从Bengio演讲发散开来:探讨逻辑推理与机器学习(11)
析取推理(Disjunctive reasoning):在这种推理中 , 前提是析取的 , 形式是「要么 。 或者 。 」 , 只要一个前提成立 , 结论就成立 。
合取推理(Conjunctive reasoning):在这类推理中 , 前提是连词 , 形式是「两个 。 还有 。 」 , 只有当所有前提成立时 , 结论才成立 。
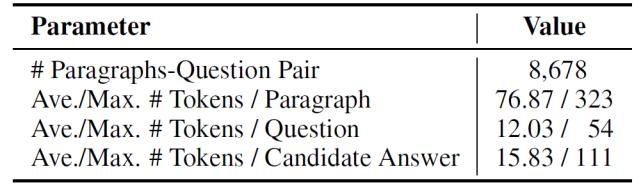
如下 , 表 1 总结了 LogiQA 的详细统计数据 。
 文章插图
文章插图
表 1. LogiQA 的统计数据
LogiQA 基准测试集由 867 个段落问题对组成 。 作者根据 Hurley 定义的逻辑推理的五种类型对实例进行人工分类[9] , 包括范畴推理、充分条件推理、必要条件推理、析取推理和合取推理 。 这些推理属于演绎推理 , 即给定一套前提条件 , 能够得出明确的结论 。 因此 , 这种推理方法最适合于定量评价性能 。 图 2 给出了 LogiQA 中推理类型的统计信息和代表性示例 。
 文章插图
文章插图
图 2. LogiQA 中每种逻辑推理的例子(红色对勾表示正确答案)
3.1.2 验证的深度学习方法介绍
作者评估了典型的应用于阅读理解任务的各类模型的性能 , 包括基于规则的方法、深度学习方法以及基于预先训练的上下文嵌入的方法 。 此外 , 还对人类直接进行阅读理解的完成情况进行了评估 , 并报告了最佳性能 。
【基于规则的方法】
作者采用了两种基于规则的方法 , 通过简单的词汇匹配给出答案 。 单词匹配 [10] 是基于规则的基线方法 , 它选择与给定段落问题对的单字格重叠程度最高的候选答案 。 滑动窗口 [11] 通过从给定段落问题对中的 n 个单词中提取 TF-IDF 类型特征来计算每个候选答案的匹配分数 。
【深度学习方法】
深度学习方法通过文本匹配技术计算给定段落、问题和每个候选答案之间的相似度 , 从而找到阅读理解的答案 。 例如 , 可以使用 LSTM 编码和双线性注意力函数计算段落问题对和候选答案之间的相似性 。 门控注意力阅读器采用多跳结构 , 具有更细粒度的机制来匹配候选答案与段落问题对 。 协同匹配网络通过对每段文本进行编码并计算每对文本之间的匹配分数 , 进一步提升段落 - 问题对和段落 - 候选答案对的匹配效果 。
【预训练方法】
与深度学习方法不同 , 预训练方法将段落、问题和每个候选答案视为一个连接句子 , 使用预先训练的上下文嵌入模型对句子进行编码以计算其得分 。 给出四个候选答案 , 将每个候选答案与段落和问题配对 , 然后构造四个连接句子 , 并选择模型得分最高的一个作为答案 。 这一类方法包括 BERT、RoBERTa 等 。
【人工方法】
本文研究团队雇佣了三名研究生进行人工方法的评估 , 并给出了从测试集中随机选取的 500 个样本的平均分数 。 在计算最优性能时 , 如果其中一个学生给出了正确的答案 , 就认为人工方法针对这个问题能够给出正确答案 。
3.1.3 实验分析
随机分割数据集 , 将其中的 80% 用于训练 , 10% 用于开发 , 其余 10% 用于测试 。 表 2 给出了节 3.1.2 中所讨论的模型的结果 。 人工方法的测试结果达到了 86.00% , 最高的结果达到 95.00% , 这说明对于人类测试者而言 , LogiQA 的难度并不大 。 相比之下 , 其它所有算法模型的性能都比人类差得多 , 这表明这些方法在逻辑推理阅读理解方面相对较弱 。 此外 , 中文数据集的结果与英文数据集的结果处于同一水平 。
两种基于规则的方法的准确率分别为 28.37% 和 22.51% , 后者甚至低于随机猜测的基线水平 。 这说明单靠词汇匹配很难解决 LogiQA 中的这些问题 。 深度学习方法的准确率在 30% 左右 , 效果要优于随机猜测的方法 , 但远远落后于人类的表现 。 一个可能的原因是这些方法都是经过端到端的训练 , 结果发现基于注意力的文本匹配很难学习潜在的逻辑推理规则 。 预先训练的模型具有一定的常识性和逻辑能力 , 与没有上下文嵌入的方法相比 , 这种模型具有更好的性能 。 然而 , RoBERTa 的最佳结果是 35.31% , 仍然远远低于人类的表现 。 这表明预先训练的模型中的知识对于逻辑推理来说是相当薄弱的 。
推荐阅读










![[利刃军事]应集体染病以获得“群体免疫”,美国专家:中国周边的美军不能隔离](https://imgcdn.toutiaoyule.com/20200406/20200406152405377637a_t.jpeg)








- AMDCES发布会1月13日凌晨0点开始:苏姿丰作主题演讲
- AMD官宣CEO苏姿丰CES演讲:锐龙5000笔记本打头阵
- 邬贺铨院士演讲权威发布: 5G商用一周年 产业创新再出发
- 马云最新演讲:过度强调管理,就升级成管控,最后成为控制
- NVIDIA GTC 2020秋季站主题演讲中文字幕版上线
- 2020世界VR产业大会云峰会演讲嘉宾 | 2018年图灵奖获得者,蒙特利尔大学教授Yoshua Bengio
- 智电网|MIDC开幕 雷军演讲,第四届小米开发者大会
- 南方PLUS|“人才日”演讲嘉宾陈宁:AI“追光者”的温暖地带
- 爱因儿科技|并提出解决方案,吴恩达演讲直指AI落地三大挑战
- 科技壹零扒|Bengio、杨强、唐剑领衔!探讨如何构建AI学术研究和产业落地的桥梁