Pandasзҡ„crosstabеҮҪж•°( дәҢ )
е°Ҫз®Ўе®ғжңүзӮ№й«ҳзә§ пјҢ дҪҶжҳҜеҪ“дҪ е°Ҷcrosstab()иЎЁдј йҖ’еҲ°seabornзҡ„зғӯеӣҫдёӯж—¶ пјҢ дҪ е°Ҷе……еҲҶеҲ©з”Ёcrosstab()иЎЁзҡ„дјҳзӮ№ гҖӮ и®©жҲ‘们еңЁзғӯеӣҫдёӯзңӢеҲ°дёҠиЎЁпјҡ
cross = pd.crosstab(index=diamonds['cut'],columns=diamonds['color'],values=diamonds['price'],aggfunc=np.mean).round(0)sns.heatmap(cross, cmap='rocket_r', annot=True, fmt='g');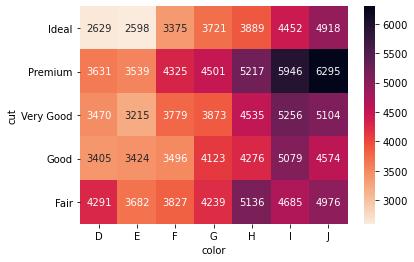 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
seabornеҸҜд»ҘиҮӘеҠЁе°Ҷcrosstab()иЎЁиҪ¬жҚўдёәзғӯеӣҫ гҖӮ жҲ‘е°ҶжіЁйҮҠи®ҫзҪ®дёәTrue пјҢ 并用йўңиүІжқЎжҳҫзӨәзғӯеӣҫ гҖӮ seabornиҝҳдёәеҲ—е’Ңзҙўеј•еҗҚж·»еҠ дәҶж ·ејҸ(fmt='g' е°Ҷж•°еӯ—жҳҫзӨәдёәж•ҙж•°иҖҢдёҚжҳҜ科еӯҰи®Ўж•°) гҖӮ
зғӯеӣҫжӣҙе®№жҳ“и§ЈйҮҠ гҖӮ дҪ дёҚжғіи®©дҪ зҡ„жңҖз»Ҳз”ЁжҲ·зңӢеҲ°дёҖеј ж»ЎжҳҜж•°еӯ—зҡ„иЎЁж ј гҖӮ еӣ жӯӨ пјҢ жҲ‘е°ҶеңЁйңҖиҰҒж—¶е°ҶжҜҸдёӘcrosstab()з»“жһңж”ҫе…Ҙзғӯеӣҫдёӯ гҖӮ дёәдәҶйҒҝе…ҚйҮҚеӨҚ пјҢ жҲ‘еҲӣе»әдәҶдёҖдёӘжңүз”Ёзҡ„еҮҪж•°пјҡ
def plot_heatmap(cross_table, fmt='g'):fig, ax = plt.subplots(figsize=(8, 5))sns.heatmap(cross_table,annot=True,fmt=fmt,cmap='rocket_r',linewidths=.5,ax=ax)plt.show();Pandas crosstab()дёҺpivot_table()е’Ңgroupby()зҡ„жҜ”иҫғеңЁжҲ‘们继з»ӯи®Ёи®әжӣҙжңүи¶Јзҡ„еҶ…е®№д№ӢеүҚ пјҢ жҲ‘жғіжҲ‘йңҖиҰҒжҫ„жё…и®Ўз®—еҲҶз»„ж‘ҳиҰҒз»ҹи®Ўзҡ„дёүдёӘеҮҪж•°д№Ӣй—ҙзҡ„еҢәеҲ« гҖӮ
жҲ‘еңЁжң¬ж–Үзҡ„第дёҖйғЁеҲҶд»Ӣз»ҚдәҶpivot_table()е’Ңgroupby()зҡ„еҢәеҲ« гҖӮ еҜ№дәҺcrosstab() пјҢ иҝҷдёүиҖ…д№Ӣй—ҙзҡ„еҢәеҲ«еңЁдәҺиҜӯжі•е’Ңз»“жһңзҡ„еҪўзҠ¶ гҖӮ и®©жҲ‘们дҪҝз”Ёиҝҷдёүз§Қж–№жі•и®Ўз®—пјҡ
# дҪҝз”Ё groupby()>>> diamonds.groupby(['cut', 'color'])['price'].mean().round(0)cutcolorIdealD2629.0E2598.0F3375.0G3721.0H3889.0I4452.0J4918.0PremiumD3631.0E3539.0F4325.0G4501.0H5217.0I5946.0J6295.0Very GoodD3470.0E3215.0F3779.0G3873.0H4535.0I5256.0J5104.0GoodD3405.0E3424.0F3496.0G4123.0H4276.0I5079.0J4574.0FairD4291.0E3682.0F3827.0G4239.0H5136.0I4685.0J4976.0Name: price, dtype: float64# дҪҝз”Ё pivot_table()diamonds.pivot_table(values='price',index='cut',columns='color',aggfunc=np.mean).round(0)# дҪҝз”Ё crosstab()pd.crosstab(index=diamonds['cut'],columns=diamonds['color'],values=diamonds['price'],aggfunc=np.mean).round(0) ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»ҘдёҠжҳҜpivot_tableзҡ„иҫ“еҮә
ж–Үз« жҸ’еӣҫ
д»ҘдёҠжҳҜcrosstabзҡ„иҫ“еҮә
жҲ‘жғідҪ е·Із»ҸзҹҘйҒ“дҪ жңҖе–ңж¬ўзҡ„дәҶ гҖӮ grouppy()иҝ”еӣһдёҖдёӘеәҸеҲ— пјҢ иҖҢеҸҰдёӨдёӘиҝ”еӣһзӣёеҗҢзҡ„ж•°жҚ®её§ гҖӮ дҪҶжҳҜ пјҢ еҸҜд»Ҙе°Ҷgroupbyзі»еҲ—иҪ¬жҚўдёәзӣёеҗҢзҡ„ж•°жҚ®её§ пјҢ еҰӮдёӢжүҖзӨәпјҡ
grouped = diamonds.groupby(['cut', 'color'])['price'].mean().round(0)grouped.unstack()ж–Үз« жҸ’еӣҫ
еҰӮжһңдҪ дёҚдәҶи§Јpivot_table()е’Ңunstack()зҡ„иҜӯжі• пјҢ жҲ‘ејәзғҲе»әи®®дҪ йҳ…иҜ»жң¬ж–Үзҡ„第дёҖйғЁеҲҶ гҖӮ
иҜҙеҲ°йҖҹеәҰ пјҢ crosstab()жҜ”pivot_table()еҝ« пјҢ дҪҶйғҪжҜ”groupby()ж…ўеҫ—еӨҡпјҡ
%%timeitdiamonds.pivot_table(values='price',index='cut',columns='color',aggfunc=np.mean)11.5 ms Вұ 483 Ојs per loop (mean Вұ std. dev. of 7 runs, 100 loops each)%%timeitpd.crosstab(index=diamonds['cut'],columns=diamonds['color'],values=diamonds['price'],aggfunc=np.mean)10.8 ms Вұ 344 Ојs per loop (mean Вұ std. dev. of 7 runs, 100 loops each)%%timeitdiamonds.groupby(['cut', 'color'])['price'].mean().unstack()4.13 ms Вұ 39.8 Ојs per loop (mean Вұ std. dev. of 7 runs, 100 loops each)
жҺЁиҚҗйҳ…иҜ»
















- дёҚеёёи§Ғзҡ„Pandasе°ҸзӘҚй—ЁпјҡжҲ‘жү“иөҢдёҖе®ҡжңүдҪ дёҚзҹҘйҒ“зҡ„
- countifеҮҪж•°зҡ„еӣӣз§ҚеҸҰзұ»з»Ҹе…ёз”Ёжі•пјҢжҲ‘дёҚиҜҙжІЎдәәе‘ҠиҜүдҪ
- Pandasзҡ„SettingWithCopyWarning
- и®©дәәеӨҙз—ӣзҡ„Generator еҮҪж•°зҡ„ејӮжӯҘеә”з”Ёзңҹзҡ„жңүз”Ёеҗ—пјҹ
- PowerQuery иЎЁиҫҫејҸи®Ўз®—еҮҪдёӯи°ғз”Ёе…¶д»–еҮҪж•°зҡ„ж–№жі•
- Pythonдёӯж–ҮйҖҹжҹҘиЎЁ-Pandas еҹәзЎҖ
- Pandasж•ҷзЁӢ
- еҮҪж•°йҖёй—»д№ӢеӨ§е°ҸеҶҷ
- JavaеҮҪж•°ејҸзј–з Ғз»“жһ„-еҘҪзЁӢеәҸе‘ҳ
- Pythonж•°жҚ®еӨ„зҗҶпјҢpandas з»ҹи®Ўиҝһз»ӯеҒңиҪҰж—¶й•ҝ