
ж–Үз« жҸ’еӣҫ
еӨҡеә“жӢҶеҲҶ
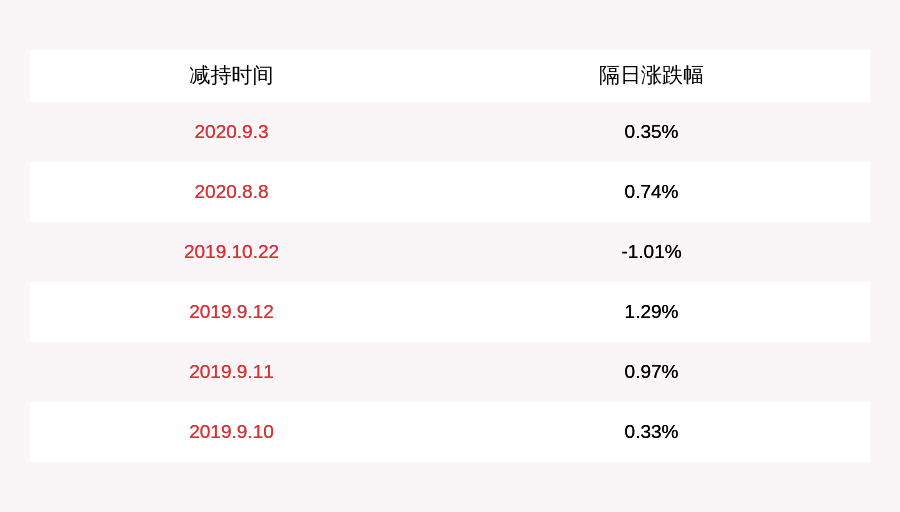
дёҖеҸҘиҜқжҖ»з»“пјҡеҲҶиЎЁдё»иҰҒжҳҜдёәдәҶеҮҸе°‘еҚ•еј иЎЁзҡ„еӨ§е°ҸпјҢи§ЈеҶіеҚ•иЎЁж•°жҚ®йҮҸеёҰжқҘзҡ„жҖ§иғҪй—®йўҳ гҖӮ
еҲҶеә“еҲҶиЎЁеёҰжқҘзҡ„еӨҚжқӮжҖ§
既然еҲҶеә“еҲҶиЎЁиҝҷд№ҲеҘҪпјҢйӮЈжҲ‘们жҳҜдёҚжҳҜеңЁйЎ№зӣ®еҲқжңҹе°ұеә”иҜҘйҮҮз”Ёиҝҷз§Қж–№жЎҲе‘ўпјҹдёҚиҰҒжҝҖеҠЁпјҢеҶ·йқҷдёҖдёӢпјҢеҲҶеә“еҲҶиЎЁзҡ„зЎ®и§ЈеҶідәҶеҫҲеӨҡй—®йўҳпјҢдҪҶжҳҜд№ҹз»ҷзі»з»ҹеёҰжқҘдәҶеҫҲеӨҡеӨҚжқӮжҖ§пјҢдёӢйқўз®ҖиҰҒиҜҙдёҖиҜҙ гҖӮ
и·Ёеә“е…іиҒ”жҹҘиҜў
еңЁеҚ•еә“жңӘжӢҶеҲҶиЎЁд№ӢеүҚпјҢжҲ‘们еҸҜд»ҘеҫҲж–№дҫҝдҪҝз”Ё join ж“ҚдҪңе…іиҒ”еӨҡеј иЎЁжҹҘиҜўж•°жҚ®пјҢдҪҶжҳҜз»ҸиҝҮеҲҶеә“еҲҶиЎЁеҗҺдёӨеј иЎЁеҸҜиғҪйғҪдёҚеңЁдёҖдёӘж•°жҚ®еә“дёӯпјҢеҰӮдҪ•дҪҝз”Ё join е‘ўпјҹ
жңүеҮ з§Қж–№жЎҲеҸҜд»Ҙи§ЈеҶіпјҡ
- еӯ—ж®өеҶ—дҪҷпјҡжҠҠйңҖиҰҒе…іиҒ”зҡ„еӯ—ж®өж”ҫе…Ҙдё»иЎЁдёӯпјҢйҒҝе…Қ join ж“ҚдҪңпјӣ
- ж•°жҚ®жҠҪиұЎпјҡйҖҡиҝҮETLзӯүе°Ҷж•°жҚ®жұҮеҗҲиҒҡйӣҶпјҢз”ҹжҲҗж–°зҡ„иЎЁпјӣ
- е…ЁеұҖиЎЁпјҡжҜ”еҰӮдёҖдәӣеҹәзЎҖиЎЁеҸҜд»ҘеңЁжҜҸдёӘж•°жҚ®еә“дёӯйғҪж”ҫдёҖд»Ҫпјӣ
- еә”з”ЁеұӮз»„иЈ…пјҡе°ҶеҹәзЎҖж•°жҚ®жҹҘеҮәжқҘпјҢйҖҡиҝҮеә”з”ЁзЁӢеәҸи®Ўз®—з»„иЈ…пјӣ
еҚ•ж•°жҚ®еә“еҸҜд»Ҙз”Ёжң¬ең°дәӢеҠЎжҗһе®ҡпјҢдҪҝз”ЁеӨҡж•°жҚ®еә“е°ұеҸӘиғҪйҖҡиҝҮеҲҶеёғејҸдәӢеҠЎи§ЈеҶідәҶ гҖӮ
еёёз”Ёи§ЈеҶіж–№жЎҲжңүпјҡеҹәдәҺеҸҜйқ ж¶ҲжҒҜпјҲMQпјүзҡ„и§ЈеҶіж–№жЎҲгҖҒдёӨйҳ¶ж®өдәӢеҠЎжҸҗдәӨгҖҒжҹ”жҖ§дәӢеҠЎзӯү гҖӮ
жҺ’еәҸгҖҒеҲҶйЎөгҖҒеҮҪж•°и®Ўз®—й—®йўҳ
еңЁдҪҝз”Ё SQL ж—¶ order byпјҢlimit зӯүе…ій”®еӯ—йңҖиҰҒзү№ж®ҠеӨ„зҗҶпјҢдёҖиҲ¬жқҘиҜҙйҮҮз”ЁеҲҶзүҮзҡ„жҖқи·Ҝпјҡ
е…ҲеңЁжҜҸдёӘеҲҶзүҮдёҠжү§иЎҢзӣёеә”зҡ„еҮҪж•°пјҢ然еҗҺе°Ҷеҗ„дёӘеҲҶзүҮзҡ„з»“жһңйӣҶиҝӣиЎҢжұҮжҖ»е’ҢеҶҚж¬Ўи®Ўз®—пјҢжңҖз»Ҳеҫ—еҲ°з»“жһң гҖӮ
еҲҶеёғејҸ ID
еҰӮжһңдҪҝз”Ё Mysql ж•°жҚ®еә“еңЁеҚ•еә“еҚ•иЎЁеҸҜд»ҘдҪҝз”Ё id иҮӘеўһдҪңдёәдё»й”®пјҢеҲҶеә“еҲҶиЎЁдәҶд№ӢеҗҺе°ұдёҚиЎҢдәҶпјҢдјҡеҮәзҺ°id йҮҚеӨҚ гҖӮ
еёёз”Ёзҡ„еҲҶеёғејҸ ID и§ЈеҶіж–№жЎҲжңүпјҡ
- UUID
- еҹәдәҺж•°жҚ®еә“иҮӘеҠЁеҚ•зӢ¬з»ҙжҠӨдёҖеј IDиЎЁ
- еҸ·ж®өжЁЎејҸ
- Redis зј“еӯҳ
- йӣӘиҠұз®—жі•пјҲSnowflakeпјү
- зҷҫеәҰuid-generator
- зҫҺеӣўLeaf
- ж»ҙж»ҙTinyid
еӨҡж•°жҚ®жәҗ
еҲҶеә“еҲҶиЎЁд№ӢеҗҺеҸҜиғҪдјҡйқўдёҙд»ҺеӨҡдёӘж•°жҚ®еә“жҲ–еӨҡдёӘеӯҗиЎЁдёӯиҺ·еҸ–ж•°жҚ®пјҢдёҖиҲ¬зҡ„и§ЈеҶіжҖқи·Ҝжңүпјҡе®ўжҲ·з«ҜйҖӮй…Қе’Ңд»ЈзҗҶеұӮйҖӮй…Қ гҖӮ
дёҡз•Ңеёёз”Ёзҡ„дёӯй—ҙ件жңүпјҡ
- shardingsphereпјҲеүҚиә« sharding-jdbcпјү
- Mycat
еҰӮжһңеҮәзҺ°ж•°жҚ®еә“й—®йўҳдёҚиҰҒзқҖжҖҘеҲҶеә“еҲҶиЎЁпјҢе…ҲзңӢдёҖдёӢдҪҝ用常规жүӢж®өжҳҜеҗҰиғҪеӨҹи§ЈеҶі гҖӮ
еҲҶеә“еҲҶиЎЁдјҡз»ҷзі»з»ҹеёҰжқҘе·ЁеӨ§зҡ„еӨҚжқӮжҖ§пјҢдёҚжҳҜдёҮдёҚеҫ—е·Іе»әи®®дёҚиҰҒжҸҗеүҚдҪҝз”Ё гҖӮдҪңдёәзі»з»ҹжһ¶жһ„еёҲеҸҜд»Ҙи®©зі»з»ҹзҒөжҙ»жҖ§е’ҢеҸҜжү©еұ•жҖ§ејәпјҢдҪҶжҳҜдёҚиҰҒиҝҮеәҰи®ҫи®Ўе’Ңи¶…еүҚи®ҫи®Ў гҖӮеңЁиҝҷдёҖзӮ№дёҠпјҢжһ¶жһ„еёҲдёҖе®ҡиҰҒжңүеүҚзһ»жҖ§пјҢжҸҗеүҚеҒҡеҘҪйў„еҲӨ гҖӮеӨ§е®¶еӯҰдјҡдәҶеҗ—пјҹ
гҖҗж•°жҚ®еә“пјҡжҲ‘йғҪеҝ«зҲҶдәҶпјҢдҪ дёәд»Җд№ҲиҝҳдёҚеҲҶеә“еҲҶиЎЁпјҹгҖ‘
жҺЁиҚҗйҳ…иҜ»













- 60иЎҢPythonд»Јз ҒиҪ»жқҫжҗһе®ҡж•°жҚ®еә“жҹҘиҜў 1з§’жүҫеҲ°йңҖиҰҒзҡ„ж•°жҚ®
- е’іе—Ҫеҗғд»Җд№ҲеҘҪзҡ„еҝ« 8ж¬ҫиҚҜиҶіж–№жҳҫеҘҮж•Ҳ
- OLED|iQOO Neo6 SEж ёеҝғй…ҚзҪ®жӣқе…үпјҡ80Wеҝ«е……+120Hzй«ҳеҲ·
- еҝ«йҖ’|еӨ©жҙҘйӮ®ж”ҝдёҖзҪ‘зӮ№е‘ҳе·ҘеӨҡж¬ЎжҡҙеҠӣжҠӣжү”еҝ«д»¶ иў«зҪҡ1дёҮе…ғ
- йҘөж–ҷ|иҖғиҫӣж–ҜпјҡжҲ‘们жӣҫз»Ҹ1-3йҖҶиҪ¬дәҶеҝ«иҲ№пјҢзҺ°еңЁд№ҹиғҪжҠҠеӢҮеЈ«йҖҒеӣһ家钓йұј
- й…’зІҫиҝӣе…ҘдәәдҪ“зҡ„ж–№ејҸ еҰӮдҪ•е°Ҷй…’зІҫеҝ«йҖҹжҺ’еҲ°дҪ“еӨ–
- дё–з•ҢдёҠжёёеҫ—жңҖеҝ«зҡ„йұјжҳҜ дё–з•ҢдёҠжңҖеҝ«зҡ„ж——йұјйҖҹеәҰ
- еҰӮдҪ•еҝ«йҖҹеҮҸеҗҺиғҢе‘ўпјҹ
- еҝ«иө°е’Ңж…ўи·‘иғҪеҮҸиӮҘд№Ҳпјҹ
- д»Җд№Ҳж—¶еҖҷжіЎи„ҡжңҖе®№жҳ“еҮҸиӮҘ,д»Җд№ҲжіЎи„ҡеҮҸиӮҘжңҖеҝ«