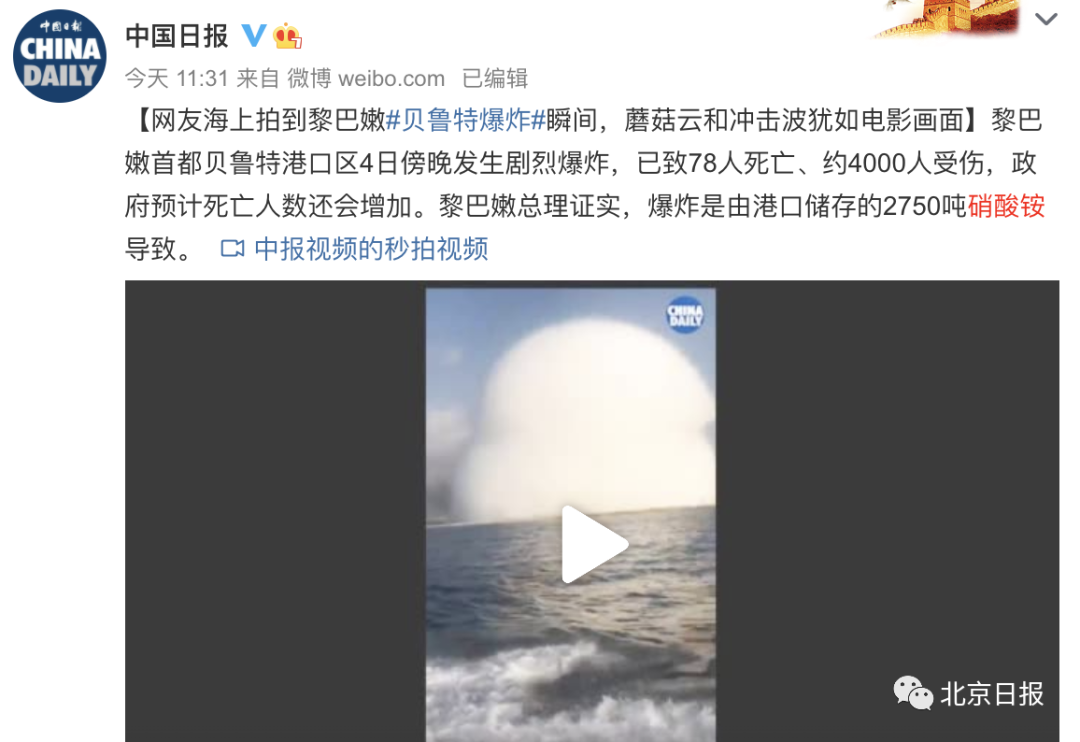
ж”№иҝӣдәҢпјҡй—ЁжҺ§жңәеҲ¶
й—ЁжҺ§еҸҜд»ҘеўһејәжЁЎеһӢзҡ„жҖ§иғҪ并дҪҝи®ӯз»ғиҝҮзЁӢе№іж»‘ гҖӮз ”з©¶иҖ…дёә TransNormerLLM дҪҝз”ЁдәҶжқҘиҮӘи®әж–ҮгҖҠTransformer quality in linear timeгҖӢзҡ„ Flash 方法并еңЁ token ж··еҗҲдёӯдҪҝз”ЁдәҶй—ЁжҺ§ејҸзәҝжҖ§жіЁж„ҸеҠӣпјҲGLAпјүзҡ„з»“жһ„ гҖӮ
дёәдәҶиҝӣдёҖжӯҘжҸҗеҚҮжЁЎеһӢйҖҹеәҰ пјҢ 他们иҝҳжҸҗеҮәдәҶ Simple GLUпјҲSGLUпјү пјҢ е…¶еҺ»йҷӨдәҶеҺҹе§Ӣ GLU з»“жһ„зҡ„жҝҖжҙ»еҮҪж•° пјҢ еӣ дёәй—Ёжң¬иә«е°ұиғҪеј•е…ҘйқһзәҝжҖ§ гҖӮ
ж”№иҝӣдёүпјҡеј йҮҸеҪ’дёҖеҢ–
з ”з©¶иҖ…дҪҝз”ЁдәҶ TransNormer дёӯеј•е…Ҙзҡ„ NormAttention гҖӮеңЁ TransNormerLLM дёӯ пјҢ 他们дҪҝз”ЁдёҖз§Қж–°зҡ„з®ҖеҚ•еҪ’дёҖеҢ–еҮҪж•° SimpleRMSNormпјҲз®ҖеҶҷдёә SRMSNormпјүжӣҝжҚўдәҶ RMSNorm гҖӮ
ж•ҙдҪ“з»“жһ„
еӣҫ 1 еұ•зӨәдәҶ TransNormerLLM зҡ„ж•ҙдҪ“з»“жһ„ гҖӮ

ж–Үз« жҸ’еӣҫ
еӣҫ 1пјҡж–°жҸҗеҮәжЁЎеһӢзҡ„ж•ҙдҪ“жһ¶жһ„
еңЁиҜҘз»“жһ„дёӯ пјҢ иҫ“е…Ҙ X зҡ„жӣҙж–°йҖҡиҝҮдёӨдёӘиҝһз»ӯжӯҘйӘӨе®ҢжҲҗпјҡйҰ–е…Ҳ пјҢ е…¶йҖҡиҝҮдҪҝз”ЁдәҶ SRMSNorm еҪ’дёҖеҢ–зҡ„й—ЁжҺ§ејҸзәҝжҖ§жіЁж„ҸеҠӣпјҲGLAпјүжЁЎеқ— гҖӮ然еҗҺ пјҢ еҶҚж¬ЎйҖҡиҝҮдҪҝз”ЁдәҶ SRMSNorm еҪ’дёҖеҢ–зҡ„з®ҖеҚ•й—ЁжҺ§ејҸзәҝжҖ§еҚ•е…ғпјҲSGLUпјүжЁЎеқ— гҖӮиҝҷз§Қж•ҙдҪ“жһ¶жһ„жңүеҠ©дәҺжҸҗеҚҮжЁЎеһӢзҡ„жҖ§иғҪиЎЁзҺ° гҖӮдёӢж–№з»ҷеҮәдәҶиҝҷдёӘж•ҙдҪ“жөҒзЁӢзҡ„дјӘд»Јз Ғпјҡ

ж–Үз« жҸ’еӣҫ
и®ӯз»ғдјҳеҢ–
й—Әз”өжіЁж„ҸеҠӣ
дёәдәҶеҠ еҝ«жіЁж„ҸеҠӣи®Ўз®—йҖҹеәҰ пјҢ з ”з©¶иҖ…еј•е…ҘдәҶй—Әз”өжіЁж„ҸеҠӣпјҲLightning Attentionпјүз®—жі• пјҢ иҝҷиғҪи®©ж–°жҸҗеҮәзҡ„зәҝжҖ§жіЁж„ҸеҠӣжӣҙйҖӮеҗҲ IOпјҲиҫ“е…Ҙе’Ңиҫ“еҮәпјүеӨ„зҗҶ гҖӮ
з®—жі• 1 еұ•зӨәдәҶй—Әз”өжіЁж„ҸеҠӣзҡ„еүҚеҗ‘йҖҡиҝҮзҡ„е®һзҺ°з»ҶиҠӮ пјҢ з®—жі• 2 еҲҷжҳҜеҗҺеҗ‘йҖҡиҝҮзҡ„ гҖӮз ”з©¶иҖ…иЎЁзӨә пјҢ 他们иҝҳжңүдёҖдёӘеҸҜд»Ҙжӣҙеҝ«и®Ўз®—жўҜеәҰзҡ„е®һзҺ°зүҲжң¬ пјҢ иҝҷдјҡеңЁжңӘжқҘеҸ‘еёғ гҖӮ

ж–Үз« жҸ’еӣҫ

ж–Үз« жҸ’еӣҫ
жЁЎеһӢ并иЎҢеҢ–
дёәдәҶеңЁи®Ўз®—жңәйӣҶзҫӨдёҠеҲҶж•ЈжүҖжңүжЁЎеһӢеҸӮж•°гҖҒжўҜеәҰе’ҢдјҳеҢ–еҷЁзҠ¶жҖҒеј йҮҸ пјҢ з ”з©¶иҖ…дҪҝз”ЁдәҶе…ЁеҲҶзүҮж•°жҚ®е№¶иЎҢпјҲFSDP/Fully Sharded Data Parallelпјү гҖӮиҝҷз§Қзӯ–з•ҘжҖ§еҲҶеҢәж–№жі•еҸҜеҮҸе°‘еҜ№жҜҸдёӘ GPU зҡ„еҶ…еӯҳеҚ з”Ё пјҢ д»ҺиҖҢдјҳеҢ–дәҶеҶ…еӯҳеҲ©з”ЁзҺҮ гҖӮдёәдәҶиҝӣдёҖжӯҘжҸҗй«ҳж•ҲзҺҮ пјҢ 他们дҪҝз”ЁдәҶжҝҖжҙ»жЈҖжҹҘзӮ№пјҲActivation Checkpointingпјү пјҢ иҝҷеҸҜеҮҸе°‘еҗҺеҗ‘йҖҡиҝҮиҝҮзЁӢдёӯзј“еӯҳеңЁеҶ…еӯҳдёӯзҡ„жҝҖжҙ»ж•°йҮҸ гҖӮзӣёеҸҚ пјҢ еҪ“и®Ўз®—иҝҷдәӣжўҜеәҰж—¶ пјҢ иҝҷдәӣжўҜеәҰдјҡ被移йҷӨ并йҮҚж–°и®Ўз®— гҖӮиҜҘжҠҖжңҜжңүеҠ©дәҺжҸҗеҚҮи®Ўз®—ж•ҲзҺҮе’ҢиҠӮзңҒиө„жәҗ гҖӮжӯӨеӨ– пјҢ дёәдәҶеңЁеҮҸе°‘ GPU еҶ…еӯҳж¶ҲиҖ—зҡ„еҗҢж—¶еҠ еҝ«и®Ўз®—йҖҹеәҰ пјҢ з ”з©¶иҖ…иҝҳдҪҝз”ЁдәҶиҮӘеҠЁж··еҗҲзІҫеәҰпјҲAMPпјү гҖӮ
йҷӨдәҶдёҠиҝ°жҲҗжһңеӨ– пјҢ з ”з©¶иҖ…иҝҳжӣҙиҝӣдёҖжӯҘйҖҡиҝҮеҜ№зәҝжҖ§ transformer жү§иЎҢжЁЎеһӢ并иЎҢеҢ–иҖҢиҝӣиЎҢдәҶзі»з»ҹе·ҘзЁӢдјҳеҢ– пјҢ е…¶зҒөж„ҹеҫҲеӨ§зЁӢеәҰдёҠжқҘиҮӘдәҺиӢұдјҹиҫҫзҡ„ Megatron-LM жЁЎеһӢ并иЎҢеҢ– пјҢ еңЁдј з»ҹзҡ„ Transformer жЁЎеһӢдёӯ пјҢ жҜҸдёӘ transformer еұӮйғҪжңүдёҖдёӘиҮӘжіЁж„ҸеҠӣжЁЎеқ— пјҢ е…¶еҗҺи·ҹзқҖдёҖдёӘдёӨеұӮеӨҡеұӮж„ҹзҹҘеҷЁпјҲMLPпјүжЁЎеқ— гҖӮеҪ“дҪҝз”Ё Megatron-LM жЁЎеһӢ并иЎҢжҖ§ж—¶ пјҢ жҳҜеңЁиҝҷдёӨдёӘжЁЎеқ—дёҠзӢ¬з«ӢдҪҝз”Ё гҖӮзұ»дјјең° пјҢ TransNormerLLM з»“жһ„д№ҹжҳҜз”ұдёӨдёӘдё»иҰҒжЁЎеқ—жһ„жҲҗпјҡSGLU е’Ң GLAпјӣиҝҷдёӨиҖ…зҡ„жЁЎеһӢ并иЎҢеҢ–еҲҶејҖжү§иЎҢ гҖӮ
зЁіеҒҘжҺЁзҗҶ
иҝҷи®© TransNormerLLM иғҪд»Ҙ RNN зҡ„еҪўејҸжү§иЎҢжҺЁзҗҶ гҖӮз®—жі• 3 з»ҷеҮәдәҶиҝҷдёӘиҝҮзЁӢзҡ„з»ҶиҠӮ гҖӮдҪҶе…¶дёӯеӯҳеңЁж•°еҖјзІҫеәҰй—®йўҳ гҖӮ

ж–Үз« жҸ’еӣҫ
дёәдәҶйҒҝе…Қиҝҷдәӣй—®йўҳ пјҢ з ”з©¶иҖ…жҸҗеҮәдәҶзЁіеҒҘжҺЁзҗҶз®—жі• пјҢ и§Ғз®—жі• 4 гҖӮ

ж–Үз« жҸ’еӣҫ
еҺҹжҺЁзҗҶз®—жі•е’ҢзЁіеҒҘжҺЁзҗҶз®—жі•еҫ—еҲ°зҡ„з»“жһңжҳҜдёҖж ·зҡ„ гҖӮ
иҜӯж–ҷеә“
з ”з©¶иҖ…д»Һдә’иҒ”зҪ‘收йӣҶдәҶеӨ§йҮҸеҸҜе…¬ејҖдҪҝз”Ёзҡ„ж–Үжң¬ пјҢ жҖ»еӨ§е°Ҹи¶…иҝҮ 700TB гҖӮ收йӣҶеҲ°зҡ„ж•°жҚ®з»Ҹз”ұ他们зҡ„ж•°жҚ®йў„еӨ„зҗҶзЁӢеәҸиҝӣиЎҢеӨ„зҗҶ пјҢ еҰӮеӣҫ 2 жүҖзӨә пјҢ з•ҷдёӢ 6TB зҡ„е№ІеҮҖиҜӯж–ҷеә“ пјҢ е…¶дёӯеҢ…еҗ«еӨ§зәҰ 2 дёҮдәҝ token гҖӮдёәдәҶжҸҗдҫӣжӣҙеҘҪзҡ„йҖҸжҳҺеәҰ пјҢ её®еҠ©з”ЁжҲ·жӣҙеҘҪзҗҶи§Ј пјҢ 他们еҜ№ж•°жҚ®жәҗиҝӣиЎҢдәҶеҲҶй—ЁеҲ«зұ» гҖӮиЎЁ 2 з»ҷеҮәдәҶе…·дҪ“зҡ„зұ»еҲ«жғ…еҶө гҖӮ

ж–Үз« жҸ’еӣҫ
еӣҫ 2пјҡж•°жҚ®йў„еӨ„зҗҶжөҒзЁӢ

ж–Үз« жҸ’еӣҫ
иЎЁ 2пјҡиҜӯж–ҷеә“з»ҹи®Ўж•°жҚ®
е®һйӘҢ
з ”з©¶иҖ…еңЁ Metaseq жЎҶжһ¶дёӯдҪҝз”Ё PyTorch е’Ң Trition е®һзҺ°дәҶ TransNormerLLM гҖӮжЁЎеһӢзҡ„и®ӯз»ғдҪҝз”ЁдәҶ Adam дјҳеҢ–еҷЁ пјҢ FSDP д№ҹиў«з”ЁдәҺй«ҳж•Ҳең°е°ҶжЁЎеһӢжү©еұ•еҲ° NVIDIA A100 80G йӣҶзҫӨ гҖӮ他们д№ҹйҖӮеҪ“ең°дҪҝз”ЁдәҶжЁЎеһӢ并иЎҢжҠҖжңҜжқҘдјҳеҢ–жҖ§иғҪ гҖӮ
жҺЁиҚҗйҳ…иҜ»














- дёҠиҜҫжіЁж„ҸеҠӣдёҚйӣҶдёӯзҡ„еҺҹеӣ еҸҠи§ЈеҶіеҠһжі•
- еҰӮдҪ•еҗёеј•еҘіз”ҹжіЁж„ҸеҠӣ еҰӮдҪ•еҗёеј•еҘіз”ҹжіЁж„ҸеҠӣзҡ„ж–№жі•
- еҰӮдҪ•жҸҗй«ҳжіЁж„ҸеҠӣйӣҶдёӯзІҫеҠӣ еҰӮдҪ•жҸҗй«ҳжіЁж„ҸеҠӣйӣҶдёӯзІҫеҠӣ
- иғЎжӯҢ|еҺҶж—¶18е№ҙпјҒиғЎжӯҢжӢҝдёӢдәәз”ҹдёӯйҰ–дёӘеҪұеёқпјҢе®ҢзҫҺе®ҢжҲҗдәҶжөҒйҮҸеҲ°е®һеҠӣжҙҫзҡ„иҪ¬еҸҳ
- жҖҺд№Ҳй”»зӮји®°еҝҶеҠӣе’ҢжіЁж„ҸеҠӣ
- жҖҺд№Ҳй”»зӮјжіЁж„ҸеҠӣ
- жіЁж„ҸеҠӣдёҺж„Ҹеҝ—еҠӣ
- дё–з•ҢйҰ–дёӘдәәйҖ еҝғи„ҸжҳҜи°ҒеҸ‘жҳҺзҡ„ дё–з•ҢйҰ–дёӘдәәйҖ еҝғи„Ҹ
- е…ЁзҗғйҰ–дёӘпјҒ5GејӮзҪ‘жј«жёёжҳҜд»Җд№ҲпјҢеҰӮдҪ•дҪҝз”Ёпјҹ
- еј зҝ°|SelinaжҖҖеӯ•еҗҺйҰ–дёӘжҜҚдәІиҠӮпјҢдёҺеҰҲеҰҲеҰ№еҰ№еәҶзҘқпјҢеӨ§ж–№йңІеҮәи…ҝйғЁзғ§дјӨз–Өз—•