Linux(服务器编程):百万并发服务器系统参数调优( 八 )
原因分析
- 在第2次测试中 , 我们让服务端监听在5个端口上 , 这次错误的原因可能是因为所有分配端口可用的地址都用完了
- 调整服务端reactor.c程序的LISTEN_PORT_COUNT宏 , 使其监听在更多的端口上 , 这样就可以承载更多的客户端 。 例如 , 此处我们将LISTEN_PORT_COUNT宏调整为50
- 相应的 , 客户端mul_port_client_epoll.c中的MAX_PORT也要调整为50 , 因为要连接50种服务端
- 修改完成之后进行下面第5次测试
- 左侧运行服务端程序reactor(111.229.177.161:8888) , 右侧运行两个客户端程序mul_port_client_epoll去连接服务器
- 效果如下:
- 左侧服务端持续接收客户端的连接
- 右侧两个客户端向服务端发起连接 , 每个客户端都连接二十多万的时候程序阻塞(加起来就是五十多万)
- 左侧服务端接收到五十多万客户端的时候就阻塞了
 文章插图
文章插图原因分析
- 在第1次测试的时候 , 我们将服务端程序reactor.c中的MAX_EPOLL_EVENTS设置为1024*512=524288个 , 此处可以看到刚好服务端在接收到五十多万客户端的时候阻塞 。 因此分析应该是MAX_EPOLL_EVENTS宏达到上限 , 也就是epoll_wait()处理的事件数组达到上限
- 增加reactor.c中的MAX_EPOLL_EVENTS , 使其可以处理的epoll事件数组变多 , 例如修改为1024*1024=1048576个
- 因为第1次测试的时候 , 我们的MAX_EPOLL_EVENTS设置不能过大 , 如果过大程序运行时会显示内存不足 , 现在想到一个办法 , 那就是使用posix_memalign()函数来创建epoll的事件数组 , posix_memalign()函数是专门用来分配大内存的
- 修改完成之后下面进行第6次测试
- 下面我们不再测试了 , 也不再寻找客户端或服务端的错误 , 而是来分析一下如何使客户端更多的去连接服务端
- 在前面的测试中 , 我们的几台机器都是在局域网内的 , 每连接1000个客户端约耗时3秒 。 如果是在局域网之外 , 那么耗时更长
- 服务是调用accept()函数来接收客户端的连接的 , 因此如果想要加快客户端的连接 , 那么可以在accept()函数上下手
- 提供的思路有:
- 1.多个accept()放在一个线程中
- 2.多个accept()分配在不同的线程
- 3.多个accept()分配在不同的进程(Nginx为多进程服务器 , 它就是这样做的 , 每个进程都有自己独立的资源)
- 为什么多进程比多线程好:
- 1.多进程不需要加锁
- 2.多进程可以承载比多线程更多的fd , 因为每个进程都有自己一份独立的资源
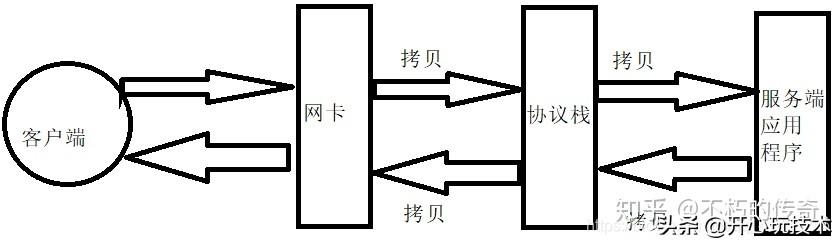
- 在服务器承载百万客户端的时候 , 这时候会有大量的数据在进行交互 。 对于默认的应用程序来说 , 其数据的传输都要经过协议栈缓冲区 , 如下图所示:
- 客户端发送数据到服务端时 , 数据先达到网卡 , 然后将数据拷贝到协议栈中 , 最后再把数据从协议栈中拷贝到服务端程序中
- 服务端回送数据时是相反的顺序 , 先把数据从服务端程序拷贝到协议栈 , 然后再把数据拷贝到网卡发送给客户端
 文章插图
文章插图- 从上图可以了解 , 当服务端与百万客户端数据交互的时候会带来下面的弊端:
推荐阅读
- Git服务器配置错误导致日产汽车源码在网上泄露
- 机器人|万州区举办“中国梦科技梦”机器人编程大赛
- Linux Kernel 5.10.5发布:禁用FBCON加速滚动特性
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- Fedora正在寻求协助 希望加快Linux 5.10 LTS内核测试进度
- Linux Mint 20.1 Ulyssa稳定版已确定延期至2021年初发布
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- MIPS架构厂商日渐式微 Linux报告其漏洞遭遇困难
- 手把手配置HLS流媒体服务器
- 2020年科技十大“翻车”现场:谷歌服务器真的有点累了……