年丰绩|百度大脑十年丰绩:6.0全新发布,具备认知能力终端虚拟人亮相( 二 )
「飞桨正在作为中国智能经济的基础底座 , 对外输出产业智能化升级转型的强大推动力 。 」王海峰说道 。
最近 , 飞桨也经历了大幅度的升级 , 其范围覆盖动态图和 API 体系 , 一些核心技术也有了新的突破 。 其迎来了「动静统一、软硬融合」的升级:已适配 22 种芯片型号 , 覆盖 15 家硬件厂商 , 对国产硬件的支持业内第一 , 范围超过 TensorFlow 和 PyTorch 。

文章图片
在动态图转静态图方面 , 飞桨现在已经支持完备的语法覆盖和带控制流的任务 , 仅需一个装饰器就可以触发操作 , 统一的接口可以让模型保存加载实现自动适配 。
在动态图上 , 飞桨提供了比静态图更简洁灵活的混合精度训练接口 , 并且实现媲美静态图的混合精度与量化训练效果 。 以 ResNet 训练为例 , FP 使用混合精度训练 , 比 FP32 方式速度提升了 2.7 倍 。 动态图还支持量化 , 在 MobileNet , ResNet 等动态图模型的任务中 , 在保持精度不变的情况下 , 仅占 FP32 体积的 1/4 。
飞桨的 API 体系也在全面升级 。 据介绍 , 飞桨形成了贴合用户使用习惯的全新 API 体系 , 包括包结构、API 规范、共性问题优化等 , 面对用户更加友好 。 为了减少开发者的工作量 , 飞桨可以提供包含视觉、NLP 等领域的模型和工具封装的高层 API , 以及最经典的模型结构 。
语音交互 , 日均调用量超 155 亿次
在语音识别领域 , 百度推出了端到端信号声学一体化建模的技术 。 语音合成方面 , 最新的 Meitron(语音风格迁移)和单人千面合成个性化技术亮相 。
个性化 TTS 是个性化定制的 Meitron 语音合成系统的最新演进 , 是基于子带分解和 GAN_loss 的端侧神经网络声码器 , 也是业内首个在手机端多人通用的端侧的基于神经计算的声码器 。 个性化 TTS 相较于传统的基于信号处理和参数的声码器 , ABS 提升可以达到 65:35 , 其已应用于地图导航 , 目前每日的导航播报超过 1 亿次 。
多角色的语音合成 , 则是针对娱乐内容产业存在的挑战 。 在制作小说有声读物等任务中 , 多个角色交替出现 , 单一音色演绎会出现没有张力的问题 。 通过深度学习技术对小说文本进行分析 , AI 可以判断出文字中的角色、身份、情感 , 再借助多风格、多角色语音合成技术去合成小说中的声音 , 从而实现声音自然、体验优美的效果 。
百度在大会上还交出了语音技术的最新成绩单:日均调用量超过 155 亿次 , 广泛应用在移动端、智能家居、和语音 IoT 等场景 。
全球最大知识图谱的再次升级
百度拥有目前全球最大的知识图谱 , 其中包含超过 50 亿实体、5500 亿事实 , 日均调用量超 400 亿 。 百度的知识中台现在向企业提供了面向知识应用全生命周期的一站式解决方案 , 其知识图谱产品目前已覆盖 100 多个行业场景 。
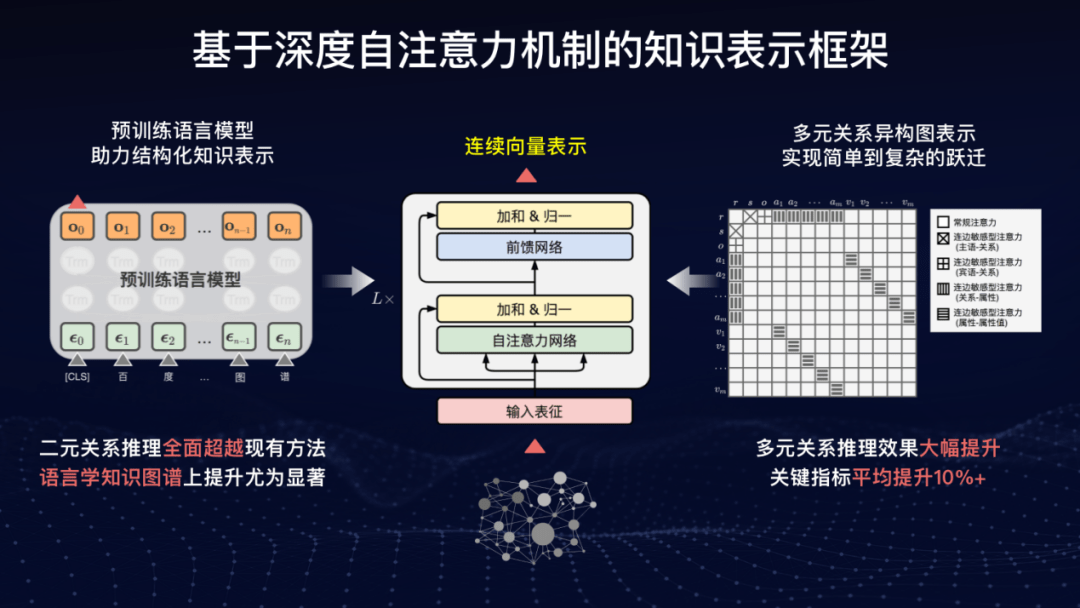
最近 , 这个知识图谱也有了全新升级 。 在通用图谱方面 , 百度提出了基于深度自注意力机制的知识表示框架 , 通过深度自注意力网络对知识图谱中的实体和关系进行连续向量表示 , 在此基础上 , 进一步引入预训练语言模型助力结构化知识表示 , 二元关系推理能力全面超越现有方法 , 语言学知识图谱上提升尤为显著 。
利用多元关系异构图表示 , 百度还实现了简单知识表示到复杂知识表示的跃迁 , 多元关系推理效果大幅提升 , 关键指标平均提升 10%+ 。
文章图片
在关系抽取技术上 , 百度研究人员提出了基于文本图谱联合预训练的关系抽取 , 通过联合文本语境与图谱路径 , 共同推断实体间的语义关系 , 从而大幅提升了关系抽取效果 。
在事件图谱方面 , 百度已经形成了事件检测、事件表示、事件抽取、事件关系挖掘等核心能力 , 可实现分钟级检测热点、构建了包含 4000 多种事件类型、千万量级的事件库 , 并发布了业界规模最大的中文事件抽取数据集 DuEE 。
除此之外 , 百度还研发了事理图谱 , 并升级了多模态语义理解技术 。
语义理解框架文心(ERNIE)
在预训练模型火热的 NLP 领域里 , 百度提出的知识增强语义理解框架文心(ERNIE)最近一直被人们所关注 。 它以知识增强和持续学习为核心创新点 , 在深度学习的基础上融入了知识 , 通过持续学习技术不断吸收海量数据中的词汇、结构、语义等方面的知识 。 此前 , 文心在最具影响力的 NLP 评测基准 GLUE 上刷新了不少业内最佳水平记录 。
目前 , 文心已经实现了基于知识增强的跨模态深度语义理解 。 通过知识关联多模态信息 , AI 模型可以使用语言描述不同模态信息的语义 , 让机器实现从「看清」到「看懂」、「听清」到「听懂」 , 即图像和语言、语音和语言的一体化理解 。
这种能力被百度称为「知识增强的跨模态深度语义理解」 , 它让机器能够听懂语音、看懂图像视频、理解语言 , 进而理解真实世界 , 并与人进行更好的交流 。
推荐阅读








![[献血]一腔热血献战“疫”!一五七医院百名医务人员献血](https://pic.nfapp.southcn.com/nfplus/ossfs/pic/xy/202003/01/9be8b43769df49fc8633a2d28e383f6b_zsize_b)





- 大脑|12岁的“最强大脑”,孙奕东妈妈自曝育儿经,普通家长都可复制
- 补贴|遭百度、嘀嗒围攻,焦虑的滴滴发“百亿补贴”求增长
- 功能|手写方式只适合父母一辈?试试百度输入法,你会彻底改变想法
- Apollo|@所有北京市民,百度Apollo上线的这份出行福利请查收!
- 搜索|百度精神卫生日搜索大数据:疫情冲击实体行业 今年餐饮业者心理压力增长最明显
- 搜索|百度在搜索结果引入抑郁症自测服务
- 下水|百度变阵,新“船”下水
- 服务|服务订单量同比增长266% 百度服务能力顶住国庆大考
- 广告|重拳出击违规广告,百度一直坚守的隐秘战场
- 科研|AI云平台 为教育科研装上数字大脑