清华大学黄高——图像数据的语义层扩增方法( 二 )
 文章插图
文章插图
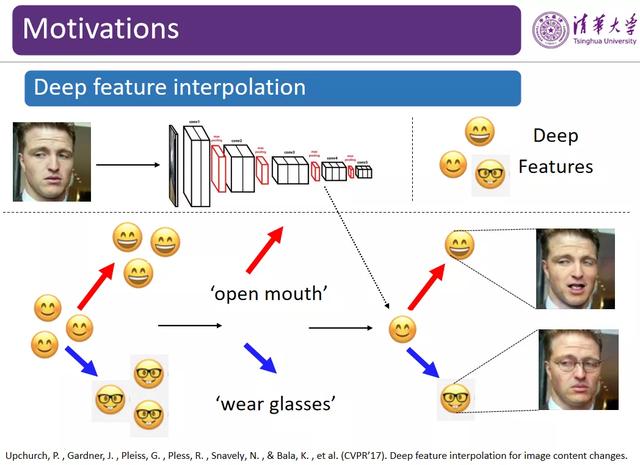
图 5:深度特征插值
因此 , 我们试图设计更高效的语义数据增强方法 。 在计算机视觉顶级会议 CVPR 2017 上有一篇论文「Deep feature interpolation for image content changes」中 , 作者认为经过卷积神经网络的特征提取之后 , 样本将会在特征空间中被线性化 , 也就是说 , 在神经网络的特征空间中每一个方向都代表特定的语义 。 以人脸图像特征为例 , 某一个方向可能对应于人脸表情从不笑到笑 , 另一个方向对应于人脸从戴眼镜到不戴眼镜 。 这篇文章的作者提出了一种名为「深度特征插值」的方法 , 如图 5 所示 , 假设在特征空间中 , 我们有一些正常人脸、微笑人脸、张嘴笑人脸、戴眼镜人脸的特征 , 可以沿着红色箭头的方向从微笑人脸的特征变化到张口笑人脸的的特征 , 该方向就代表张开嘴的语义;类似地 , 蓝色箭头的方向代表戴眼镜的语义 。 根据该假设 , 如果我们将某张普通人脸图像映射到特征空间中 , 并且将其特征与红色方向的向量相加 , 再基于语义增强后的特征重构图像 , 就会得到一个张嘴笑的人脸;同样 , 如果将普通人脸的特征与蓝色向量相加 , 就会得到戴眼镜的人脸图像 。 受到该论文的启发 , 黄高博士团队试图通过在深度特征空间中将原始图像的特征与一些方向上的向量相加 , 从而在不改变图像属性和标签的情况下 , 根据一张图像扩展出多个不同版本的图像 , 达到数据扩增的目的 。
隐式语义数据扩增
 文章插图
文章插图
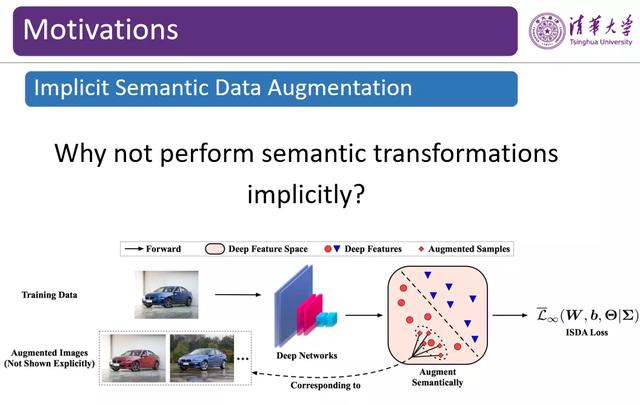
图 6:隐式语义数据增强
在论文「Deep feature interpolation for image content changes」中 , 作者需要手动地在特征空间找出进行「深度特征插值」的方向 。 举例而言 , 作者可能会手动收集一些戴眼镜的人脸与不戴眼镜的人脸 , 找出这两类人脸变化的方向 , 将该方向上的向量应用到不同的样本上 , 为不戴眼镜的人脸戴上眼镜 。 然而 , 这一过程的工作量巨大 , 通过人类手动的方式也只能找到非常有限的方向 。 实际上 , 人脸、汽车等图像数据可能涉及各种各样的变换 , 通过手工的方式很难实现多样化的数据扩增 。 如何实现高效、多样化的数据扩增成为了一个挑战 。
 文章插图
文章插图
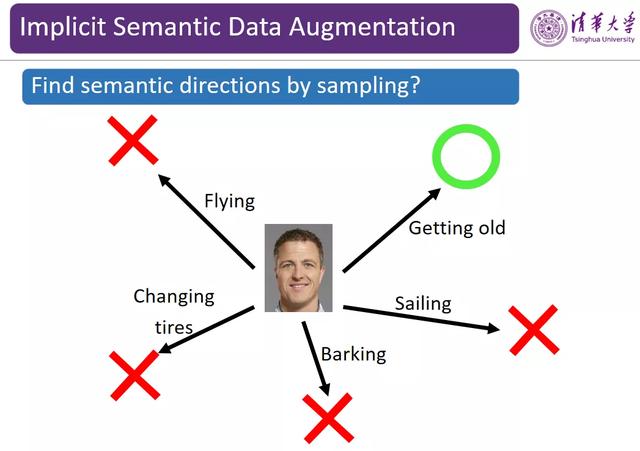
图 7:通过采样得到语义方向
为了实现上述目标 , 一个非常直观的思路是通过随机采样获得这种语义的方向 。 然而 , 我们需要明确从哪些方向进行采样 , 避免这些采样的方向没有实际的意义 。 例如 , 对一张人脸图像来说 , 我们通过采样得到一个方向可以使人脸变老、加上皱纹 , 这样的变换是有意义的 。 但是如果在人脸特征上加上飞翔方向的语义则没有任何意义 。 而如果我们直接在特征空间中进行随机采样 , 经常会采样得到这种没有意义的方向 。
 文章插图
文章插图
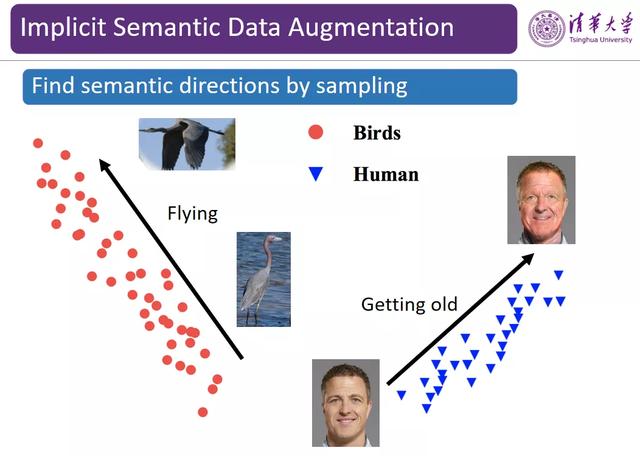
图 8:估计图像的分布
为了解决上述采样过程中的问题 , 我们试图估计每个类别图像的分布 。 如图 8 所示 , 红色样本组成的簇可能对应的图像类别是「鸟」 , 蓝色簇则对应的图像类别为「人」 , 实际上这种数据分布隐含了这类数据可能变化的方向 。 例如 , 红色的数据点在从左上到右下的方向上有方差 , 说明该方向上可能存在语义的变化 , 左上角可能是飞的鸟 , 右下角可能是站着的鸟 , 此时从左上到右下的方向是有意义的 。 类似地 , 对于蓝色的人脸数据来书哦 , 从左下到右上的方向可能对人脸图像是有意义的语义方向 。 在多维空间中 , 我们可以利用方差矩阵刻画某类图像可能在哪些方向上有语义的变化 。 因此 , 在采样过程中 , 我们并不是在所有方向上随机均衡地进行采样 , 而是先估计出数据的协同差矩阵 , 从而捕获每一类数据的方差的变化方向 。
推荐阅读


















- 苹果地图车正在以色列、新西兰和新加坡售价Look Around图像
- Caviar恳请撤回Galaxy S21 Ultra限量版图像 外媒对此感到不解
- “像”由“芯”生:中国打造自主高端图像传感器芯片
- 清华大学研究院出手!擦一次,持续24小时防雾,改变眼镜党体验
- Firefox 火狐浏览器将默认支持 AVIF 图像格式,教你在 84.0 版本开启
- Mozilla Firefox已经准备好默认启用AVIF图像处理支持
- 计算机基础:图形、图像相关知识笔记
- 清华大学这所研究院落地珠海!聚焦粤港澳大湾区智慧医疗发展
- Looking Glass Portrait相框开始预购 可以将图像转换成3D全息图显示
- 基于opencv图像处理对交通路口的红绿灯进行颜色检测