「机器学习」截取caffe模型中的某层
通常情况下 , 训练好的caffe模型包含两个文件:
- prototxt:网络结构描述文件 , 存储了整个网络的图结构;
- caffemodel:权重文件 , 存储了模型权重的相关参数和具体信息
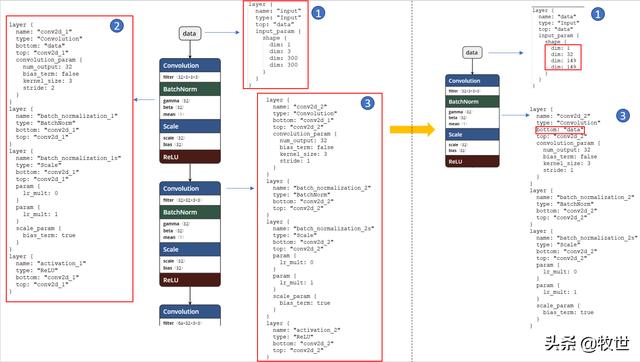
修改prototxt以Inception模型为例 , 如下图左则为使用Netron可视化的模型前3层及prototxt描述的内容 , 假设要截取第3层 , 修改后的模型如下图右则所示 , 修改方法为:
- 修改输入数据的维度为第2层的输出维度
- 删除第2层以及第3层后的所有层
- 修改第3层的bottom值为第一层的top值
 文章插图
文章插图截取权重数据首先要下载caffe源码
git clone 然后使用caffe的python接口读取修改后的prototxt和原始的权重文件caffemodel , 接着重新推理 , 最后保存新的权重文件 。【「机器学习」截取caffe模型中的某层】
import syscaffe_root='/your/path/caffe'sys.path.insert(0, caffe_root + '/python')import caffenet = caffe.Net("Inception.prototxt", "Inception.caffemodel", caffe.TRAIN)res = net.forward()net.save('Inception_conv2d_2.caffemodel')
推荐阅读
















- 唐山四维智能科技有限公司:双臂机器人引领人机协作新纪元
- 计算机专业大一下学期,该选择学习Java还是Python
- 大众展示EV公共充电新解决方案:移动充电机器人
- 普渡机器人获最佳商用服务机器人奖
- 翻译|机器翻译能达60个语种3000个方向,近日又夺全球五冠,这家牛企是谁?
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 我国首次给四个新职业定标