PythonзҲ¬иҷ«з»ғд№ пјҡжӯЈеҲҷзҡ„иҝҗз”Ё( дәҢ )
2. иҝҗиЎҢз»“жһң
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёү. д»Јз ҒеҚҮзә§дёҠиҝ°д»Јз Ғ пјҢ жҲ‘们еҸӘиғҪзҲ¬еҸ–第дёҖдёӘзҡ„еҶ…е®№ пјҢ иҝҷе’ҢжҲ‘们жүҖжғізҡ„жҳҜжңүе·®еҲ«зҡ„ пјҢ жҲ‘们жғізҡ„жҳҜиҰҒзҲ¬еҸ–жүҖжңүйҖҡе‘Ҡ пјҢ иҝҷдёӘж—¶еҖҷдёҚз”ЁжғіжҲ‘们е°ұйңҖиҰҒйҖҡиҝҮжЁЎжӢҹзҝ»йЎөеҠЁдҪң пјҢ иҝӣиЎҢе…ЁйғЁиҺ·еҸ– гҖӮ
1. еҲҶжһҗ
жҲ‘们е…ҲжқҘйҖҡиҝҮжҹҘзңӢзҪ‘еқҖзҡ„еҸҳеҢ–д»ҘеҸҠжҹҘзңӢиғҪеҗҰзңӢеҲ°зҪ‘з«ҷзҡ„жҖ»йЎөж•° пјҢ еҘҪд»ҘжӯӨжқҘе®һзҺ°зҲ¬еҸ–е…ЁйғЁж Үйўҳзҡ„зӣ®зҡ„ гҖӮ
йҰ–е…ҲжҲ‘们е…ҲжқҘзңӢдёӢзҪ‘еқҖе·®ејӮпјҡ
;a5p=1a5p=2a5p=4 --tt-darkmode-color: #999999;">ж №жҚ®дёҠиҝ°дёүдёӘзҪ‘еқҖ пјҢ жҲ‘们дёҚйҡҫеҸ‘зҺ°зҪ‘еқҖе”ҜдёҖеҸҳеҢ–зҡ„ең°ж–№е°ұжҳҜ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йӮЈд№Ҳ пјҢ жҲ‘们е°ұеҸҜд»ҘйҖҡиҝҮжӢјжҺҘзҪ‘еқҖзҡ„ж–№ејҸе®һзҺ°зҪ‘йЎөи·іиҪ¬ гҖӮ
дёӢйқўжҲ‘们еҶҚжқҘжҹҘзңӢзҪ‘з«ҷжҖ»е…ұжңүеӨҡе°‘йЎөз Ғ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
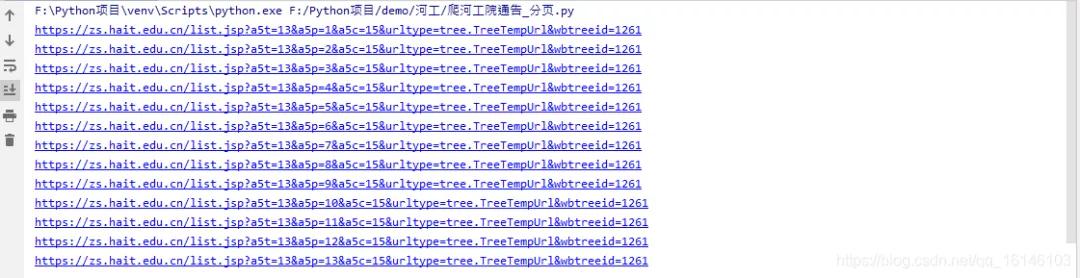
жҲ‘们еҸҜд»ҘзңӢеҲ°жҖ»е…ұжңү13йЎө пјҢ дёӢйқўе°ұеҫҲз®ҖеҚ•дәҶ пјҢ жҲ‘们е…ҲжқҘзңӢдёӢжӢјжҺҘзҡ„urlжҳҜеҗҰжҳҜжҲ‘们жүҖйңҖиҰҒзҡ„
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
2. жәҗз Ғ
йҖҡиҝҮдёҠеӣҫ пјҢ зңӢеҲ°urlжҳҜжҲ‘们жүҖйңҖиҰҒзҡ„ пјҢ дёӢйқўе°ұеҸҜд»Ҙе®Ңе–„дёҖејҖе§Ӣзҡ„д»Јз ҒдәҶпјҡ
# еҜје…ҘеҢ…import randomimport timeimport requestsimport reheaders = {"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",}base_url = ";a5p={}&a5c=15&urltype=tree.TreeTempUrl&wbtreeid=1261"def hegong_Spider():# зҝ»йЎөfor i in range(1, 14):print("第{}йЎөзҲ¬еҸ–дёӯ...".format(i))time.sleep(random.random())url = base_url.format(i)# еҸ‘йҖҒиҜ·жұӮ пјҢ иҺ·еҸ–е“Қеә”response = requests.get(url=url, headers=headers)# иҺ·еҸ–е“Қеә”ж•°жҚ®content = response.content.decode("utf-8")# жҸҗеҸ–ж•°жҚ® пјҢ дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸtitle_list = re.findall(r'.*?', content, flags=re.DOTALL)# title_list = content.xpath('//a[@class="c57797"]/@title').extract()# жү“ејҖж–Ү件еҶҷwith open("./жІіе·ҘйҷўйҖҡе‘Ҡ.txt", "a", encoding="utf-8") as file:# еҫӘзҺҜfor title in title_list:# еҶҷfile.write(title)file.write("\n")print("дҝқеӯҳе®ҢжҜ•пјҒ")if __name__ == '__main__':hegong_Spider()гҖҗPythonзҲ¬иҷ«з»ғд№ пјҡжӯЈеҲҷзҡ„иҝҗз”ЁгҖ‘3. иҝҗиЎҢз»“жһң
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»




![[еӯҷиҺү]24еІҒзҡ„й»„зЈҠдёәдҪ•дёҖзңјзңӢдёӯ18еІҒзҡ„еӯҷиҺүпјҢзңӢзңӢеӯҷиҺүйқ’涩照пјҢйҡҫжҖӘй»„зЈҠдёӢжүӢиҝҷд№Ҳеҝ«пјҒ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/upload/2020/f2e2862a6e6288774657db4b4eb97e5b.jpg)












- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- 2021е№ҙJavaе’ҢPythonзҡ„еә”з”Ёи¶ӢеҠҝдјҡжңүд»Җд№ҲеҸҳеҢ–пјҹ
- йқһи®Ўз®—жңәдё“дёҡзҡ„жң¬з§‘з”ҹпјҢжғіеҲ©з”ЁеҜ’еҒҮеӯҰд№ PythonпјҢиҜҘжҖҺд№Ҳе…ҘжүӢ
- з”ЁPythonеҲ¶дҪңеӣҫзүҮйӘҢиҜҒз ҒпјҢиҝҷдёүиЎҢд»Јз Ғе®ҢдәӢе„ҝ
- еҺҶж—¶ 1 дёӘжңҲпјҢеҒҡдәҶ 10 дёӘ Python еҸҜи§ҶеҢ–еҠЁеӣҫпјҢз”Ёеҝғдё”зІҫзҫҺ...
- дёәдҪ•еңЁдәәе·ҘжҷәиғҪз ”еҸ‘йўҶеҹҹPythonеә”з”ЁжҜ”иҫғеӨҡ
- еҜ№дәҺйқһи®Ўз®—жңәдё“дёҡзҡ„еҗҢеӯҰжқҘиҜҙпјҢиҜҘйҖүжӢ©еӯҰд№ PythonиҝҳжҳҜC
- еӯҰд№ е®ҢPythonд№ӢеҗҺпјҢеҰӮдҪ•еҗ‘дәәе·ҘжҷәиғҪйўҶеҹҹеҸ‘еұ•