PPDet:减少Anchor-free目标检测中的标签噪声,小目标检测提升明显( 二 )
在本文中提出了一种anchor-free目标检测方法 , 该方法放宽了正样本标签策略 , 使模型能够减少训练时非判别性特征的贡献 。
同时 , 根据这种训练策略 , 检测器采用了一种推理方法 , 使得其中高度重叠的预测相互强制 。
 文章插图
文章插图
图1:PPDet的三个样本检测 , 从左到右分别是冲浪板 , 笔记本电脑和球拍 。 彩色圆点显示了将其预测汇总在一起以生成最终检测结果的位置 , 显示在绿色边框中 。 颜色表示贡献权重 。 最高贡献来自目标对象 , 而不是遮挡物或背景区域 。
本文的方法在训练过程中 , 在ground truth(GT)框内定义了一个“正区域” , 该区域与GT框具有相同的形状和中心 , 并且作者通过实验调整了相对于GT框的正区域的大小 。 由于这是一种anchor-free方法 , 因此每个特征(即最终特征图中的位置)都可以预测类别概率矢量和边界框坐标 。
来自GT框正区域的分类预测汇总在一起 , 并作为单个预测对损失做出了贡献 。 由于在训练过程中来自非目标区域(背景或被遮挡区域)的特征和非判别行特征的贡献会自动降低 , 因此这种总和缓解了上面提到的“噪声标签”问题 。
模型推理时 , 高度重叠的框的类别概率再次被合并在一起以获得最终的类别概率 。 方法最终命名为“ PPDet” , 它是“prediction pooling detector”的缩写 。
本文工作的贡献有两个方面:
1、设计了一个宽松的标签策略 , 它允许模型在训练过程中减少非判别性特征的贡献;
2、提出一个新的目标检测方法:PPDet , 它使用这个宽松的策略进行训练 , 并使用了一个新的基于预测池(prediction pooling)的推理方法 。
在COCO数据集上 , PPDet优于所有自上而下的anchor-free检测器 , 并且与其他最先进的方法表现相当 。
特别的 , PPDet对于检测小物体尤其有效 。
2 本文方法
1、Labeling strategy and training
Anchor-free检测器通过根据GT框的尺度大小或目标回归距离将其分配到适当的FPN层级来限制GT框的预测 。 在本文中同样遵循基于尺度的分配策略 , 因为它是一种自然地将GT框与特征金字塔层级特性关联起来的方法 。
然后 , 为每个GT框构建两个不同的区域 , 将 "正区域 "定义为与GT框同中心且形状与GT框相同的区域 , 并通过实验设定 "正区域 "的大小 。
然后 , 将在空间上落在GT盒的 "正区域 "内的所有位置(即特征)识别为 "正(前景)"特征 , 其余为 "负(背景)"特征 , 这样 , 每个正向特征都被分配到包含它的GT框中 。
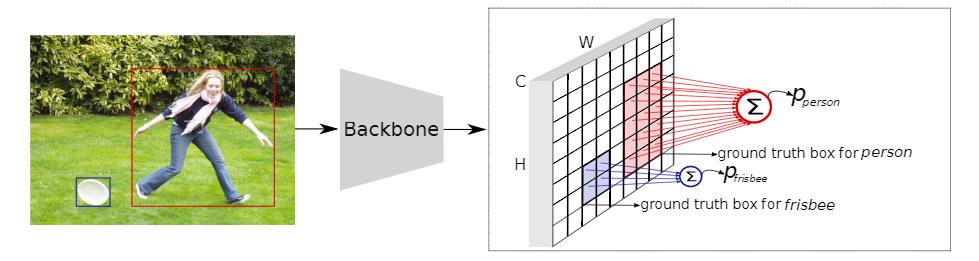 文章插图
文章插图
图2:PPDet训练期间的预测池predict pool 。 为简单起见 , 仅以单FPN层级进行说明 , 并且未显示边界框回归分支 。 蓝色和红色单元格是前景单元格 。 将相同颜色的前景单元(每个都是c维矢量)进行合并(即求和) , 以形成对应对象的最终预测得分 。 这些合并的得分被送到损失函数(Focal loss)中进行训练 。
在图2中 , 蓝色和红色的单元格代表正向特征 , 其余的(空的或白色的)是负向特征 。 蓝色特征被分配给飞盘(frisbee) , 红色特征被分配给人物(person) 。
为了得到一个目标实例的最终检测分数 , 本文将所有分配给该目标对象的特征的分类分数集中起来 , 将它们加在一起 , 得到一个最终的C维向量 , C表示目标的类别数 。 除了正向标记的特征外 , 其他特征都是负值特征 , 而每个负值特征对损失都有单独的贡献(即没有汇集) , 这个最终的预测向量被送入Focal Loss(FL) 。
默认情况下 , 将正特征分配给它们所在的框的目标实例 , 而此时 , 在不同GT框的相交区域中的特征分配是需要处理的问题 。 在这种情况下 , 本文的方法会将这些特征分配到距其中心距离最小的GT框中 。
推荐阅读

















- 减少八成二次包装 绿色快递年底可期
- 嗅觉AI:为减少食物浪费出点力
- 网站改版时如何减少网站的损失?
- 不顾240亿经济损失!意大利做出意外决定:将减少采购华为设备
- 手机充电“一整夜”,会不会减少电池寿命?维修老师傅这样回答
- 或与美国劝说有关?传意大利电信意外决定:计划减少华为设备份额
- 手机信号栏出现"HD",别不当回事儿,你的话费可能已经在减少
- 脑洞大开!印度推出牛粪“芯片”:声称能减少手机辐射预防疾病
- 麻烦一大堆!部分地区运营商下架4G套餐 种类减少办理渠道也在变窄
- 手机信号栏冒出“HD”,别不当回事儿,你的话费可能已经在减少