开启Scrapy爬虫之路!听说你scrapy都不会用?( 二 )
# 和fetch类似都是查看spider看到的是否和你看到的一致 , 便于排错scrapy view 12- version
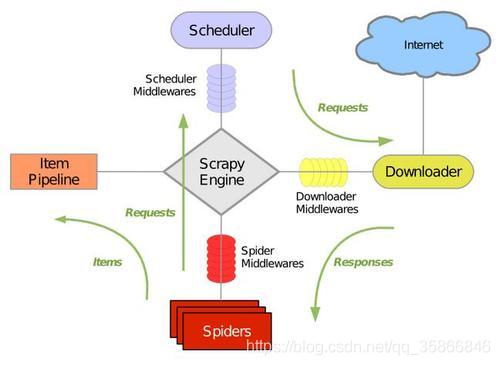
# 查看scrapy版本scrapy version122.2项目命令项目命令比较简单 , 感觉没什么好说的,我也没怎么详细测试 , 直接参考这篇【scrapy 命令行:scrpay项目命令】3.scrapy框架介绍Scrapy 是一个用python写的Crawler Framework,简单轻巧 , 并且十分方便 , 使用Twisted这个一部网络库来处理网络通信 , 架构清晰 , 并包含了各种中间件接口 , 可以灵活地完成各种需求 , 整体架构组成如下图
 文章插图
文章插图- Scrapy引擎(Engine): 引擎负责控制数据流在系统的所有组件中流动 , 并在相应动作发生时触发事件;
- 调度器(Scheduler): 调度器从引擎接收request 并将他们入队 , 以便之后引擎请求request时提供引擎;
- 下载器(Downloader): 下载器负责获取页面数据并提供给引擎 , 而后提供给Spider;
- Spider: Spider是Scrapy用户编写用于分析Response 并提取Item(即获取到的Item)或额外跟进的URL的类,每个Spider负责处理一个特定(或一些)网站
- Item Pipeline: Item Pipeline 负责处理被Spider提取出来的Item .典型的处理有清理验证及持久化(例如存储到数据库中);
- 下载器中间件(Downloader middlewares): 下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response 。 其提供了一个简单的机制 , 通过插入自定义代码来扩展Scrapy功能;
- Spider中间件(Spider middlwares): Spider中间件是在引擎及Spider之间的特定钩子(specific hook), 处理Spider的输入(response)和输出(items 及request)其中提供了一个简便的机制 , 通过插入自定义代码来实现Scrapy功能 。
- 引擎打开一个网站(open a domain),找到处理该网站的Spider 并向该Spider请求第一个要爬取的URL
- 引擎从Spider中获取第一个要爬取的URL并通过调度器(Schedule)以Request进行调度
- 引擎向调度器请求下一个要爬取的URL
- 调度器返回下一个要爬取的URL给引擎 , 引擎降URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)
- 一旦页面下载完毕 , 下载器生成一个该页面的Response , 并将其通过下载中间件(返回(response)方向)发送给引擎
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎
- 引擎将(Spider返回的)爬取到的Item 给Item Pipeline,将(Spider返回的)Request给调度器
- (从第二步)重复直到调度器中没有更多的Request , 引擎关闭网站
5.1创建项目
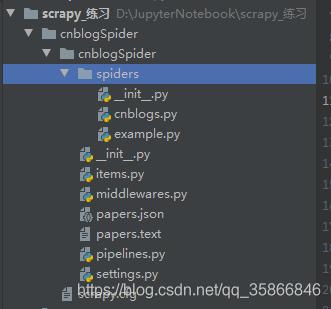
# 创建一个名为cnblogSpider 的Scrapy项目scrapy startproject cnblogSpider12 文章插图
文章插图创建好项目之后 , 直接使用pycharm打开 , 继续工作即可结构性文件自动生成 , 把框架填充起来即可
 文章插图
文章插图- scrapy.cfg: 项目部署文件
- cnblogSpider/ : 给项目的python模块 , 之后可以在此加入代码
推荐阅读
- OriginOS for iQOO首秀 iQOO六款机型开启公测招募
- 虾米音乐播放器将于2月5日停止服务,今开启用户资产处理通道
- 集录音转写、拍照翻译为一体,搜狗AI录音笔E2带你开启智慧办公新体验
- 太火爆!OriginOS将于1月13日开启第二轮公测招募
- 华为开启“暴走”模式!三个大动作同时展开,国产芯片将迎来破冰
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 或使用天玑1000+芯片?荣耀V40已全渠道开启预约
- 担心手机丢失,被盗刷?所有手机请马上开启这个功能
- 腾讯|以松江为起点和支点,腾讯“牵手”长三角G60科创走廊,开启合作新“朋友圈”
- 虾米音乐宣布关停:今日停止会员充值,开启个人资料处理通道












