Mysql不止CRUD,聊聊索引( 七 )
回到顶部
三、索引实现的原理innodb存储的索引是基于B+树实现的 , 从1.1节中的表格可以看出 , 不支持hash的实现方式 。 首先来了解下B+树的特点;
B+树的特征:
- 有k个子树的中间节点包含有k个元素(B树中是k-1个元素) , 每个元素不保存数据 , 只用来索引 , 所有数据都保存在叶子节点 。
- 所有的叶子结点中包含了全部元素的信息 , 即指向含这些元素记录的指针 , 且叶子结点本身依关键字的大小自小而大顺序链接 。
- 所有的中间节点元素都同时存在于子节点 , 在子节点元素中是最大(或最小)元素 。
- 单一节点存储更多的元素 , 使得查询的IO次数更少 。
- 所有查询都要查找到叶子节点 , 查询性能稳定 。
- 所有叶子节点形成有序链表 , 便于范围查询 。
 文章插图
文章插图索引的设计思考:
- 索引是一种存储方式 , 最相关的硬件就是磁盘 , 索引磁盘的性能会直接影响到数据库的查询效率
- 磁盘的性能和读写的顺序有关 , 普通磁盘顺序读写比随机读写快很多 , 所以尽量避免随机读写 。
- 数据都是以行为单位一行一行的存储的 , 每一行都包括了所有的列 , 多行可以连续存储 。
- 每一行数据中 , 一般都有一个键 , 其他的列可以称为值 , 可以理解为键值对 。 innodb必须有唯一非空的主键 , 就是默认的键 。
- 在键值对中 , 键值可以排序 , 还可以组合键值 。
- 磁盘空间会划分为许多个大小相等的块或者页 , 一个页中可以存储多行数据 , 这样就可以符合磁盘的顺序读写 , 这样一次IO就可以读取很多数据到内存 , 可以减少磁盘IO 。
- 在一个页内 , 所有的数据可能会经常变动 , 并且大小也是相对固定的 , 所以内部通过链表或者数组管理 。
- 每个键值可以排序 , 所以在一个块内的所有数据也可以是有序的 , 这样通过二分法查找可以很快的在一个页内找到指定键对应的数据
- 一个页设计好之后 , 可以把页作为B+树的节点 , 通过页来承载数据 , 通过B+数来组织不同页之间的关系
- B+树的特点是在内节点存储键来提高搜索的性能 , 所以很自然的 , 内节点用来存储数据行的键 , 叶子节点存储所有数据行 , 可以很好的提升性能
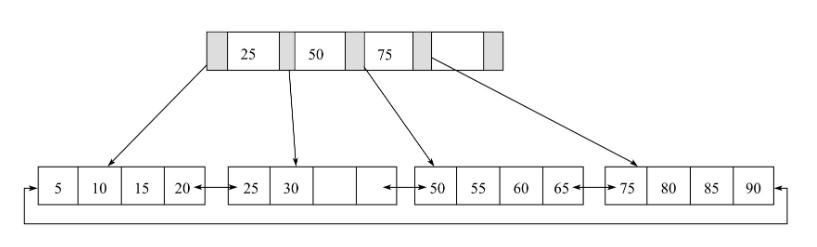
表中数据按照主键顺序存放 。 而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树 , 同时叶子节点中存放的即为整张表的行记录数据 , 也将聚集索引的叶子节点称为数据页 。 聚集索引的这个特性决定了索引组织表中数据也是索引的一部分 。 同B+树数据结构一样 , 每个数据页都通过一个双向链表来进行链接 。 如下图所示:
 文章插图
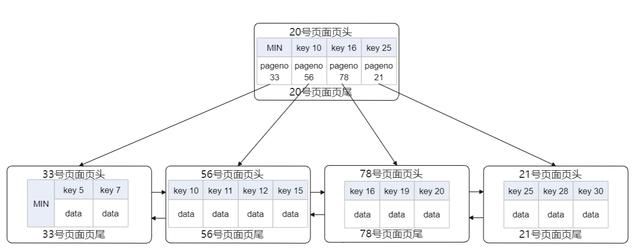
文章插图上图所示的是一个深度为2的B+树 , 也是我们所称的索引 , 这里假设页有随机唯一的编号 , 根页号为20 。 这里只有一个内节点(根节点) , 其他的都是叶子节点 , 也是数据节点 , 对于内节点来说 , 存有key和pageno的指针信息 , 对于叶子节点来说 , 只存有完整的数据 。 对于聚集索引 , data部分存有除主键外的其他列的组合 , 如果是二级索引 , 则这里存放就是这行记录对应主键的组合 , 用于回表 。
推荐阅读













- 小米无缘手机好评榜!不止小米11!看来卢伟冰有一句话说错了
- 不止有Mate40,另一张“底牌”也被曝光,华为也是迫不得已
- 不止业务合作而是“全面支持”获富士康支持拜腾“重回赛道”
- 打乱全球供应链!每年损失千亿?美对华芯片封锁的后果不止这些
- 华为P50战斗不止,6.1英寸小屏+联发科5nm芯片,支持吗
- 手机手电筒不止是能照明,其实还有很多隐藏功能
- 基于Spring+Angular9+MySQL开发平台
- 不止32核 苹果自研ARM芯片或将达到64核
- 手机行业将迎“变革”?华为P50消息流出,不止有鸿蒙
- 不止玩游戏!肯德基也要出主机:还能做烤鸡?