对象检测技术如此混乱,如何更清晰地厘清各类目标检测复杂概念
本文插图
目标检测技术的复杂程度超出我们的想象 。 始终需要将数据转换为类似COCO的JSON或其他不需要的格式 。 它从来没有即插即用的体验 。 此外 , 没有像U-Net或ResNet那样的图完全解释Faster R-CNN或YOLO , 细节太多了 。
尽管这些模型非常混乱 , 但对它们缺乏简单性的解释却很简单 。 它适合一个句子:
神经网络具有固定大小的输出
在物体检测中 , 无法先验地知道一个场景中有多少个对象 。 可能只有1个 , 2个 , 12个或没有 。 以下图像均具有相同的分辨率 , 但具有不同数量的对象 。
本文插图
本文插图
本文插图
一百万美元的问题是:如何从固定规模的网络中构建可变规模的产出?另外 , 我们应该如何训练各种损失(分类损失、边界框损失)?我们如何惩罚错误的预测?
实施可变大小的预测
为了创建大小不同的输出 , 文献中有两种方法可供使用:''一种尺寸适合所有人''方法 , 如此广泛以至于足以满足所有应用程序的输出 , 以及''超前''想法 , 我们在以下地区进行搜索:感兴趣区域 , 然后我们将其分类 。
我只是编造了这些用语 。 实际上 , 它们被称为''一阶段''和''两阶段''方法 , 这有点不言自明 。
一阶段方法
Overfeat , YOLO , SSD等
如果我们不能有可变大小的输出 , 我们将返回一个太大的输出以至于它总是大于我们需要的输出 , 那么我们可以修剪多余的输出
整个想法是走贪婪的路线 。 原始的YOLO检测器最多可以检测448x448图像的98个边界框 。 听起来很荒谬 , 确实如此 。 你自己看:
本文插图
有太多冗余的检出
真是一团糟!但是 , 您可以看到每个框都有一个百分比 。 该百分比表示算法对分类的''信心'' 。 如果我们将此阈值限制为某个值(例如50%) , 则会得到以下结果:
本文插图
设定为50%置信度的阈值效果很好
好多了!这几乎可以概括为一个阶段的方法:生成大量(但固定)的检测结果并消除混乱 , 通常将阈值和非最大抑制(NMS)混合在一起 。
这种方法因其速度快而受到高度重视 。 单个网络可以一次性处理整个图像并输出检测结果 。 时至今日 , 每当速度成为最重要的问题时 , 单级检测器就受到青睐 。
缺点是存储成本高、检测精度低 。 每个边界框消耗的内存与类的数量成正比 , 并且边界框的数量与图像分辨率成平方增长 。 当类别很多且输入分辨率高时 , 这种成本可能会非常昂贵 。 最重要的是 , 网络必须共同定位和分类对象 , 这会损害两个任务的性能 。
两阶段探测器
RCNN , Fast-RCNN , Faster-RCNN , RetinaNet等
如果我们无法获得可变大小的输出 , 那么让我们搜索感兴趣的区域并自己处理每个区域
换句话说 , 这种方法将边界框与检测结果分离 。 在第一阶段 , 该算法找出感兴趣区域 。 然后 , 我们使用专用网络对它们进行分类 。 第一阶段如下所示:
本文插图
两阶段检测器的区域建议







推荐阅读



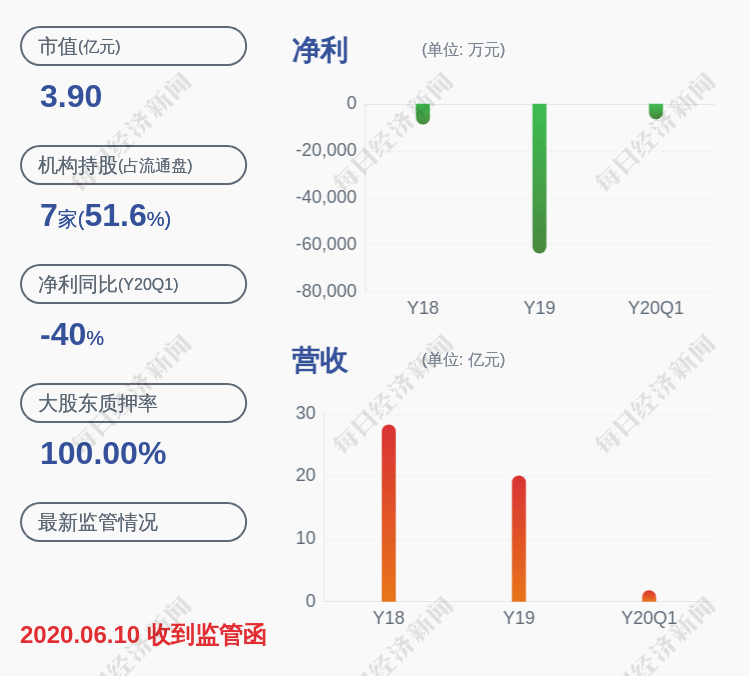












- ZAKER生活|暗打手势 是什么原因让司机如此动作?,出租司机
- 窘境|窘境中求助惨遭拒绝!中国此次也选择置之不理,俄国:早该如此
- 壹号小蘑菇|谁也没料到如此之快!网友:微信支付宝再见,四大银行正式宣布
- 支付宝|四大银行正式宣布,谁也没料到如此之快!网友:微信支付宝再见!
- 华为|华为正式宣布!花粉也没有想到,幸福来得如此之快?
- 犯罪|出租司机 暗打手势 是什么原因让司机如此动作?
- 无线充电|谁也没想到,雷军正式宣布,一切来得如此之快!
- 核潜艇|曾经是世界头号海军!现在沦落到如此程度,核潜艇都能集体感染
- 捡故事的人|冷军也不过如此,她画水堪称一绝,比照片还要真实,忍不住点赞
- 小米科技|10月19日!小米正式宣布,谁也没想到,一切竟来得如此之快!