дёҡеҠЎ|ж»ҙж»ҙеҹәдәҺ Flink зҡ„е®һж—¶ж•°д»“е»әи®ҫе®һи·ө( дёү )
иҜҘеұӮдё»иҰҒзҡ„е·ҘдҪңжҳҜжҠҠе®һж—¶жұҮжҖ»ж•°жҚ®еҶҷе…Ҙеә”з”Ёзі»з»ҹзҡ„ж•°жҚ®еә“дёӯпјҢеҢ…жӢ¬з”ЁдәҺеӨ§еұҸжҳҫзӨәе’Ңе®һж—¶ OLAP зҡ„ Druid ж•°жҚ®еә“дёӯпјҢз”ЁдәҺе®һж—¶ж•°жҚ®жҺҘеҸЈжңҚеҠЎзҡ„ Hbase ж•°жҚ®еә“пјҢз”ЁдәҺе®һж—¶ж•°жҚ®дә§е“Ғзҡ„ MySQL жҲ–иҖ… Redis ж•°жҚ®еә“дёӯгҖӮ
е‘ҪеҗҚ规иҢғпјҡеҹәдәҺе®һж—¶ж•°д»“зҡ„зү№ж®ҠжҖ§дёҚеҒҡзЎ¬жҖ§иҰҒжұӮгҖӮ
3. йЎәйЈҺиҪҰе®һж—¶ж•°д»“е»әи®ҫжҲҗжһң
жҲӘжӯўзӣ®еүҚпјҢдёҖе…ұдёәйЎәйЈҺиҪҰдёҡеҠЎзәҝе»әз«ӢдәҶеўһй•ҝгҖҒдәӨжҳ“гҖҒдҪ“йӘҢгҖҒе®үе…ЁгҖҒиҙўеҠЎдә”еӨ§жЁЎеқ—пјҢж¶үеҸҠ 40+ зҡ„е®һж—¶зңӢжқҝпјҢж¶өзӣ–йЎәйЈҺиҪҰе…ЁйғЁж ёеҝғдёҡеҠЎиҝҮзЁӢпјҢе®һж—¶е’ҢзҰ»зәҝж•°жҚ®иҜҜе·®<0.5%пјҢжҳҜйЎәйЈҺиҪҰдёҡеҠЎзәҝж•°жҚ®еҲҶжһҗж–№йқўзҡ„жңүеҲ©иЎҘе……пјҢдёәйЎәйЈҺиҪҰеҪ“еӨ©еҸ‘еҲёеҠЁжҖҒзӯ–з•Ҙи°ғж•ҙпјҢеҸёд№ҳе®үе…Ёзӣёе…ізӣ‘жҺ§пјҢе®һж—¶и®ўеҚ•и¶ӢеҠҝеҲҶжһҗзӯүжҸҗдҫӣдәҶе®һж—¶ж•°жҚ®ж”ҜжҢҒпјҢжҸҗй«ҳдәҶеҶізӯ–зҡ„ж—¶ж•ҲжҖ§гҖӮ
еҗҢж—¶е»әз«ӢеңЁж•°д»“жЁЎеһӢд№ӢдёҠзҡ„е®һж—¶жҢҮж ҮиғҪж №жҚ®з”ЁжҲ·йңҖжұӮеҸҠж—¶е®ҢжҲҗеҸЈеҫ„еҸҳжӣҙе’Ңе®һж—¶зҰ»зәҝж•°жҚ®дёҖиҮҙжҖ§ж ЎйӘҢпјҢеӨ§еӨ§жҸҗй«ҳдәҶе®һж—¶жҢҮж Үзҡ„ејҖеҸ‘ж•ҲзҺҮе’Ңе®һж—¶ж•°жҚ®зҡ„еҮҶзЎ®жҖ§пјҢд№ҹдёәе…¬еҸёеҶ…йғЁеӨ§иҢғеӣҙе»әи®ҫе®һж—¶ж•°д»“жҸҗдҫӣдәҶжңүеҠӣзҡ„зҗҶи®әе’Ңе®һи·өж”ҜжҢҒгҖӮ
4. е®һж—¶ж•°д»“е»әи®ҫеҜ№ж•°жҚ®е№іеҸ°зҡ„ејәдҫқиө–
зӣ®еүҚе…¬еҸёеҶ…йғЁзҡ„е®һж—¶ж•°д»“е»әи®ҫпјҢйңҖиҰҒдҫқжүҳж•°жҚ®е№іеҸ°зҡ„иғҪеҠӣжүҚиғҪзңҹжӯЈе®ҢжҲҗиҗҪең°пјҢеҢ…жӢ¬ StreamSQL иғҪеҠӣпјҢж•°жҚ®жўҰе·ҘзЁӢ StreamSQL IDE зҺҜеўғе’Ңд»»еҠЎиҝҗз»ҙ组件пјҢе®һж—¶ж•°жҚ®жәҗе…ғж•°жҚ®еҢ–еҠҹиғҪзӯүгҖӮ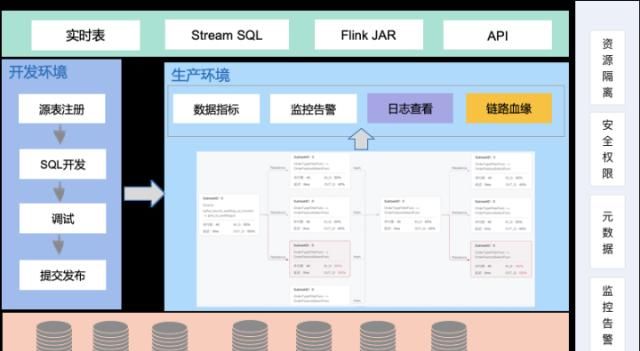
ж–Үз« еӣҫзүҮ
4.1 еҹәдәҺStreamSQLзҡ„е®һж—¶ж•°жҚ®йңҖжұӮејҖеҸ‘
StreamSQL жҳҜж»ҙж»ҙеӨ§ж•°жҚ®еј•ж“ҺйғЁеңЁ Flink SQL еҹәзЎҖдёҠе®Ңе–„еҗҺеҪўжҲҗзҡ„дёҖдёӘдә§е“ҒгҖӮ
дҪҝз”Ё StreamSQL е…·жңүеӨҡдёӘдјҳеҠҝпјҡ
жҸҸиҝ°жҖ§иҜӯиЁҖпјҡдёҡеҠЎж–№дёҚйңҖиҰҒе…іеҝғеә•еұӮе®һзҺ°пјҢеҸӘйңҖиҰҒе°ҶдёҡеҠЎйҖ»иҫ‘жҸҸиҝ°еҮәжқҘеҚіеҸҜгҖӮ
жҺҘеҸЈзЁіе®ҡпјҡFlink зүҲжң¬иҝӯд»ЈиҝҮзЁӢдёӯеҸӘиҰҒ SQL иҜӯжі•дёҚеҸ‘з”ҹеҸҳеҢ–е°ұйқһеёёзЁіе®ҡгҖӮ
й—®йўҳжҳ“жҺ’жҹҘпјҡйҖ»иҫ‘жҖ§иҫғејәпјҢз”ЁжҲ·иғҪзңӢжҮӮиҜӯжі•еҚіеҸҜи°ғжҹҘеҮәй”ҷдҪҚзҪ®гҖӮ
жү№жөҒдёҖдҪ“еҢ–пјҡжү№еӨ„зҗҶдё»иҰҒжҳҜ HiveSQL е’Ң Spark SQLпјҢеҰӮжһң Flink д»»еҠЎд№ҹдҪҝз”Ё SQL зҡ„иҜқпјҢжү№еӨ„зҗҶд»»еҠЎе’ҢжөҒеӨ„зҗҶд»»еҠЎеңЁиҜӯжі•зӯүж–№йқўеҸҜд»ҘиҝӣиЎҢе…ұдә«пјҢжңҖз»Ҳе®һзҺ°дёҖдҪ“еҢ–зҡ„ж•ҲжһңгҖӮ
StreamSQL зӣёеҜ№дәҺ Flink SQL зҡ„е®Ңе–„пјҡ
е®Ңе–„ DDLпјҡеҢ…жӢ¬дёҠжёёзҡ„ж¶ҲжҒҜйҳҹеҲ—гҖҒдёӢжёёзҡ„ж¶ҲжҒҜйҳҹеҲ—е’Ңеҗ„з§ҚеӯҳеӮЁеҰӮ DruidгҖҒHBase йғҪиҝӣиЎҢдәҶжү“йҖҡпјҢз”ЁжҲ·ж–№еҸӘйңҖиҰҒжһ„е»әдёҖдёӘ source е°ұеҸҜд»Ҙе°ҶдёҠжёёжҲ–иҖ…дёӢжёёжҸҸиҝ°еҮәжқҘгҖӮ
еҶ…зҪ®ж¶ҲжҒҜж јејҸи§Јжһҗпјҡж¶Ҳиҙ№ж•°жҚ®еҗҺйңҖиҰҒе°Ҷж•°жҚ®иҝӣиЎҢжҸҗеҸ–пјҢдҪҶж•°жҚ®ж јејҸеҫҖеҫҖйқһеёёеӨҚжқӮпјҢеҰӮж•°жҚ®еә“ж—Ҙеҝ— binlogпјҢжҜҸдёӘз”ЁжҲ·еҚ•зӢ¬е®һзҺ°пјҢйҡҫеәҰиҫғеӨ§гҖӮStreamSQL е°ҶжҸҗеҸ–еә“еҗҚгҖҒиЎЁеҗҚгҖҒжҸҗеҸ–еҲ—зӯүеҮҪж•°еҶ…зҪ®пјҢз”ЁжҲ·еҸӘйңҖеҲӣе»ә binlog зұ»еһӢ sourceпјҢ并еҶ…зҪ®дәҶеҺ»йҮҚиғҪеҠӣгҖӮеҜ№дәҺ business log дёҡеҠЎж—Ҙеҝ— StreamSQL еҶ…зҪ®дәҶжҸҗеҸ–ж—Ҙеҝ—еӨҙпјҢжҸҗеҸ–дёҡеҠЎеӯ—ж®ө并组装жҲҗ Map зҡ„еҠҹиғҪгҖӮеҜ№дәҺ json ж•°жҚ®пјҢз”ЁжҲ·ж— йңҖиҮӘе®ҡд№ү UDFпјҢеҸӘйңҖйҖҡиҝҮ jsonPath жҢҮе®ҡжүҖйңҖеӯ—ж®өгҖӮ
жү©еұ•UDXпјҡдё°еҜҢеҶ…зҪ® UDXпјҢеҰӮеҜ№ JSONгҖҒMAP иҝӣиЎҢдәҶжү©еұ•пјҢиҝҷдәӣеңЁж»ҙж»ҙдёҡеҠЎдҪҝз”ЁеңәжҷҜдёӯиҫғеӨҡгҖӮж”ҜжҢҒиҮӘе®ҡд№ү UDXпјҢз”ЁжҲ·иҮӘе®ҡд№ү UDF 并дҪҝз”Ё jar еҢ…еҚіеҸҜгҖӮе…је®№ Hive UDXпјҢдҫӢеҰӮз”ЁжҲ·еҺҹжқҘжҳҜдёҖдёӘ Hive SQL д»»еҠЎпјҢеҲҷиҪ¬жҚўжҲҗе®һж—¶д»»еҠЎдёҚйңҖиҰҒиҫғеӨҡж”№еҠЁпјҢжңүеҠ©дәҺжү№жөҒдёҖдҪ“еҢ–гҖӮ
Join иғҪеҠӣжү©еұ•пјҡ
еҹәдәҺ TTL зҡ„еҸҢжөҒ joinпјҡеңЁж»ҙж»ҙзҡ„жөҒи®Ўз®—дёҡеҠЎдёӯжңүзҡ„ join ж“ҚдҪңж•°жҚ®еҜ№еә”зҡ„и·ЁеәҰжҜ”иҫғй•ҝпјҢдҫӢеҰӮйЎәйЈҺиҪҰдёҡеҠЎеҸ‘еҚ•еҲ°жҺҘеҚ•зҡ„ж—¶й—ҙи·ЁеәҰеҸҜиғҪиҫҫеҲ°дёҖдёӘжҳҹжңҹе·ҰеҸіпјҢеҰӮжһңиҝҷдәӣж•°жҚ®зҡ„ join еҹәдәҺеҶ…еӯҳж“ҚдҪң并дёҚеҸҜиЎҢпјҢйҖҡеёёе°Ҷ join ж•°жҚ®ж”ҫеңЁзҠ¶жҖҒдёӯпјҢзӘ—еҸЈйҖҡиҝҮ TTL е®һзҺ°пјҢиҝҮжңҹиҮӘеҠЁжё…зҗҶгҖӮ
з»ҙиЎЁ join иғҪеҠӣпјҡз»ҙиЎЁж”ҜжҢҒ HBaseгҖҒKVStoreгҖҒMysql зӯүпјҢеҗҢж—¶ж”ҜжҢҒ innerгҖҒleftгҖҒrightгҖҒfull join зӯүеӨҡз§Қж–№ејҸгҖӮ
гҖҗ дёҡеҠЎ|ж»ҙж»ҙеҹәдәҺ Flink зҡ„е®һж—¶ж•°д»“е»әи®ҫе®һи·өгҖ‘4.2 еҹәдәҺж•°жҚ®жўҰе·ҘеҺӮзҡ„ StreamSQL IDE е’Ңд»»еҠЎиҝҗз»ҙ
StreamSQL IDEпјҡ
жҸҗдҫӣеёёз”Ёзҡ„SQLжЁЎжқҝпјҡеңЁејҖеҸ‘жөҒејҸ SQL ж—¶дёҚйңҖиҰҒд»Һйӣ¶ејҖе§ӢпјҢеҸӘйңҖиҰҒйҖүжӢ©дёҖдёӘ SQL жЁЎжқҝпјҢ并еңЁиҝҷдёӘжЁЎжқҝд№ӢдёҠиҝӣиЎҢдҝ®дҝ®ж”№ж”№еҚіеҸҜиҫҫеҲ°жңҹжңӣзҡ„з»“жһң
жҸҗдҫӣ UDF зҡ„еә“пјҡзӣёеҪ“дәҺдёҖдёӘеә“еҰӮжһңдёҚзҹҘйҒ“е…·жңүд»Җд№Ҳеҗ«д№үд»ҘеҸҠеҰӮдҪ•дҪҝз”ЁпјҢз”ЁжҲ·еҸӘйңҖиҰҒеңЁ IDE дёҠжҗңзҙўеҲ°иҝҷдёӘеә“пјҢе°ұиғҪеӨҹжүҫеҲ°дҪҝз”ЁиҜҙжҳҺд»ҘеҸҠдҪҝз”ЁжЎҲдҫӢпјҢжҸҗдҫӣиҜӯжі•жЈҖжөӢдёҺжҷәиғҪжҸҗзӨә
жҸҗдҫӣд»Јз ҒеңЁзәҝDEBUGиғҪеҠӣпјҡеҸҜд»ҘдёҠдј жң¬ең°жөӢиҜ•ж•°жҚ®жҲ–иҖ…йҮҮж ·е°‘йҮҸ Kafka зӯү source ж•°жҚ® debugпјҢжӯӨеҠҹиғҪеҜ№жөҒи®Ўз®—д»»еҠЎйқһеёёйҮҚиҰҒгҖӮжҸҗдҫӣзүҲжң¬з®ЎзҗҶеҠҹиғҪпјҢеҸҜд»ҘеңЁдёҡеҠЎзүҲжң¬дёҚж–ӯеҚҮзә§иҝҮзЁӢдёӯпјҢжҸҗдҫӣд»»еҠЎеӣһйҖҖеҠҹиғҪгҖӮ
д»»еҠЎиҝҗз»ҙпјҡд»»еҠЎиҝҗз»ҙдё»иҰҒеҲҶдёәеӣӣдёӘж–№йқў
ж—Ҙеҝ—жЈҖзҙўпјҡFlink UI дёҠжҹҘиҜўж—Ҙеҝ—дҪ“йӘҢйқһеёёзіҹзі•пјҢж»ҙж»ҙе°Ҷ Flink д»»еҠЎж—Ҙеҝ—иҝӣиЎҢдәҶйҮҮйӣҶпјҢеӯҳеӮЁеңЁ ES дёӯпјҢйҖҡиҝҮ WEB еҢ–зҡ„з•ҢйқўиҝӣиЎҢжЈҖзҙўпјҢж–№дҫҝи°ғжҹҘгҖӮ
жҢҮж Үзӣ‘жҺ§пјҡFlink жҢҮж ҮиҫғеӨҡпјҢйҖҡиҝҮ Flink UI жҹҘзңӢдҪ“йӘҢзіҹзі•пјҢеӣ жӯӨж»ҙж»ҙжһ„е»әдәҶдёҖдёӘеӨ–йғЁзҡ„жҠҘиЎЁе№іеҸ°пјҢеҸҜд»ҘеҜ№жҢҮж ҮиҝӣиЎҢзӣ‘жҺ§гҖӮ
жҠҘиӯҰпјҡжҠҘиӯҰйңҖиҰҒеҒҡдёҖдёӘе№іиЎЎпјҢеҰӮйҮҚеҗҜжҠҘиӯҰжңүеӨҡзұ»еҰӮ пјҢйҖҡиҝҮи®ҫзҪ®дёҖеӨ©еҶ…еҚ•дёӘд»»еҠЎжҠҘиӯҰж¬Ўж•°йҳҲеҖјиҝӣиЎҢе№іиЎЎпјҢеҗҢж—¶д№ҹеҢ…жӢ¬еӯҳжҙ»жҠҘиӯҰ гҖҒ延иҝҹжҠҘиӯҰгҖҒйҮҚеҗҜжҠҘиӯҰе’Ң Checkpoint йў‘з№ҒеӨұиҙҘжҠҘиӯҰзӯүгҖӮ
иЎҖзјҳиҝҪиёӘпјҡе®һж—¶и®Ўз®—д»»еҠЎй“ҫи·Ҝиҫғй•ҝпјҢд»ҺйҮҮйӣҶеҲ°ж¶ҲжҒҜйҖҡйҒ“пјҢжөҒи®Ўз®—пјҢеҶҚеҲ°дёӢжёёзҡ„еӯҳеӮЁз»ҸеёёеҢ…жӢ¬ 4-5дёӘзҺҜиҠӮпјҢеҰӮжһңж— жі•е®һзҺ°иҝҪиёӘпјҢе®№жҳ“дә§з”ҹзҒҫйҡҫжҖ§зҡ„й—®йўҳгҖӮдҫӢеҰӮеҸ‘зҺ°жҹҗжөҒејҸд»»еҠЎжөҒйҮҸжҡҙж¶ЁеҗҺпјҢйңҖиҰҒе…ҲжҹҘзңӢе…¶ж¶Ҳиҙ№зҡ„ topic жҳҜеҗҰеўһеҠ пјҢtopic дёҠжёёйҮҮйӣҶжҳҜеҗҰеўһеҠ пјҢйҮҮйӣҶзҡ„ж•°жҚ®еә“ DB жҳҜеҗҰдә§з”ҹдёҚжҒ°еҪ“ең°жү№йҮҸж“ҚдҪңжҲ–иҖ…жҹҗдёӘдёҡеҠЎеңЁдёҚж–ӯеўһеҠ ж—Ҙеҝ—гҖӮиҝҷзұ»й—®йўҳйңҖиҰҒд»ҺдёӢжёёеҲ°дёҠжёёгҖҒд»ҺдёҠжёёеҲ°дёӢжёёеӨҡж–№еҗ‘зҡ„иЎҖзјҳиҝҪиёӘпјҢж–№дҫҝи°ғжҹҘеҺҹеӣ гҖӮ
жҺЁиҚҗйҳ…иҜ»





![[з»јиүәиҠӮзӣ®]ж—©еә”иҜҘиў«еҒңж’ӯзҡ„еҮ дёӘз»јиүәиҠӮзӣ®пјҢдёҚд»…еҶ…幕让дәәж°”ж„ӨпјҢз”ҡиҮіиҝҳиҜҜеҜјйқ’е°‘е№ҙ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/4d71220ab187d1a1594708332a467e22.jpg)









- иҙёжҳ“еҚҸи®®|иӢұеӣҪдёҺ欧зӣҹеҗҢж„ҸеҹәдәҺе…ұеҗҢеҲ©зӣҠиҫҫжҲҗвҖңеҫ®еһӢвҖқиҙёжҳ“еҚҸи®®
- зӣҙж’ӯ|ж–ӯеӨ–й“ҫ гҖҒвҖңжү¶вҖқе°Ҹеә—пјҢжҠ–йҹізӣҙж’ӯжүӣиө·з”өе•ҶдёҡеҠЎеӨ§ж——
- зҗҶжғі|дёҺж»ҙж»ҙеҗҲдҪңжҲ–жҗҒжө…пјҢзҗҶжғіиҰҒдёәдәҢиӮЎдёңзҫҺеӣўйҖ иҪҰпјҹ
- еҶҜжҸҗиҺ« |еҶҜжҸҗиҺ«дёҡеҠЎиғҪеҠӣжңүеӨҡејәпјҹеҸ‘еёғдјҡзҺ°еңәзҢңжӯҢпјҢиў«иӘүдёәдёӯеҚҺе°ҸжӣІеә“
- иЎҘиҙҙ|йҒӯзҷҫеәҰгҖҒеҳҖе—’еӣҙж”»пјҢз„Ұиҷ‘зҡ„ж»ҙж»ҙеҸ‘вҖңзҷҫдәҝиЎҘиҙҙвҖқжұӮеўһй•ҝ
- з»ҳз”»|жұүзҺӢ科жҠҖзҲҶеҸ‘пјҢж•ҙеҗҲз»ҳз”»дёҡеҠЎеҗҺеҮҖеҲ©йў„еўһ6еҖҚпјҢеј•жҠ•иө„иҖ…еҜҶйӣҶи°ғз ”
- йҮ‘иһҚ|马дёҠж¶Ҳиҙ№йҮ‘иһҚдёҠеёӮиҺ·жү№пјҢжј«йҒ“йҮ‘жңҚж——дёӢе®қд»ҳеҠ©еҠӣжҢҒзүҢж¶ҲйҮ‘дёҡеҠЎеўһй•ҝ
- е№ҝдҝЎ|е№ҝдҝЎжқҗж–ҷпјҡPCBжІ№еўЁдёҡеҠЎзӯ‘ж №еҹәпјҢе…үеҲ»иғ¶з ”еҸ‘з»ҲиҺ·зӘҒз ҙ
- иҪҰеұ•|еҹәдәҺCMF-EVе№іеҸ° йӣ·иҜәзәҜз”өSUVжҰӮеҝөиҪҰе°ҶеңЁдёӢе‘Ёдә®зӣё
- з»ҸйӘҢж•ҷзЁӢ|K12е•ҶеӯҰйҷўпјҡе°Ҹй№…йҖҡеҠ©еҠӣжҲ‘зҡ„дёҡеҠЎд»Һ1еҲ°100