йҒҚеҺҶ|иҜҚеөҢе…Ҙзҡ„з»Ҹе…ёж–№жі•пјҢе…ӯзҜҮи®әж–ҮйҒҚеҺҶWord2vecзҡ„еҸҰзұ»еә”з”Ё( дёү )
еҰӮжһңйҹізүҮй•ҝдәҺдёҖжӢҚпјҢжҲ‘们еҸҜиғҪдјҡеӨұеҺ»йҹіи°ғе’Ңе’ҢејҰеҸҳеҢ–дёҠзҡ„з»Ҷеҫ®е·®еҲ«гҖӮзӣёеҸҚпјҢеҰӮжһңеҲҮзүҮзҹӯдәҺдёҖдёӘиҠӮжӢҚпјҢеҲҷеҸҜиғҪжңүеӨӘеӨҡйҮҚеӨҚзҡ„еҲҮзүҮ(е…¶дёӯеҲҮзүҮд№Ӣй—ҙзҡ„еҶ…е®№жҳҜзӣёеҗҢзҡ„)гҖӮеҜ»жүҫеҲҮзүҮзҡ„жңҖдҪіжҢҒз»ӯж—¶й—ҙд№ҹеҫҲйҮҚиҰҒпјҢдҪҶжҳҜиҝҷзҜҮж–Үз« е№¶жІЎжңүж¶үеҸҠпјҢзӣёдҝЎдёҖдёӘжӣҙеҘҪзҡ„зј–з Ғж–№ејҸдјҡи®©иҝҷдёӘз ”з©¶зҡ„ж•ҲжһңжӣҙеҘҪгҖӮ
еӣ дёәиҝҷзҜҮж–Үз« зҡ„д»·еҖјдёҚеңЁдәҺз”ЁдәҶд»Җд№ҲжңәеҷЁеӯҰд№ ж–№жі•пјҢеҸӘжҳҜз”ЁдәҶ skip-gramпјҢж•…иҖҢдёҚеҶҚеҜ№и®ӯз»ғиҝҮзЁӢиҝӣиЎҢи®Іиҝ°е•ҰгҖӮеҪ“然пјҢиҝҷзҜҮи®әж–ҮйҷӨдәҶиҜҒжҳҺдәҶ skip-gram еҸҜд»ҘеңЁйҹід№җйўҶеҹҹеҫҲеҘҪзҡ„иҺ·еҸ– chord е’Ң harmonic зү№еҫҒпјҢиҝҳжҸҗдҫӣдәҶеҫҲеӨҡйҹід№җйўҶеҹҹеҸҜд»Ҙз”Ёзҡ„ж•°жҚ®йӣҶпјҲsection 4пјүпјҢеҰӮжһңжңүе…ҙи¶ЈеңЁиҝҷдёӘйўҶеҹҹеҒҡзӮ№д»Җд№ҲпјҢиҝҷдәӣж•°жҚ®йӣҶиҝҳжҳҜеҫҲжңүз”Ёзҡ„гҖӮ
иҝҷзҜҮи®әж–Үзҡ„з»“жһңеҲҶжһҗиҝҮдәҺдё“дёҡпјҢеҰӮжһңжғізңӢдёҖдёӢйҹід№җеӨ§еёҲеҜ№иҝҷдёӘжЁЎеһӢзҡ„иҜ„д»·пјҢеҸҜд»ҘеҺ»зңӢдёҖдёӢеҺҹе§Ӣи®әж–ҮпјҢжҖ»д№ӢиҝҷдёӘжЁЎеһӢеңЁеҗ„дёӘж–№йқўиЎЁзҺ°зҡ„еҫҲеҘҪпјҢеҜ№йҹід№җжңүдәҶи§Јзҡ„еҗҢеӯҰеҸҜд»ҘзңӢдёҖдёӢеҺҹи®әж–ҮдёӯжҳҜжҖҺд№ҲеҲҶжһҗзҡ„пјҢжҲ–и®ёеҜ№еҗҺз»ӯд»»еҠЎд№ҹжңүеҫҲеӨ§зҡ„её®еҠ©гҖӮ
4гҖҒдҪҝз”ЁиҝҷдёӘз©әй—ҙ
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/1908.01211.pdf
жңҖеҗҺпјҢеңЁи®Ёи®әдәҶеҰӮдҪ•ж”№е–„дј з»ҹиҜҚеөҢе…Ҙз©әй—ҙе’ҢеҰӮдҪ•еҲӣе»әж–°еөҢе…Ҙз©әй—ҙд№ӢеҗҺпјҢеҰӮдҪ•дҪҝз”ЁиҝҷдёӘз©әй—ҙд№ҹеҫҲйҮҚиҰҒгҖӮдҪҶжҳҜеӣ дёәжң¬ж–ҮдёҚжҳҜеҜ№ word2vec зҡ„д»Ӣз»ҚпјҢжүҖд»Ҙдј з»ҹзҡ„ NLP д»»еҠЎдёӯ word2vec зҡ„еә”з”ЁеңЁжӯӨе°ұдёҚеҶҚеӨҡеҒҡд»Ӣз»ҚдәҶпјҢзҪ‘дёҠе·Із»ҸжңүеҫҲеӨҡе®һи·өдёҠжҲ–жҳҜзҗҶи®әдёҠзҡ„科жҷ®ж–ҮгҖӮиҝҷйҮҢдё»иҰҒд»Ӣз»ҚиҜҚеөҢе…ҘжҳҜеҰӮдҪ•еңЁ RL дёӯеә”з”Ёзҡ„вҖ”вҖ”Word2vec to behavior [8]гҖӮ
иҝҷйҮҢзҡ„ a д»ЈиЎЁеЈ°еӯҰзҘһз»Ҹз»ҶиғһпјҢдёҖејҖе§Ӣе…Ҳиҫ“е…Ҙе‘Ҫд»ӨпјҢ然еҗҺз”ЁиҝҷдёӘе‘Ҫд»Өзҡ„ embedding еҲқе§ӢеҢ–йҡҗи—ҸеұӮ hiпјҢиҝҷйҮҢеҲқе§ӢеҢ–жҳҜдҪҝз”Ёж–Үдёӯ 5 дёӘе‘Ҫд»ӨиҜҚзҡ„ embedding жқҘе…ҲиҝӣиЎҢйў„и®ӯз»ғд»ҘеҲқе§ӢеҢ– h_1-h_5пјҢе‘Ҫд»ӨиҜҚдёәвҖҳforwardвҖҷ, вҖҳbackwardвҖҷ, вҖҳstopвҖҷ, вҖҳceaseвҖҷ, вҖҳsuspendвҖҷ, and вҖҳhaltвҖҷпјҢе…¶дёӯеҗҺйқўеӣӣдёӘиҜҚиЎЁиҫҫзҡ„ж„ҸжҖқдёҖиҮҙпјҢжүҖжңүдёҖдёӘдёҚдјҡиў«з”ЁжқҘеҒҡеҲқе§ӢеҢ–пјҢдҪңдёәжөӢиҜ•з»„гҖӮеҲқе§ӢеҢ–е®ҢжҲҗеҗҺпјҢиҝҷдәӣиҷҡзәҝзҡ„иҝһжҺҘе°ұдјҡиў«еҲ йҷӨпјҢ然еҗҺжңәеҷЁдәәе°ұиҝӣе…Ҙд»ҝзңҹеҷЁејҖе§Ӣд»ҝзңҹпјҢе°Ҷе‘Ҫд»Өзҡ„еөҢе…Ҙиҫ“е…Ҙз»ҷжңәеҷЁдәәпјҢ然еҗҺйҖҡиҝҮеҗ„дёӘдј ж„ҹеҷЁ (s) еҫ—еҲ°зҡ„дҝЎжҒҜиҝӣиЎҢеҠЁдҪңгҖӮиҝҷдёӘеҲқе§ӢеҢ–е°ұдҪҝеҫ—зҪ‘з»ңиҺ·еҸ–дәҶиҜӯд№үдҝЎжҒҜгҖӮ
з»ҸиҝҮиҜ„дј°еҗҺпјҢе°Ҷж №жҚ®дёҺе‘Ҫд»Өй…ҚеҜ№зҡ„зӣ®ж ҮеҮҪж•°пјҲдҫӢеҰӮжғ©зҪҡиҝҗеҠЁзҡ„еҮҪж•°пјүеҜ№жңәеҷЁдәәзҡ„иЎҢдёәиҝӣиЎҢиҜ„еҲҶгҖӮ然еҗҺпјҢй’ҲеҜ№е…¶д»–еӣӣдёӘе‘Ҫд»Өе’Ңзӣ®ж ҮеҮҪж•°пјҢеҜ№еҗҢдёҖзӯ–з•ҘиҝӣиЎҢеӣӣж¬Ўд»ҘдёҠзҡ„иҜ„дј°пјҲB е’Ң C еҲҶеҲ«еҜ№еә”дёӨж¬ЎпјүпјҢеҜ№зӯ–з•ҘиҝӣиЎҢи®ӯз»ғпјҢд»Ҙй’ҲеҜ№жүҖжңүиҝҷдә”дёӘеҠҹиғҪпјҲDпјүжңҖеӨ§еҢ–е№іеқҮеҲҶж•°гҖӮз»ҸиҝҮи®ӯз»ғеҗҺпјҢжңҖдҪізӯ–з•ҘдјҡжҸҗдҫӣдёҖдёӘи®ӯз»ғж—¶жІЎжңүзҡ„第е…ӯз§ҚеҗҢд№үиҜҚ вҖңceaseвҖқпјҢ并且其иЎҢдёәдјҡж №жҚ®вҖңеҒңжӯўвҖқ зӣ®ж ҮеҮҪж•°пјҲEпјүиҝӣиЎҢиҜ„еҲҶгҖӮ
жңҖз»Ҳзҡ„з»“жһңеҰӮдёӢеӣҫжүҖзӨәпјҢжҜҸдёӘйўңиүІд»ЈиЎЁдёҖз§Қе‘Ҫд»ӨпјҢеҸҜд»ҘзңӢеҲ°дҪңиҖ…зҡ„ж–№жі•пјҲ第дёҖдёӘпјүи®ӯз»ғзҡ„жңәеҷЁдәәеңЁ вҖңеҒңжӯўвҖқ иҝҷжқЎе‘Ҫд»ӨдёҠзЎ®е®һиЎЁзҺ°еҫ—жҜ”е…¶д»–зҡ„иҰҒеҘҪгҖӮ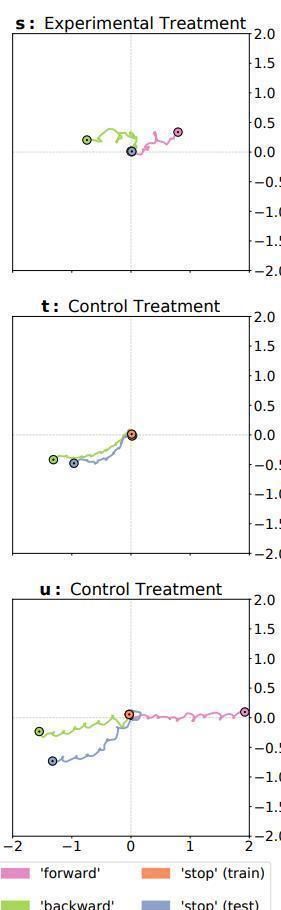
ж–Үз« еӣҫзүҮ
жҖ»з»“
д»Һжң¬ж–ҮжҸҗеҲ°зҡ„иҝҷдәӣеҲҶжһҗжҖ§жҲ–жҳҜеҲӣж–°жҖ§и®әж–ҮжқҘзңӢпјҢskip-gram е’Ң CBOW иғҪеӨҹеҫҲеҘҪең°иҺ·еҸ–жҲ‘们з”ҹжҙ»з”ҹеҫҲеӨҡеҜ№иұЎзҡ„иҜӯд№үпјҲйҹід№җгҖҒеЈ°йҹізӯүпјүпјҢиҖҢ multi-modal жҳҜдёҖдёӘеҫҲеҘҪең°е®Ңе–„зҺ°жңүеөҢе…Ҙз©әй—ҙзҡ„ж–№жі•пјҢеңЁжІЎжңү label зҡ„жғ…еҶөдёӢпјҢеҗҲзҗҶзҡ„иҒҡзұ»д№ҹеҸҜд»ҘжҸҗдҫӣз»ҷжЁЎеһӢиҫ…еҠ©ж ҮзӯҫгҖӮиҝҷдёӘеөҢе…Ҙз©әй—ҙд№ҹдёҚеҸӘжҳҜеҸҜд»Ҙеә”з”ЁдәҺ NLP йўҶеҹҹпјҢиҝҳжңүеҫҲеӨҡе…¶д»–йўҶеҹҹеҸҜд»ҘзӣҙжҺҘеҘ—з”Ё w2v дёӯз”ҹжҲҗзҡ„еөҢе…Ҙз©әй—ҙпјҲеҰӮ RLпјүгҖӮ
еҪ“然пјҢжңӘжқҘиҝҳжңүеҫҲеӨҡе…¶д»–еҸҜд»ҘжҺўзҙўзҡ„ж–№еҗ‘пјҢжҜ”еҰӮеҸ‘еұ•жҜ”иҫғеҲқзә§зҡ„йҹід№җйўҶеҹҹпјҢеҰӮдҪ•е°ҶеЈ°йҹідёӯзҡ„жғ…з»Әз»“еҗҲеҲ°дј з»ҹзҡ„ w2v жЁЎеһӢдёӯеҺ»зӯүзӯүгҖӮ
жҖ»д№ӢпјҢиҜӯиЁҖдҪңдёәжҲ‘们и§ӮеҜҹе’ҢжҸҸиҝ°дё–з•Ңзҡ„дёҖдёӘеҹәжң¬иҰҒзҙ пјҢиҜӯиЁҖ еҹәжң¬иҰҶзӣ–дәҶжҲ‘们з”ҹжҙ»зҡ„ж–№ж–№йқўйқўпјҢеңЁжҹҗдәӣеұӮйқўд№ҹеҸҚжҳ дәҶе®ўи§Ӯдё–з•Ңзҡ„规еҫӢпјҲжҜ”еҰӮиҜӯиЁҖеӯҰзҡ„вҖңеӨҚеҗҲжҖ§еҺҹзҗҶвҖқ-compositionality)пјҢйҒҮеҲ°ж— жі•и§ЈеҶізҡ„еӯҰд№ зҡ„й—®йўҳзҡ„ж—¶еҖҷпјҢиҜӯиЁҖжЁЎеһӢжҲ–и®ёдјҡз»ҷдҪ дёҖзӮ№зӮ№еҗҜеҸ‘гҖӮ
еҸӮиҖғж–ҮзҢ®
[1] Kottur, Satwik, et al. "Visual word2vec (vis-w2v): Learning visually grounded word embeddings using abstract scenes." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[2] Wang, Xue, et al. "Embedded Representation of Relation Words with Visual Supervision." 2019 Third IEEE International Conference on Robotic Computing (IRC). IEEE, 2019.
[3] Lu, Cewu, et al. "Visual relationship detection with language priors." European conference on computer vision. Springer, Cham, 2016.
[4] Hahn, Meera, Andrew Silva, and James M. Rehg. "Action2vec: A crossmodal embedding approach to action learning." arXiv preprint arXiv:1901.00484 (2019).
[5] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014. 4
[6] Chuan, C.-H., Agres, K., & Herremans, D. (2018). From context to concept: exploring semantic relationships in music with word2vec. Neural Computing and Applications. doi:10.1007/s00521-018-3923-1
[7] Vijayakumar, Ashwin K., Ramakrishna Vedantam, and Devi Parikh. "Sound-word2vec: Learning word representations grounded in sounds." arXiv preprint arXiv:1703.01720 (2017).
жҺЁиҚҗйҳ…иҜ»















![[иӢұдёәиҙўжғ…Investing]дҪҺдәҺйў„жңҹпјҢзҫҺеӣҪеҚ—ж–№е…¬еҸё Q1 жҜҸиӮЎж”¶зӣҠ и¶…еҮәйў„жңҹпјҢиҗҘ收](https://imgcdn.toutiaoyule.com/20200501/20200501060628484590a_t.jpeg)

- 全家жҖ»еҠЁе‘ҳпјҢе…ұеҗҢеӯҰз»Ҹе…ёпјҢи§ӮжҫңеӨ§еҜҢзӨҫеҢәеӣҪеӯҰдәІеӯҗиҜөиҜ»иҺ·еұ…ж°‘еҘҪиҜ„
- 马жҖқзәҜ|гҖҠиҚһйәҰз–Ҝй•ҝгҖӢеҶҚе”ұжңҙж ‘з»Ҹе…ёжӣІгҖҠcolorful daysгҖӢ
- Angelababy|жқЁйў–cosзҺӢзҘ–иҙӨгҖҠдёңжҲҗиҘҝе°ұгҖӢз»Ҹе…ёйҖ еһӢдёҺйғ‘жҒәжҗӯжҲҸ
- жөҒдј |зӣҳзӮ№гҖҠз»Ҹе…ёе’ҸжөҒдј гҖӢдёӯеҚ°иұЎжңҖж„ҹдәәзҡ„еҮ йҰ–жӯҢпјҢдҪ жҳҜеҗҰеҗ¬иҝҮпјҹ
- е…ёйҮҚ|дёүйғЁиҝӘеЈ«е°јз»Ҹе…ёйҮҚжҳ пјҒеҠ©еҠӣеҪұйҷўеӨҚе·Ҙ
- з”өи§Ҷеү§|еӣһйЎҫз”өи§Ҷеү§гҖҠйҖҶжөҒдёҠзҡ„дҪ гҖӢй«ҳеҜҶиҜҙзҡ„з»Ҹе…ёзҡ„7еҸҘиҜқ
- й’ҹжұүиүҜ|й’ҹжұүиүҜ5йғЁз»Ҹе…ёеү§дҪңпјҢйғЁйғЁзЁіи¶…гҖҠеҮүз”ҹгҖӢдёҖеӨ§жҲӘпјҢе“ӘйғЁжҲҗдҪ жңҖзҲұ
- йқўеҢ…|й»Ҝ然й”ҖйӯӮзҡ„иҠқеЈ«йқўеҢ…пјҢзҫҺе‘іпјҒ
- йқўеҢ…|й»Ҝ然й”ҖйӯӮзҡ„иҠқеЈ«йқўеҢ…пјҢзҫҺе‘іпјҒ
- дәҡи§Ҷз»Ҹе…ёеү§|97е№ҙжңҖиҪ°еҠЁзҡ„еӣӣйғЁжёҜеү§пјҢTVBе’Ңдәҡи§Ҷеҗ„жңүдёӨйғЁпјҢеҪ“е№ҙзҶ¬еӨңд№ҹиҰҒиҝҪ