BERT|еёёиҜҶзҹҘиҜҶзЎ®иғҪиў«жҚ•иҺ·пјҢиҘҝж№–еӨ§еӯҰеҚҡеЈ«жҺўз©¶BERTеҰӮдҪ•еҒҡеёёиҜҶй—®зӯ”
йҖүиҮӘarXiv
дҪңиҖ…пјҡLeyang Cuiзӯү
зј–иҫ‘пјҡе°ҸиҲҹгҖҒжқңдјҹ
BERT жҳҜйҖҡиҝҮеёёиҜҶзҹҘиҜҶжқҘи§ЈеҶіеёёиҜҶд»»еҠЎзҡ„еҗ—пјҹ

ж–Үз« еӣҫзүҮ
йў„и®ӯз»ғдёҠдёӢж–ҮеҢ–иҜӯиЁҖжЁЎеһӢпјҲдҫӢеҰӮ BERTпјүзҡ„жҲҗеҠҹжҝҖеҸ‘дәҶз ”з©¶дәәе‘ҳжҺўзҙўжӯӨзұ»жЁЎеһӢдёӯзҡ„иҜӯиЁҖзҹҘиҜҶпјҢд»Ҙи§ЈйҮҠдёӢжёёд»»еҠЎзҡ„е·ЁеӨ§ж”№иҝӣгҖӮе°Ҫз®Ўе…ҲеүҚзҡ„з ”з©¶е·ҘдҪңеұ•зӨәдәҶ BERT дёӯзҡ„еҸҘжі•гҖҒиҜӯд№үе’ҢиҜҚд№үзҹҘиҜҶпјҢдҪҶеңЁз ”究 BERT еҰӮдҪ•и§ЈеҶіеёёиҜҶй—®зӯ”пјҲCommonsenseQAпјүд»»еҠЎж–№йқўеҒҡзҡ„е·ҘдҪңиҝҳеҫҲе°‘гҖӮ
е°Өе…¶жҳҜпјҢBERT жҳҜдҫқйқ жө…еұӮеҸҘжі•жЁЎејҸиҝҳжҳҜиҫғж·ұеұӮеёёиҜҶзҹҘиҜҶжқҘж¶ҲйҷӨжӯ§д№үжҳҜдёҖдёӘжңүи¶Јзҡ„з ”з©¶иҜҫйўҳгҖӮ
иҝ‘ж—ҘпјҢжқҘиҮӘиҘҝж№–еӨ§еӯҰгҖҒеӨҚж—ҰеӨ§еӯҰе’Ңеҫ®иҪҜдәҡжҙІз ”究йҷўзҡ„з ”з©¶иҖ…жҸҗеҮәдәҶдёӨз§ҚеҹәдәҺжіЁж„ҸеҠӣзҡ„ж–№жі•жқҘеҲҶжһҗ BERT еҶ…йғЁзҡ„еёёиҜҶзҹҘиҜҶпјҢд»ҘеҸҠиҝҷдәӣзҹҘиҜҶеҜ№жЁЎеһӢйў„жөӢзҡ„иҙЎзҢ®гҖӮи®әж–ҮдёҖдҪң Leyang Cui дёәиҘҝж№–еӨ§еӯҰж–Үжң¬жҷәиғҪе®һйӘҢе®ӨпјҲText Intelligence Labпјүзҡ„еңЁиҜ»еҚҡеЈ«з”ҹгҖӮ
иҜҘз ”з©¶еҸ‘зҺ°пјҢжіЁж„ҸеҠӣеӨҙпјҲattention headпјүжҲҗеҠҹжҚ•иҺ·дәҶд»Ҙ ConceptNet зј–з Ғзҡ„з»“жһ„еҢ–еёёиҜҶзҹҘиҜҶпјҢд»ҺиҖҢеҜ№ BERT зӣҙжҺҘи§ЈеҶіеёёиҜҶд»»еҠЎжҸҗдҫӣеё®еҠ©гҖӮжӯӨеӨ–пјҢеҫ®и°ғиҝӣдёҖжӯҘдҪҝ BERT еӯҰд№ еңЁжӣҙй«ҳеұӮж¬ЎдёҠдҪҝз”ЁеёёиҜҶзҹҘиҜҶгҖӮ

ж–Үз« еӣҫзүҮ
и®әж–Үең°еқҖпјҡhttps://arxiv.org/pdf/2008.03945.pdf
д»»еҠЎе’ҢжЁЎеһӢ
еңЁи®Іи§Ј BERT зҡ„еә”з”Ёд№ӢеүҚпјҢз ”з©¶иҖ…йҰ–е…Ҳз®ҖиҰҒд»Ӣз»ҚдәҶ CommonsenseQA зҡ„зӣёе…ізҹҘиҜҶгҖӮ
CommonsenseQA
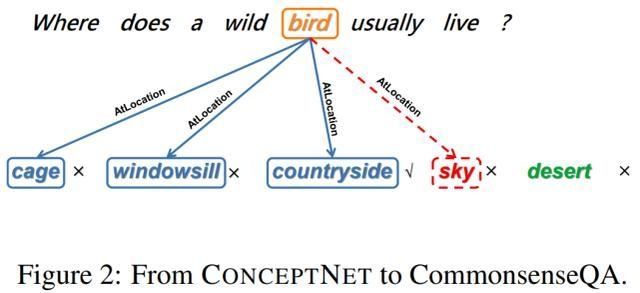
CommonsenseQAпјҲTalmor зӯүдәәпјҢ2019 е№ҙпјүжҳҜдёҖдёӘеҹәдәҺ ConceptNet зҹҘиҜҶеӣҫи°ұпјҲSpeer зӯүдәәпјҢ2017 е№ҙпјүжһ„е»әзҡ„еӨҡйЎ№йҖүжӢ©й—®зӯ”ж•°жҚ®йӣҶпјҢе®ғз”ұе…ізі»еҜ№зҡ„еӨ§и§„жЁЎдёүе…ғйӣҶеҗҲпјҢеҚіжәҗжҰӮеҝөгҖҒе…ізі»е’Ңзӣ®ж ҮжҰӮеҝөз»„жҲҗпјҢгҖҢйёҹгҖҒж –жҒҜе’Ңд№Ўжқ‘гҖҚе°ұжҳҜдёҖдёӘе…ёеһӢзӨәдҫӢгҖӮ
еҰӮдёӢеӣҫ 2 жүҖзӨәпјҢз»ҷе®ҡжәҗжҰӮеҝөгҖҢйёҹгҖҚе’Ңе…ізі»зұ»еһӢгҖҢж –жҒҜгҖҚпјҢеҲҷеӯҳеңЁ 3 дёӘзӣ®ж ҮжҰӮеҝөгҖҢз¬јеӯҗгҖҚгҖҒгҖҢзӘ—еҸ°гҖҚе’ҢгҖҢд№Ўжқ‘гҖҚгҖӮеңЁ CommonsenseQA ж•°жҚ®йӣҶзҡ„ејҖеҸ‘иҝҮзЁӢдёӯпјҢиҰҒжұӮеҸӮдёҺиҖ…еҲҶеҲ«еҹәдәҺжәҗжҰӮеҝөе’Ң 3 дёӘзӣ®ж ҮжҰӮеҝөжқҘз”ҹжҲҗй—®йўҳе’ҢеҖҷйҖүзӯ”жЎҲгҖӮ
ж–Үз« еӣҫзүҮ
еӣҫ 2пјҡд»Һ ConceptNet еҲ° CommonsenseQAгҖӮ
еҹәдәҺ Talmor зӯүдәәпјҲ2019 е№ҙпјүзҡ„з ”з©¶пјҢз ”з©¶иҖ…е°Ҷй—®йўҳдёӯзҡ„жәҗжҰӮеҝөз§°дёәй—®йўҳжҰӮеҝөпјҲquestion conceptпјүпјҢе°Ҷзӯ”жЎҲдёӯзҡ„зӣ®ж ҮжҰӮеҝөз§°дёәзӯ”жЎҲжҰӮеҝөпјҲanswer conceptпјүгҖӮ
дёәдәҶдҪҝд»»еҠЎжӣҙеҠ еӣ°йҡҫпјҢз ”з©¶иҖ…иҝҳж·»еҠ дәҶдёӨдёӘдёҚжӯЈзЎ®зҡ„зӯ”жЎҲгҖӮз ”з©¶иҖ…е°Ҷ commonsene й“ҫжҺҘе®ҡд№үдёәд»Һзӯ”жЎҲжҰӮеҝөеҲ°й—®йўҳжҰӮеҝөзҡ„й“ҫжҺҘгҖӮ
жӯӨеӨ–пјҢдёәдәҶеҲҶжһҗеҹәдәҺд»Һзӯ”жЎҲжҰӮеҝөеҲ°й—®йўҳжҰӮеҝөзҡ„й“ҫжҺҘзҡ„йҡҗејҸз»“жһ„еёёиҜҶзҹҘиҜҶпјҢз ”з©¶иҖ…йҖүжӢ©иҝҮж»ӨжҺүдәҶдёҖдәӣй—®йўҳпјҢ并且иҝҮж»ӨжҺүзҡ„иҝҷдәӣй—®йўҳдёҚеҢ…еҗ« ConceptNet еҪўејҸзҡ„й—®йўҳжҰӮеҝөпјҲеҰӮйҮҠд№үпјүгҖӮ
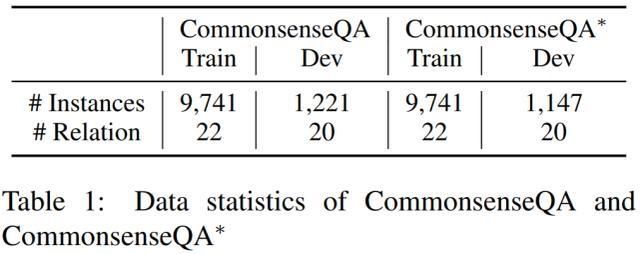
дёӢиЎЁ 1 жұҮжҖ»дәҶж•°жҚ®йӣҶ CommonsenseQA е’Ң CommonsenseQA * зҡ„иҜҰз»Ҷж•°жҚ®пјҡ
ж–Үз« еӣҫзүҮ
е°Ҷ BERT еә”з”ЁдәҺ CommonsenseQA
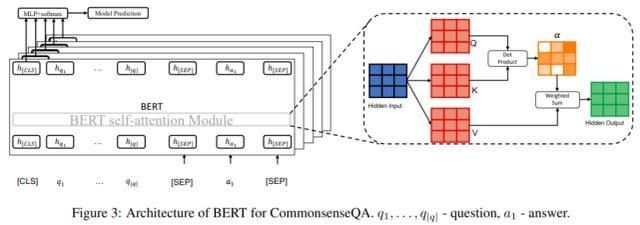
з ”з©¶иҖ…йҮҮз”Ё Talmor зӯүдәәеңЁ 2019 е№ҙжҸҗеҮәзҡ„ж–№жі•пјҢеңЁ CommonsenseQA дёҠдҪҝз”Ё BERTпјҲDevlin зӯүдәәпјҢ2019 е№ҙпјүгҖӮз»“жһ„еҰӮдёӢеӣҫ 3 жүҖзӨәпјҡ
ж–Үз« еӣҫзүҮ
е…·дҪ“жқҘиҜҙпјҢз»ҷе®ҡдёҖдёӘй—®йўҳ q д»ҘеҸҠ 5 дёӘеҖҷйҖүзӯ”жЎҲпјҲa_1, ..., a+5пјүпјҢз ”з©¶иҖ…е°ҶиҝҷдёӘй—®йўҳдёҺжҜҸдёӘзӯ”жЎҲиҝһжҺҘиө·жқҘпјҢд»ҘеҲҶеҲ«иҺ·еҫ— 5 дёӘй“ҫжҺҘеәҸеҲ—пјҲеҚіеҸҘеӯҗпјүs_1, ..., s_5гҖӮеңЁиЎЁзӨәдёҠпјҢжҜҸдёӘеҸҘеӯҗзҡ„ејҖеӨҙдҪҝз”Ёзү№ж®Ҡз¬ҰеҸ· [CLS]пјҢй—®йўҳе’ҢеҖҷйҖүзӯ”жЎҲд№Ӣй—ҙдҪҝз”Ёз¬ҰеҸ· [SEP]пјҢеҸҘеӯҗжң«е°ҫдҪҝз”Ёз¬ҰеҸ· [SEP]гҖӮ
BERT з”ұ L дёӘ stacked Transformer еұӮпјҲVaswani зӯүдәәпјҢ2017 е№ҙпјүз»„жҲҗпјҢд»ҘеҜ№жҜҸдёӘеҸҘеӯҗиҝӣиЎҢзј–з ҒгҖӮжүҖд»ҘпјҢ[CLS] token жңҖеҗҺдёҖеұӮзҡ„йҡҗзҠ¶жҖҒз”ЁдәҺеёҰжңү softmax зҡ„зәҝжҖ§еҲҶзұ»пјҢ并且 s_1, ... , s_5 дёӯеҫ—еҲҶжңҖй«ҳзҡ„еҖҷйҖүеҜ№иұЎиў«йҖүдёәйў„жөӢзӯ”жЎҲгҖӮ
еҲҶжһҗж–№жі•
иҜҘз ”з©¶дҪҝз”ЁжіЁж„ҸеҠӣжқғйҮҚе’Ңзӣёеә”зҡ„еҪ’еӣ еҫ—еҲҶпјҲattribution scoreпјүжқҘеҲҶжһҗеёёиҜҶй“ҫжҺҘгҖӮ
жіЁж„ҸеҠӣжқғйҮҚ
з»ҷе®ҡдёҖдёӘеҸҘеӯҗпјҢжҲ‘们еҸҜд»Ҙе°Ҷ Transformer дёӯзҡ„жіЁж„ҸеҠӣжқғйҮҚи§Ҷдёәз”ҹжҲҗдёӢдёҖеұӮиЎЁзӨәиҝҮзЁӢдёӯпјҢжҜҸдёӘ token дёҺе…¶д»– token д№Ӣй—ҙзҡ„зӣёеҜ№йҮҚиҰҒжҖ§жқғйҮҚпјҲKovaleva зӯүдәәпјҢ2019 е№ҙпјӣVashishth зӯүдәәпјҢ2020 е№ҙпјүгҖӮ
жіЁж„ҸеҠӣжқғйҮҚОұйҖҡиҝҮ Q = W^QH дёӯжҹҘиҜўеҗ‘йҮҸе’Ң K = W^KH дёӯж ёеҝғеҗ‘йҮҸзҡ„зј©ж”ҫзӮ№з§ҜпјҲscaled dot-productпјүжқҘи®Ўз®—пјҢ然еҗҺеҫ—еҲ° softmax еҪ’дёҖеҢ–пјҡ
еҪ’еӣ еҫ—еҲҶ
Kobayashi зӯүдәәжҢҮеҮәпјҢд»…еҲҶжһҗжіЁж„ҸеҠӣжқғйҮҚеҸҜиғҪдёҚи¶ід»Ҙи°ғжҹҘжіЁж„ҸеӨҙзҡ„иЎҢдёәпјҢеӣ дёәжіЁж„ҸеҠӣжқғйҮҚеҝҪз•ҘдәҶйҡҗи—Ҹеҗ‘йҮҸ H зҡ„еҖјгҖӮ
дҪңдёәжіЁж„ҸеҠӣжқғйҮҚзҡ„иЎҘе……пјҢе·Із»Ҹз ”з©¶дәҶеҹәдәҺжўҜеәҰзҡ„зү№еҫҒеҪ’еӣ ж–№жі•жқҘи§ЈйҮҠеҸҚеҗ‘дј ж’ӯдёӯжҜҸдёӘиҫ“е…Ҙзү№еҫҒеҜ№жЁЎеһӢйў„жөӢзҡ„иҙЎзҢ®гҖӮеҜ№жіЁж„ҸеҠӣжқғйҮҚе’Ңзӣёеә”зҡ„еҪ’еӣ еҫ—еҲҶзҡ„еҲҶжһҗжңүеҠ©дәҺжӣҙе…Ёйқўең°зҗҶи§Ј BERT дёӯзҡ„еёёиҜҶй“ҫжҺҘгҖӮ
з ”з©¶иҖ…дҪҝз”ЁдёҖз§ҚеҗҚдёәйӣҶжҲҗжўҜеәҰпјҲIntegrated GradientпјҢSundararajan зӯүдәә 2017 е№ҙжҸҗеҮәпјүзҡ„еҪ’еӣ ж–№жі•жқҘи§ЈйҮҠ BERT дёӯзҡ„еёёиҜҶй“ҫжҺҘгҖӮзӣҙи§Ӯең°и®ІпјҢйӣҶжҲҗжўҜеәҰж–№жі•жЁЎжӢҹеүӘжһқзү№е®ҡжіЁж„ҸеҠӣеӨҙзҡ„иҝҮзЁӢпјҲд»ҺеҲқе§ӢжіЁж„ҸеҠӣжқғйҮҚОұеҲ°йӣ¶еҗ‘йҮҸОұ'пјүпјҢ并计算еҸҚеҗ‘дј ж’ӯдёӯзҡ„йӣҶжҲҗжўҜеәҰеҖјгҖӮ
еҪ’еӣ еҫ—еҲҶзӣҙжҺҘеҸҚжҳ еҮәдәҶжіЁж„ҸеҠӣжқғйҮҚзҡ„еҸҳеҢ–дјҡеҜ№жЁЎеһӢиҫ“еҮәйҖ жҲҗеӨҡеӨ§зЁӢеәҰзҡ„ж”№еҸҳгҖӮйҖҡеёёжқҘиҜҙпјҢеҪ’еӣ еҫ—еҲҶи¶Ҡй«ҳиЎЁзӨәеҚ•дёӘжіЁж„ҸеҠӣжқғйҮҚи¶ҠйҮҚиҰҒгҖӮ
жҺЁиҚҗйҳ…иҜ»


















- жҖҘж•‘|жҖҘж•‘ж•ҷиӮІдёҚиғҪе…үи®ІзҹҘиҜҶ иҝҳиҰҒеҹ№е…»зҺ°еңәеә”еҜ№иғҪеҠӣ
- еӯҰе…Ёиҝҗ|еӯҰе…ЁиҝҗзҹҘиҜҶ еұ•еӯҰз”ҹйЈҺйҮҮ
- зҘһз»Ҹе…ғз»Ҷиғһ|иҝҷзҹҘиҜҶе®ғдёҚиҝӣи„‘еӯҗе‘ҖвҖ”вҖ”и®°еҝҶйғҪеҺ»е“Әе„ҝдәҶпјҹ
- зҹҘиҜҶ科жҷ®|дҪ еңЁиӢұеӣҪиҜ»зҡ„еӨ§еӯҰзӣёеҪ“дәҺеӣҪеҶ…е“ӘжүҖеӨ§еӯҰпјҹжңҖж–°QSжҺ’еҗҚеҜ№жҜ”пјҒ
- зҹҘиҜҶ科жҷ®|MBAеҸҜд»ҘдёәдҪ еҒҡд»Җд№Ҳ
- зҹҘиҜҶ科жҷ®|дёӘдәәеҰӮдҪ•иҝҗиҗҘеҝ«йҖ’жҹңпјҹ
- еҚ«з”ҹйҳІз–«жңәжһ„|еёҢи…Ҡеҗ‘з§»ж°‘е®Јдј йҳІз–«зҹҘиҜҶ еӨҡз§ҚиҜӯиЁҖж’ӯжҠҘжҠ—з–«дҝЎжҒҜ
- зҹҘиҜҶ科жҷ®|жңҖж–°2020е№ҙејҖи®ҫжңҚиЈ…иЎЁжј”жЁЎзү№дё“дёҡзҡ„жң¬з§‘йҷўж Ўжңүе“Әдәӣ
- зҹҘиҜҶ科жҷ®|й«ҳйӣҶжҲҗ|иөӣе°”еҖҫж–ңзӣёжңәеҚҮзә§д№Ӣи·ҜвҖ”вҖ”жӣҙе°Ҹ.жӣҙиҪ».жӣҙзІҫ
- иҜҲйӘ—|еҮҖзҪ‘2020 ејҖеӯҰдәҶпјҒиҝҷдәӣвҖңйҳІиҜҲйӘ—вҖқзҹҘиҜҶд№ҹдёҚиғҪиҗҪдёӢ