йҒҚеҺҶ|иҜҚеөҢе…Ҙзҡ„з»Ҹе…ёж–№жі•пјҢе…ӯзҜҮи®әж–ҮйҒҚеҺҶWord2vecзҡ„еҸҰзұ»еә”з”Ё( дәҢ )
еҰӮжһңдәҶи§Ј NLP д»»еҠЎзҡ„иҜқпјҢH зҡ„иҺ·еҸ–зҡ„第дёҖжӯҘи·ҹе№іж—¶жҲ‘们иҺ·еҸ– embedding зҡ„ж–№ејҸдёҖж ·пјҢеӣ дёәиҝҷйҮҢзҡ„ W_I жҳҜеҲқе§ӢеҢ–дёәдј з»ҹ CBOW зҡ„жқғйҮҚпјҢжүҖд»ҘиҝҷдёҖжӯҘе…¶е®һе°ұжҳҜиҺ·еҸ–иҝҷдәӣиҜҚзҡ„дј з»ҹеөҢе…ҘпјҢ然еҗҺеҜ№е…¶еҸ–е№іеқҮдҪңдёәж•ҙдёӘзӘ—еҸЈжүҖжңүиҜҚзҡ„зү№еҫҒпјҢ然еҗҺеҒҡдәҶдёҖдёӘеҲҶзұ»д»»еҠЎгҖӮ
然еҗҺеӣһеҲ° wпјҢиҝҷйҮҢзҡ„ w е…Ғи®ёеҜ№еҗ„з§ҚеҪўејҸзҡ„ w иҝӣиЎҢйҖүжӢ©пјҢжҜ”еҰӮе®Ңж•ҙзҡ„еҸҘеӯҗжҲ–еҪўејҸзҡ„е…ғз»„ (дё»иҰҒеҜ№иұЎгҖҒе…ізі»гҖҒж¬ЎиҰҒеҜ№иұЎ)гҖӮw зҡ„йҖүжӢ©еҸ–еҶідәҺжҲ‘们жүҖе…іеҝғзҡ„д»»еҠЎгҖӮдҫӢеҰӮпјҢеңЁеёёиҜҶж–ӯиЁҖеҲҶзұ»е’ҢеҹәдәҺж–Үжң¬зҡ„еӣҫеғҸжЈҖзҙўдёӯпјҢw жҳҜе…ғз»„дёӯзҡ„зҹӯиҜӯпјҢиҖҢеңЁи§Ҷи§үйҮҠд№үдёӯпјҢw жҳҜеҸҘеӯҗгҖӮз»ҷе®ҡ wпјҢS_w д№ҹжҳҜеҸҜи°ғзҡ„гҖӮе®ғеҸҜд»ҘеҢ…жӢ¬жүҖжңүзҡ„ w(дҫӢеҰӮпјҢд»Һе…ғз»„дёӯзҡ„дёҖдёӘзҹӯиҜӯеӯҰд№ ж—¶) жҲ–еҚ•иҜҚзҡ„дёҖдёӘеӯҗйӣҶ(дҫӢеҰӮпјҢд»ҺеҸҘеӯҗдёӯзҡ„дёҖдёӘ n е…ғдёҠдёӢж–ҮзӘ—еҸЈеӯҰд№ ж—¶)гҖӮ
жңҖеҗҺеҶҚиҜҙдёҖдёӢж•ҲжһңпјҢиҝҷдёӘд»»еҠЎе…¶е®һе°ұжҳҜеңЁ w2v зҡ„еҹәзЎҖдёҠиҝӣиЎҢ finetuneпјҢиҝҷз§ҚзӣҙжҺҘиҝӣиЎҢе…ЁеұҖ finetune зҡ„ж•ҲжһңпјҢжҚ®и®әж–ҮдёӯжүҖиҜҙпјҢд№ҹеҸҜд»ҘдҝқжҢҒжңҖејҖе§Ӣ w2v зҡ„ж•ҲжһңпјҢе°ұжҳҜеҰӮжһңдёҖдәӣиҜҚеңЁ finetune иҝҮзЁӢдёӯжІЎжңүеҮәзҺ°пјҢе®ғ们е°ұдјҡдҝқжҢҒеҺҹжңүзҡ„иҜӯд№үзү№жҖ§пјҢиҝҷз§Қе…ЁеұҖ finetune 并дёҚдјҡи®©ж–°еһӢзҡ„ w2v еңЁдј з»ҹд»»еҠЎдёӯеҸҳеҫ—жӣҙе·®гҖӮ
еҰӮдёӢиЎЁ 1 жүҖзӨәзҡ„и§Ҷи§үиҪ¬иҝ°д»»еҠЎеҜ№жҜ”дёӯпјҢvis-w2v зҡ„ж•ҲжһңжҜ”еҚ•зәҜзҡ„ w2v д»»еҠЎиҰҒеҘҪеҫҲеӨҡгҖӮ
иЎЁ 1пјҡиҪ¬иҝ°д»»еҠЎе№іеқҮеҮҶзЎ®зҺҮпјҲAPпјүгҖӮиЎЁжәҗпјҡ[1]
2.2 Visually Supervised Word2Vec (VS-Word2Vec) [2]
и®әж–Үй“ҫжҺҘпјҡhttps://ieeexplore.ieee.org/abstract/document/8675640"/>
ж–Үз« еӣҫзүҮ
йҰ–е…Ҳ D жҳҜ CBOW зҡ„и®ӯз»ғйӣҶпјҢ然еҗҺеҜ№дәҺиҝҷдёӘи®ӯз»ғйӣҶдёӯзҡ„жҜҸдёӘиҜҚпјҢи®Ўз®—дёӨдёӘжҚҹеӨұ e1 е’Ң e2пјҢe1 е°ұжҳҜеүҚеҚҠйғЁеҲҶпјҢд№ҹе°ұжҳҜдј з»ҹ CBOW зҡ„жҚҹеӨұпјҢe2 жҳҜеҗҺеҚҠйғЁеҲҶпјҢиЎЎйҮҸдәҶдёӨз§Қ embedding зҡ„дёҚдёҖиҮҙжҖ§пјҲJ_VпјүпјҢ\lambda е°ұжҳҜдёӘеҸҜи°ғзҡ„и¶…еҸӮж•°пјҢp_t иЎЁзӨә w_t жҳҜдёҚжҳҜе…ізі»иҜҚпјҢеҰӮжһңжҳҜе…ізі»иҜҚпјҢйӮЈд№Ҳ p_t=1пјҢдҝқз•ҷеҗҺеҚҠйғЁеҲҶпјҢеҰӮжһңдёҚжҳҜе…ізі»иҜҚпјҢеҲҷеҸҳжҲҗдј з»ҹзҡ„ CBOW и®ӯз»ғиҝҮзЁӢгҖӮ
дҪҝз”Ёиҝҷз§Қж–№жі•еҗҺпјҢдҪңиҖ…еңЁ SimVerb-3500 дёӯзҡ„д№қдёӘзұ»еҲ«зҡ„еҗҢд№үиҜҚпјҲSYNONYMS, ANTONYMS, HYPER/HYPONYMS, COHYPONYMпјҢNONE пјүиҝӣиЎҢдәҶеҜ№жҜ”пјҢеҜ№жҜ”з»“жһңеҰӮиЎЁ 2 жүҖзӨәпјҢжҖ»дҪ“жқҘиҜҙжҳҜжҜ” CBOW иҰҒеҘҪзҡ„пјҢиҖҢдё”дёҖдәӣзү№еҲ«зҡ„зұ»дёӯпјҢж•Ҳжһңзҡ„жҸҗеҚҮиҝҳеҫҲеӨ§гҖӮ
иЎЁ 2пјҡеҗҢд№үиҜҚдёҖиҮҙжҖ§з»“жһңгҖӮиЎЁжәҗпјҡ[2]
2.3 Action2Vec [4]
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/1901.00484.pdf
е…·дҪ“жқҘиҜҙпјҢе·Ұиҫ№е…ҲдҪҝз”Ёз”ұ [5] дёӯж•°жҚ®йӣҶйў„и®ӯз»ғеҘҪзҡ„ C3D жЁЎеһӢжқҘжҸҗеҸ–жҜҸдёҖеё§зҡ„еӣҫзүҮзҡ„зү№еҫҒеҗ‘йҮҸпјҢ然еҗҺдҪҝз”ЁдәҶдёҖдёӘ Hierarchical Recurrent Neural Network (HRNN) пјҢ并еҠ е…ҘдәҶиҮӘжіЁж„ҸеҠӣжңәеҲ¶пјҢжңҖеҗҺйҖҡиҝҮдёҖдёӘе…ЁиҝһжҺҘеұӮпјҲfully connected weightsпјүе°Ҷ LSTM2 еҫ—еҲ°зҡ„и§Ҷйў‘еөҢе…ҘеҸҳжҲҗи·ҹиҜҚеөҢе…ҘзӣёеҗҢз»ҙеәҰзҡ„еҗ‘йҮҸпјҢжңҖеҗҺиҝҷдёӘеҗ‘йҮҸеҸҲйҖҡиҝҮдёҖдёӘе…ЁиҝһжҺҘеұӮеҒҡдәҶдёҖдёӘеҲҶзұ»д»»еҠЎпјҢеҲӨж–ӯиҝҷдёӘи§Ҷйў‘еҜ№еә”зҡ„еҠЁдҪңжҳҜд»Җд№ҲгҖӮ然еҗҺйҖҡиҝҮдёҖдёӘвҖңеҸҢжҚҹеӨұвҖқпјҲcross entropy+pairwise rankingпјүжқҘи®©ж”№е–„еҗҺзҡ„ joint embedding space еҗҢж—¶е…·жңүи§Ҷйў‘е’Ңж–Үжң¬зҡ„иҜӯд№үдҝЎжҒҜгҖӮ
еҸҢжҚҹеӨұпјҲdual lossпјүпјҡиҝҷйҮҢзҡ„еҸҢжҚҹеӨұе°ұжҳҜжҢҮ cross entropy еҠ pairwise ranking lossпјҢcross entropy иҝҷйҮҢе°ұдёҚеӨҡеҒҡд»Ӣз»ҚпјҢеҜ№еә”зҡ„е°ұжҳҜдёҠйқўиҜҙзҡ„еҲҶзұ»д»»еҠЎпјҢpairwise ranking loss(PR loss)еҰӮжһңдёҚдәҶи§Јзҡ„еҸҜд»ҘзңӢдёҖдёӢиҝҷзҜҮж–Үз« пјҲhttps://gombru.github.io/2019/04/03/ranking_loss/пјүпјҢдјҡжӣҙе®№жҳ“зҗҶи§ЈдёӢйқўзҡ„ејҸеӯҗгҖӮиҝҷйҮҢзҡ„ PR loss е®ҡд№үдёәдёӢејҸпјҡ
жңҖеҗҺйңҖиҰҒиҜҙжҳҺзҡ„дёҖзӮ№жҳҜеӣ дёәдёӨдёӘж•°жҚ®еә“зҡ„иҜҚ并дёҚиғҪе®Ңе…ЁдёҖиҮҙпјҢеҸҜиғҪдјҡеҮәзҺ°и§Ҷйў‘ж•°жҚ®еә“дёӯзҡ„иҜҚеңЁ word2vec иҜҚеә“дёӯдёҚеӯҳеңЁзҡ„жғ…еҶөпјҢиҝҷж—¶иҝҷдәӣеҠЁиҜҚе°ұдјҡиў«иҪ¬еҢ–жҲҗеҜ№еә”зҡ„еҪўејҸпјҲеҰӮ walking еҸҳжҲҗ walk зӯүпјүгҖӮ
е®һйӘҢйғЁеҲҶпјҢдҪңиҖ…еңЁ ZSAL(Zero Shot Action Learning)д»»еҠЎдёӯдёҺе…¶д»– ZSL жЁЎеһӢиҝӣиЎҢдәҶеҜ№жҜ”пјҢеҸҜи§ҒдҪңиҖ…жҸҗеҮәзҡ„жЁЎеһӢеңЁеҗ„дёӘж•°жҚ®йӣҶдёҠзҡ„ж•ҲжһңйғҪжҳҜжңҖеҘҪзҡ„гҖӮ
иЎЁ 3пјҡZSAL(Zero Shot Action Learning)жЁЎеһӢж•ҲжһңеҜ№жҜ”гҖӮиЎЁжәҗпјҡ[4]
2.4 sound-word2vec [7]
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/1703.01720.pdf
дёҺ第дёҖзҜҮи®әж–ҮдёҖж ·пјҢиҝҷйҮҢеҲҶзұ»д»»еҠЎзҡ„ж ҮзӯҫеҸҲжҳҜжқҘиҮӘдәҺиҒҡзұ»гҖӮs е…Ҳз»ҸиҝҮиҒҡзұ»еҫ—еҲ°зұ»еҲ«ж ҮзӯҫпјҢ然еҗҺиҝҷдёӘж Үзӯҫе°ұз”ЁдәҺи®ӯз»ғ W_P е’Ң W_OгҖӮж•ҙдҪ“дёҠжқҘиҜҙпјҢиҝҷзҜҮи®әж–Үзҡ„жҖқжғіи·ҹ第дёҖзҜҮи®әж–Үе·®дёҚеӨҡпјҢдҪҶжҳҜи®әж–Үдёӯе…ідәҺеЈ°йҹіеҰӮдҪ•иЎЁеҫҒзӯүзҡ„еЈ°йҹіеӨ„зҗҶиҝҳжҳҜеҫҲе…·жңүеҗҜеҸ‘жҖ§зҡ„пјҢеҗҢж—¶иҝҷзҜҮи®әж–ҮеҶҚдёҖж¬ЎиҜҒжҳҺдәҶж•ҙдҪ“ finetune еҸҜд»ҘеңЁж”№е–„дј з»ҹиҜҚеөҢе…Ҙз©әй—ҙдёҠеҸ–еҫ—дёҚй”ҷзҡ„ж•ҲжһңгҖӮ
иҝҷдёӘж–№жі•зҡ„ж•ҲжһңеҰӮиЎЁ 4 жүҖзӨәпјҢеңЁжҷ®йҖҡиҜҚдёҠпјҢж•Ҳжһңи·ҹ word2vec е·®дёҚеӨҡпјҢдҪҶжҳҜеңЁжӢҹеЈ°иҜҚдёҠпјҢsound-word2vec жҳҺжҳҫиЎЁзҺ°е°ұиҰҒеҘҪеҫҲеӨҡдәҶгҖӮдҪңиҖ…иҝҳеңЁдёҖдәӣеҹәдәҺж–Үжң¬зҡ„жӢҹеЈ°иҜҚиҜҶеҲ«д»»еҠЎдёӯиҝӣиЎҢдәҶе®һйӘҢпјҢж•ҲжһңжҜ”жҷ®йҖҡзҡ„ baseline жЁЎеһӢйғҪиҰҒеҘҪеҫҲеӨҡпјҲе…·дҪ“з»ҶиҠӮеҸҜд»ҘеҺ»зңӢдёҖдёӢеҺҹи®әж–ҮпјүгҖӮ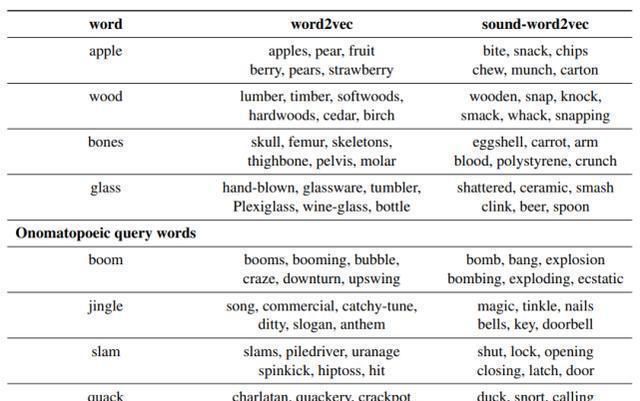
ж–Үз« еӣҫзүҮ
иЎЁ 4пјҡзӣёдјјиҜҚзӨәдҫӢгҖӮиЎЁжәҗпјҡ[7]
3гҖҒжҺўзҙўж–°з©әй—ҙ
и®әж–Үй“ҫжҺҘпјҡhttps://link.springer.com/article/10.1007/s00521-018-3923-1
Google еңЁеҺ»е№ҙеҲ©з”ЁиҜӯиЁҖжЁЎеһӢе°ҶиӣӢзҷҪиҙЁеәҸеҲ—иҪ¬жҚўжҲҗеөҢе…ҘпјҢд»ҺиҖҢе®һзҺ°дәҶеҫҲеӨҡзӣёе…ід»»еҠЎзҡ„йЈһи·ғпјҢиҝҷдёӘжҲ‘жӣҫз»ҸеҶҷиҝҮдёҖзҜҮж–Үз« жқҘдё“й—Ёд»Ӣз»ҚпјҢиҝҷйҮҢе°ұдёҚеӨҡеҒҡиөҳиҝ°пјҢд»ҠеӨ©дё»иҰҒд»Ӣз»ҚиҝҷдёӘж–№жі•жҳҜеҰӮдҪ•еә”з”ЁдәҺйҹід№җдёҠпјҢд»ҺиҖҢдә§з”ҹдёҖдёӘж–°зҡ„еҹәдәҺйҹід№җзҡ„еөҢе…Ҙз©әй—ҙпјҢж–°зҡ„еөҢе…Ҙз©әй—ҙд№җзҗҶзҹҘиҜҶиҝӣиЎҢдәҶиЎЁеҫҒвҖ”вҖ”йҹід№җ + word2vec [6]гҖӮ
еӣ дёәиҝҷзҜҮи®әж–ҮеҢ…еҗ«дәҶжҜ”иҫғдё“дёҡзҡ„д№җзҗҶзҹҘиҜҶпјҢиҖҢеҜ№еә”зҡ„жңәеҷЁеӯҰд№ ж–№жі•е°ұзӣёеҜ№жҜ”иҫғдј з»ҹпјҢе°ұжҳҜдёҖдёӘ skip-gram жЁЎеһӢеҠ дёҠеҜ№д№җи°ұиҝӣиЎҢзј–з ҒгҖӮдҪҶжҳҜи®әж–ҮдёӯеҜ№д№җи°ұеҗ„йЎ№д№җзҗҶзҹҘиҜҶеңЁд№җи°ұеөҢе…Ҙз©әй—ҙзҡ„иЎЁеҫҒжғ…еҶөиҝӣиЎҢдәҶиҜҰз»ҶеҲҶжһҗпјҢиЎЁжҳҺдәҶ skip-gram еҫҲеҘҪең°д»Һд№җи°ұдёӯеӯҰд№ еҲ°дәҶд№җзҗҶзҹҘиҜҶгҖӮ
жҺЁиҚҗйҳ…иҜ»















![[иӢұдёәиҙўжғ…Investing]дҪҺдәҺйў„жңҹпјҢзҫҺеӣҪеҚ—ж–№е…¬еҸё Q1 жҜҸиӮЎж”¶зӣҠ и¶…еҮәйў„жңҹпјҢиҗҘ收](https://imgcdn.toutiaoyule.com/20200501/20200501060628484590a_t.jpeg)

- 全家жҖ»еҠЁе‘ҳпјҢе…ұеҗҢеӯҰз»Ҹе…ёпјҢи§ӮжҫңеӨ§еҜҢзӨҫеҢәеӣҪеӯҰдәІеӯҗиҜөиҜ»иҺ·еұ…ж°‘еҘҪиҜ„
- 马жҖқзәҜ|гҖҠиҚһйәҰз–Ҝй•ҝгҖӢеҶҚе”ұжңҙж ‘з»Ҹе…ёжӣІгҖҠcolorful daysгҖӢ
- Angelababy|жқЁйў–cosзҺӢзҘ–иҙӨгҖҠдёңжҲҗиҘҝе°ұгҖӢз»Ҹе…ёйҖ еһӢдёҺйғ‘жҒәжҗӯжҲҸ
- жөҒдј |зӣҳзӮ№гҖҠз»Ҹе…ёе’ҸжөҒдј гҖӢдёӯеҚ°иұЎжңҖж„ҹдәәзҡ„еҮ йҰ–жӯҢпјҢдҪ жҳҜеҗҰеҗ¬иҝҮпјҹ
- е…ёйҮҚ|дёүйғЁиҝӘеЈ«е°јз»Ҹе…ёйҮҚжҳ пјҒеҠ©еҠӣеҪұйҷўеӨҚе·Ҙ
- з”өи§Ҷеү§|еӣһйЎҫз”өи§Ҷеү§гҖҠйҖҶжөҒдёҠзҡ„дҪ гҖӢй«ҳеҜҶиҜҙзҡ„з»Ҹе…ёзҡ„7еҸҘиҜқ
- й’ҹжұүиүҜ|й’ҹжұүиүҜ5йғЁз»Ҹе…ёеү§дҪңпјҢйғЁйғЁзЁіи¶…гҖҠеҮүз”ҹгҖӢдёҖеӨ§жҲӘпјҢе“ӘйғЁжҲҗдҪ жңҖзҲұ
- йқўеҢ…|й»Ҝ然й”ҖйӯӮзҡ„иҠқеЈ«йқўеҢ…пјҢзҫҺе‘іпјҒ
- йқўеҢ…|й»Ҝ然й”ҖйӯӮзҡ„иҠқеЈ«йқўеҢ…пјҢзҫҺе‘іпјҒ
- дәҡи§Ҷз»Ҹе…ёеү§|97е№ҙжңҖиҪ°еҠЁзҡ„еӣӣйғЁжёҜеү§пјҢTVBе’Ңдәҡи§Ҷеҗ„жңүдёӨйғЁпјҢеҪ“е№ҙзҶ¬еӨңд№ҹиҰҒиҝҪ