°еңЁжҲ‘们жҠҠиҝҷдёүи·Ҝ并иҒ” пјҢ и®©жҜҸдёҖи·ҜеүҚж–°еўһеҠ дёҖи·Ҝ пјҢ жңҖз»ҲжӢҝеҲ°дёҖдёӘй«ҳеҲҶиҫЁзҺҮзҡ„иЎЁеҫҒ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
жң¬ж–ҮжҸ’еӣҫ
жң¬ж–ҮжҸ’еӣҫ
иҝҷж ·еӨ§е®¶дјҡжңүз–‘й—® пјҢ дёүи·ҜжҳҜзӢ¬з«Ӣзҡ„ пјҢ йҷӨдәҶж–°еўһеҠ зҡ„зӣёе…іиҒ”д№ӢеӨ– пјҢ е…¶е®ғзҡ„йғҪдёҚдә§з”ҹе…ізі» пјҢ иҝҷж ·дјҡжҚҹеӨұд»Җд№ҲпјҹеңЁдҪҺеҲҶиҫЁзҺҮж–№йқў пјҢ е®ғеҸҜд»ҘеӯҰд№ еҲ°еҫҲеҘҪзҡ„иҜӯд№үдҝЎжҒҜ пјҢ еңЁй«ҳеҲҶиҫЁзҺҮйҮҢ пјҢ е®ғзҡ„з©әй—ҙзІҫеәҰйқһеёёејә пјҢ иҝҷдёүи·Ҝд№Ӣй—ҙзҡ„дҝЎжҒҜжІЎжңүеҪўжҲҗдә’иЎҘ гҖӮ
жҲ‘们йҮҮз”Ёзҡ„ж–№жі• пјҢ жҳҜи®©дёүи·ҜдёҚеҒңең°дәӨдә’ пјҢ дҪҝеҫ—й«ҳеҲҶиҫЁзҺҮеҸҜд»ҘиҺ·еҫ—дҪҺеҲҶиҫЁзҺҮиҜӯд№үдҝЎжҒҜиҫғејәзҡ„иЎЁеҫҒ пјҢ дҪҺеҲҶиҫЁзҺҮеҸҜд»ҘиҺ·еҫ—й«ҳеҲҶиҫЁзҺҮзҡ„з©әй—ҙзІҫеәҰиҫғејәзҡ„иЎЁеҫҒ пјҢ дёҚеҒңең°иһҚеҗҲ пјҢ жңҖз»ҲеҸ–еҫ—жӣҙејәзҡ„й«ҳеҲҶиҫЁзҺҮиЎЁеҫҒ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
з®ҖеҚ•жқҘи®І пјҢ д»ҘеүҚзҡ„й«ҳеҲҶиҫЁзҺҮжҳҜйҖҡиҝҮеҚҮй«ҳгҖҒйҷҚдҪҺеҶҚеҚҮй«ҳиҺ·еҫ— пјҢ жҲ‘们йҖҡиҝҮе°ҶдёҚеҗҢеҲҶиҫЁзҺҮзҡ„еҚ·з§Ҝз”ұдёІиҒ”еҸҳжҲҗ并иҒ” пјҢ иҮӘе§ӢиҮіз»ҲдҝқжҢҒй«ҳеҲҶиҫЁзҺҮ пјҢ 并且иҝҳеҠ е…ҘдёҚеҗҢеҲҶиҫЁзҺҮд№Ӣй—ҙзҡ„дәӨдә’ пјҢ дҪҝеҫ—й«ҳеҲҶиҫЁзҺҮиЎЁеҫҒе’ҢдҪҺеҲҶиҫЁзҺҮиЎЁеҫҒзҡ„дә’еҠЁеҸҳејә пјҢ иҺ·еҫ—еҜ№ж–№зҡ„дјҳеҠҝзү№еҫҒ пјҢ жңҖз»ҲиҺ·еҫ—йқһеёёејәзҡ„й«ҳеҲҶиҫЁзҺҮиЎЁеҫҒ гҖӮ








жҺЁиҚҗйҳ…иҜ»













- дёӯе№ҙ|еҢ—ж–—вҖңдёҖеј зҪ‘вҖқеҸҜе®һзҺ°е…ЁеӨ©еҖҷгҖҒй«ҳзІҫеәҰгҖҒиҮӘдё»еҸҜжҺ§жңҚеҠЎ
- дёӯе№ҙ|Pythonзј–зЁӢиҜӯиЁҖжңүд»Җд№ҲзӢ¬зү№зҡ„дјҳеҠҝе‘ў?
- дёӯе№ҙ|и°ҲдёҖи°ҲжҲ‘зҡ„еҚҒе№ҙжңәжў°е·ҘдҪңз»ҸеҺҶ
- дёӯе№ҙ|еј№ж— иҷҡеҸ‘зҡ„иғҢеҗҺпјҢеӣҪдә§еј№иҚҜиҙЁйҮҸжҠҠе…ідәәпјҢзІҫеҜҶжңәеәҠйғҪиҰҒиҮӘеҸ№дёҚеҰӮ
- дёӯе№ҙ|е®ҝиҝҒж·ұеңіжӢӣе•ҶеҶҚз»“зЎ•жһңпјҢзӯҫзәҰйЎ№зӣ®19дёӘпјҢеҚҸи®®жҖ»жҠ•иө„158дәҝе…ғ
- еҫ®иҪҜ|еҫ®иҪҜ收иҙӯTiKToKпјҢеҸҢж–№48е°Ҹж—¶еҶ…е®ҢжҲҗ收иҙӯпјҢйҮ‘йўқиҝңдҪҺйў„жңҹ
- дёӯе№ҙ|иӢ№жһңпјҡе·Із»ҲжӯўEpic GamesејҖеҸ‘иҖ…иҙҰеҸ·
- дёӯе№ҙ|еңҶж»Ўзҡ„з»“еұҖпјҒиӢ№жһңеҫ®дҝЎд№Ӣй—ҙдёҚз”ЁеҶҚдәҢйҖүдёҖпјҢзҫҺеӣҪж”ҝеәңиҝҳжҳҜеҒҡеҮәи®©жӯҘ
- дёӯе№ҙ|еӣҪ家иғҪжәҗйӣҶеӣўжҲҗеҠҹз ”еҸ‘зҹҝз”ЁеҚЎиҪҰиғҪиҖ—еҲ¶еҠЁејҖе…ійў„иӯҰиЈ…зҪ®
- з”өи„‘дҪҝз”ЁжҠҖе·§|еҫ®иҪҜйҮҚж–°еҸ‘еёғиЎҘдёҒеҜ№Windows 10жӣҙж–°пјҡдҝ®еӨҚзЈҒзӣҳдјҳеҢ–зЁӢеәҸзӯү