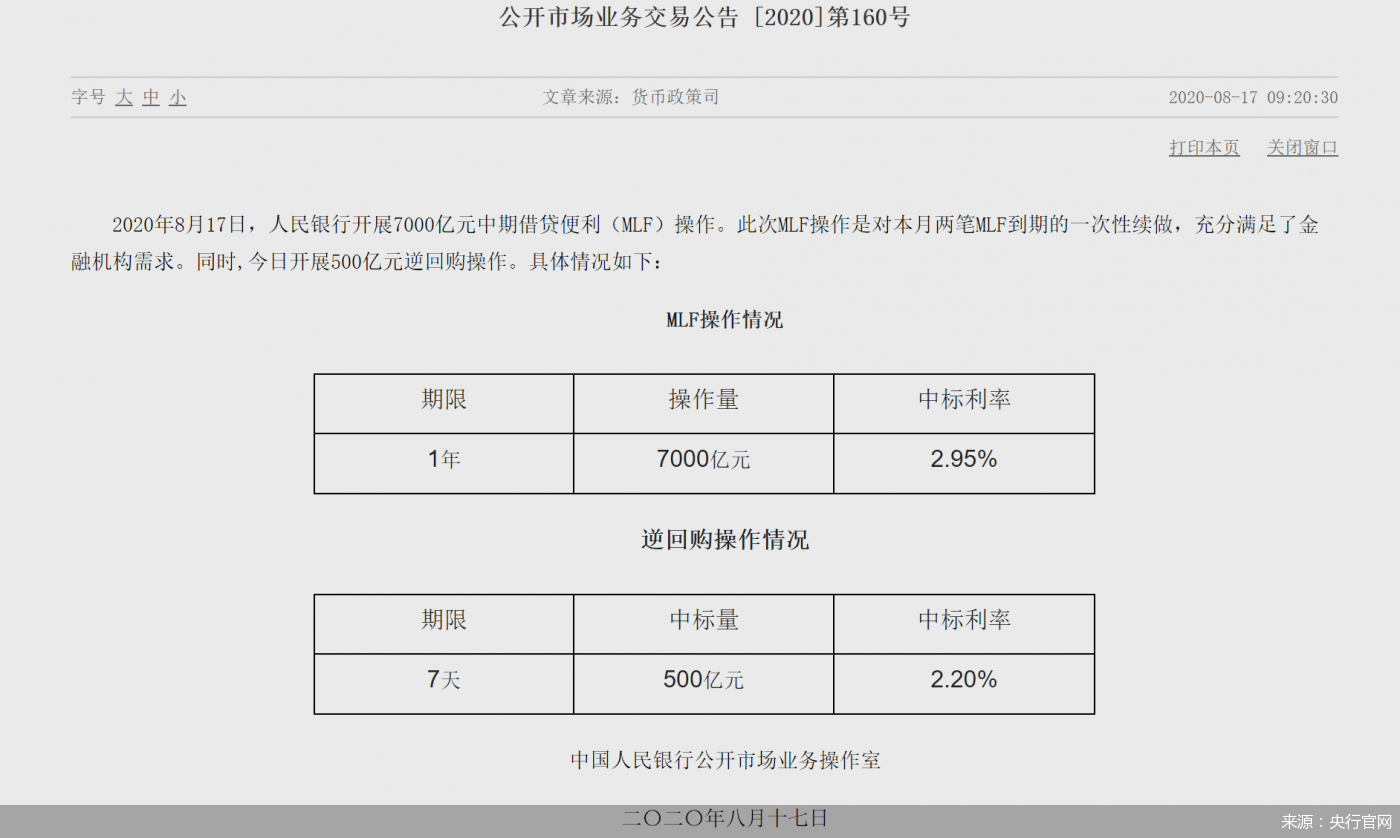
|жҗһжҮӮиҝҷдәӣSQLдјҳеҢ–жҠҖе·§пјҢйқўиҜ•жЁӘзқҖиө°( дәҢ )
еҰӮдёӢпјҡ
SELECT * FROM t WHERE id IN (2,3) дјҳеҢ–ж–№ејҸпјҡеҰӮжһңжҳҜиҝһз»ӯж•°еҖј пјҢ еҸҜд»Ҙз”Ё between д»Јжӣҝ гҖӮ
еҰӮдёӢпјҡ
SELECT * FROM t WHERE id BETWEEN 2 AND 3 еҰӮжһңжҳҜеӯҗжҹҘиҜў пјҢ еҸҜд»Ҙз”Ё exists д»Јжӣҝ гҖӮ
еҰӮдёӢпјҡ
-- дёҚиө°зҙўеј• select * from A where A.id in (select id from B); -- иө°зҙўеј• select * from A where exists (select * from B where B.id = A.id);в‘ўе°ҪйҮҸйҒҝе…ҚдҪҝз”Ё or пјҢ дјҡеҜјиҮҙж•°жҚ®еә“еј•ж“Һж”ҫејғзҙўеј•иҝӣиЎҢе…ЁиЎЁжү«жҸҸ
еҰӮдёӢпјҡ
SELECT * FROM t WHERE id = 1 OR id = 3 дјҳеҢ–ж–№ејҸпјҡеҸҜд»Ҙз”Ё union д»Јжӣҝ or гҖӮ
еҰӮдёӢпјҡ
SELECT * FROM t WHERE id = 1 UNION SELECT * FROM t WHERE id = 3в‘Је°ҪйҮҸйҒҝе…ҚиҝӣиЎҢ null еҖјзҡ„еҲӨж–ӯ пјҢ дјҡеҜјиҮҙж•°жҚ®еә“еј•ж“Һж”ҫејғзҙўеј•иҝӣиЎҢе…ЁиЎЁжү«жҸҸ
еҰӮдёӢпјҡ
SELECT * FROM t WHERE score IS NULL дјҳеҢ–ж–№ејҸпјҡеҸҜд»Ҙз»ҷеӯ—ж®өж·»еҠ й»ҳи®ӨеҖј 0 пјҢ еҜ№ 0 еҖјиҝӣиЎҢеҲӨж–ӯ гҖӮ
еҰӮдёӢпјҡ
SELECT * FROM t WHERE score = 0 в‘Өе°ҪйҮҸйҒҝе…ҚеңЁ where жқЎд»¶дёӯзӯүеҸ·зҡ„е·Ұдҫ§иҝӣиЎҢиЎЁиҫҫејҸгҖҒеҮҪж•°ж“ҚдҪң пјҢ дјҡеҜјиҮҙж•°жҚ®еә“еј•ж“Һж”ҫејғзҙўеј•иҝӣиЎҢе…ЁиЎЁжү«жҸҸ
еҸҜд»Ҙе°ҶиЎЁиҫҫејҸгҖҒеҮҪж•°ж“ҚдҪң移еҠЁеҲ°зӯүеҸ·еҸідҫ§ пјҢ еҰӮдёӢпјҡ
-- е…ЁиЎЁжү«жҸҸ SELECT * FROM T WHERE score/10 = 9 -- иө°зҙўеј• SELECT * FROM T WHERE score = 10*9в‘ҘеҪ“ж•°жҚ®йҮҸеӨ§ж—¶ пјҢ йҒҝе…ҚдҪҝз”Ё where 1=1 зҡ„жқЎд»¶
йҖҡеёёдёәдәҶж–№дҫҝжӢјиЈ…жҹҘиҜўжқЎд»¶ пјҢ жҲ‘们дјҡй»ҳи®ӨдҪҝз”ЁиҜҘжқЎд»¶ пјҢ ж•°жҚ®еә“еј•ж“Һдјҡж”ҫејғзҙўеј•иҝӣиЎҢе…ЁиЎЁжү«жҸҸ гҖӮ
еҰӮдёӢпјҡ
SELECT username, age, sex FROM T WHERE 1=1 дјҳеҢ–ж–№ејҸпјҡз”Ёд»Јз ҒжӢјиЈ… SQL ж—¶иҝӣиЎҢеҲӨж–ӯ пјҢ жІЎ where жқЎд»¶е°ұеҺ»жҺү where пјҢ жңү where жқЎд»¶е°ұеҠ and гҖӮ
в‘ҰжҹҘиҜўжқЎд»¶дёҚиғҪз”Ё <> жҲ–иҖ… !=
дҪҝз”Ёзҙўеј•еҲ—дҪңдёәжқЎд»¶иҝӣиЎҢжҹҘиҜўж—¶ пјҢ йңҖиҰҒйҒҝе…ҚдҪҝз”Ё<>жҲ–иҖ…!=зӯүеҲӨж–ӯжқЎд»¶ гҖӮ
еҰӮзЎ®е®һдёҡеҠЎйңҖиҰҒ пјҢ дҪҝз”ЁеҲ°дёҚзӯүдәҺз¬ҰеҸ· пјҢ йңҖиҰҒеңЁйҮҚж–°иҜ„дј°зҙўеј•е»әз«Ӣ пјҢ йҒҝе…ҚеңЁжӯӨеӯ—ж®өдёҠе»әз«Ӣзҙўеј• пјҢ ж”№з”ұжҹҘиҜўжқЎд»¶дёӯе…¶д»–зҙўеј•еӯ—ж®өд»Јжӣҝ гҖӮ
⑧where жқЎд»¶д»…еҢ…еҗ«еӨҚеҗҲзҙўеј•йқһеүҚзҪ®еҲ—
еҰӮдёӢпјҡеӨҚеҗҲ(иҒ”еҗҲ)зҙўеј•еҢ…еҗ« key_part1 пјҢ key_part2 пјҢ key_part3 дёүеҲ— пјҢ дҪҶ SQL иҜӯеҸҘжІЎжңүеҢ…еҗ«зҙўеј•еүҚзҪ®еҲ—''key_part1'' пјҢ жҢүз…§ MySQL иҒ”еҗҲзҙўеј•зҡ„жңҖе·ҰеҢ№й…ҚеҺҹеҲҷ пјҢ дёҚдјҡиө°иҒ”еҗҲзҙўеј• гҖӮ
select col1 from table where key_part2=1 and key_part3=2 в‘ЁйҡҗејҸзұ»еһӢиҪ¬жҚўйҖ жҲҗдёҚдҪҝз”Ёзҙўеј•
еҰӮдёӢ SQL иҜӯеҸҘз”ұдәҺзҙўеј•еҜ№еҲ—зұ»еһӢдёә varchar пјҢ дҪҶз»ҷе®ҡзҡ„еҖјдёәж•°еҖј пјҢ ж¶үеҸҠйҡҗејҸзұ»еһӢиҪ¬жҚў пјҢ йҖ жҲҗдёҚиғҪжӯЈзЎ®иө°зҙўеј• гҖӮ
select col1 from table where col_varchar=123;в‘©order by жқЎд»¶иҰҒдёҺ where дёӯжқЎд»¶дёҖиҮҙ пјҢ еҗҰеҲҷ order by дёҚдјҡеҲ©з”Ёзҙўеј•иҝӣиЎҢжҺ’еәҸ
еҰӮдёӢпјҡ
-- дёҚиө°ageзҙўеј• SELECT * FROM t order by age; -- иө°ageзҙўеј• SELECT * FROM t where age > 0 order by age;еҜ№дәҺдёҠйқўзҡ„иҜӯеҸҘ пјҢ ж•°жҚ®еә“зҡ„еӨ„зҗҶйЎәеәҸжҳҜпјҡ
- 第дёҖжӯҘпјҡж №жҚ® where жқЎд»¶е’Ңз»ҹи®ЎдҝЎжҒҜз”ҹжҲҗжү§иЎҢи®ЎеҲ’ пјҢ еҫ—еҲ°ж•°жҚ® гҖӮ
- 第дәҢжӯҘпјҡе°Ҷеҫ—еҲ°зҡ„ж•°жҚ®жҺ’еәҸ гҖӮ еҪ“жү§иЎҢеӨ„зҗҶж•°жҚ®(order by)ж—¶ пјҢ ж•°жҚ®еә“дјҡе…ҲжҹҘзңӢ第дёҖжӯҘзҡ„жү§иЎҢи®ЎеҲ’ пјҢ зңӢ order by зҡ„еӯ—ж®өжҳҜеҗҰеңЁжү§иЎҢи®ЎеҲ’дёӯеҲ©з”ЁдәҶзҙўеј• гҖӮ еҰӮжһңжҳҜ пјҢ еҲҷеҸҜд»ҘеҲ©з”Ёзҙўеј•йЎәеәҸиҖҢзӣҙжҺҘеҸ–еҫ—е·Із»ҸжҺ’еҘҪеәҸзҡ„ж•°жҚ® гҖӮ еҰӮжһңдёҚжҳҜ пјҢ еҲҷйҮҚж–°иҝӣиЎҢжҺ’еәҸж“ҚдҪң гҖӮ
- 第дёүжӯҘпјҡиҝ”еӣһжҺ’еәҸеҗҺзҡ„ж•°жҚ® гҖӮ
жҺЁиҚҗйҳ…иҜ»













- з®ЎзҗҶиҖ…|й«ҳж°ҙе№ізҡ„з®ЎзҗҶиҖ…йғҪйҒөе®Ҳзҡ„6жқЎз®ЎзҗҶеңЈз»ҸпјҢиҜ»жҮӮиҝҷдәӣпјҢз®ЎзҗҶи¶ҠжқҘи¶ҠйЎә
- иЎҢдёҡдә’иҒ”зҪ‘|иҝҷдәӣдјҒдёҡ家зӮ№иөһвҖңйқ’жҳҘд№ӢеІӣвҖқпјҒдәҡеёғеҠӣдёӯеӣҪдјҒдёҡ家и®әеқӣеӨҸеӯЈеі°дјҡдјҒдёҡ家еә§и°ҲдјҡеңЁйқ’дёҫиЎҢ
- йҳҝйҮҢе·ҙе·ҙ|й«ҳж°ҙе№ізҡ„з®ЎзҗҶиҖ…йғҪйҒөе®Ҳзҡ„6жқЎз®ЎзҗҶеңЈз»ҸпјҢиҜ»жҮӮиҝҷдәӣпјҢз®ЎзҗҶи¶ҠжқҘи¶ҠйЎә
- AMD|еҸҲиҰҒжҖ§д»·жҜ”еҸҲиҰҒзЁіе®ҡпјҹиҝҷдәӣB450дё»жқҝз»ҷдҪ зӯ”жЎҲ
- дёӯе№ҙ|д»Җд№ҲжҳҜдҪҷеҺӢзӣ‘жҺ§зі»з»ҹпјҹдҪҷеҺӢзӣ‘жҺ§зі»з»ҹеҰӮдҪ•жҺҘзәҝе’Ңе®үиЈ…пјҹдёҖзҜҮж–Үз« жҗһжҮӮ
- жҷәиғҪз”өи§Ҷ|гҖҠд»Ҙ家дәәд№ӢеҗҚгҖӢжё©жғ…жқҘиўӯпјҢжқҘеә·еә·иҝҷдәӣз»ҶиҠӮжү“еҠЁдҪ дәҶеҗ—пјҹ
- зҫӨдј—зҪ‘|еҫ®дҝЎжү“ејҖиҝҷдёӘеҠҹиғҪпјҢиҝҷдәӣе№ҙдҪ еҺ»иҝҮзҡ„ең°ж–№йғҪиғҪзңӢеҫ—дёҖжё…дәҢжҘҡпјҒ
- дә’иҒ”зҪ‘|иҝҷдәӣдјҒдёҡиў«иҜ„дёәжҲ‘еёӮз”өеӯҗе•ҶеҠЎзӨәиҢғдјҒдёҡпјҒ
- ж·ұеңі|йҷӨдәҶи…ҫи®ҜеҚҺдёәпјҢж·ұеңіиҝҷдәӣвҖңе®қи—ҸвҖқе…¬еҸёдҪ еҫ—зҹҘйҒ“пјҒ
- 科еӯҰ|ең°зҗғдә§з”ҹз”ҹе‘Ҫе……ж»ЎдәҶе·§еҗҲпјҢиҝҷдәӣе·§еҗҲжҲ–жҳҜиў«вҖңдәәдёәвҖқеҲ»ж„Ҹе®үжҺ’зҡ„