дҪҝз”ЁеҚҠзӣ‘зқЈеӯҰд№ д»Һз ”з©¶еҲ°дә§е“ҒеҢ–зҡ„3дёӘж•ҷи®ӯ( дә” )
еҰӮжһңзұ»е№іиЎЎеҜ№SSLеңЁе®һи·өдёӯзҡ„жҲҗеҠҹиҮіе…ійҮҚиҰҒ пјҢ йӮЈд№ҲжҲ‘们еҰӮдҪ•еңЁеҚҠзӣ‘зқЈзҡ„зү©дҪ“жЈҖжөӢдёӯе®һзҺ°зұ»е№іиЎЎе‘ўпјҹжңӘжқҘи§ЈеҶіиҝҷдёҖй—®йўҳзҡ„з ”з©¶иӮҜе®ҡдјҡеҸ—еҲ°ж¬ўиҝҺ гҖӮ
е…¶д»–зҡ„дёҖдәӣTipsиҝҒ移еӯҰд№ е’ҢиҮӘи®ӯз»ғеҸ еҠ
жӯЈеҰӮеңЁZoph et al., 2020дёӯеҜ№COCOи®ӯз»ғеҸ‘зҺ°зҡ„йӮЈж · пјҢ д»ҺCOCOеҲ°жҲ‘们зҡ„ж•°жҚ®йӣҶжү§иЎҢиҪ¬з§»еӯҰд№ пјҢ 然еҗҺеңЁNoisy StudentдёӯиҝӣиЎҢиҮӘи®ӯз»ғ пјҢ еҸ–еҫ—зҡ„з»“жһңжҜ”еҚ•зӢ¬жү§иЎҢдёӨдёӘжӯҘйӘӨдёӯзҡ„д»»дҪ•дёҖдёӘйғҪиҰҒеҘҪ гҖӮ еә”з”ЁдәҺз”ҹдә§жЁЎеһӢзҡ„д»»дҪ•иҝҒ移зҹҘиҜҶеҫҲеҸҜиғҪд№ҹеҸҜд»Ҙеә”з”ЁдәҺSSLжЁЎеһӢ пјҢ еёҰжқҘеҗҢзӯүжҲ–жӣҙеӨҡзҡ„еҘҪеӨ„ гҖӮ
йҖӮеҪ“зҡ„ж•°жҚ®еўһејәеҫҲйҮҚиҰҒ
з”ұдәҺж•°жҚ®еўһејәжҳҜзҺ°д»ЈSSLж–№жі•зҡ„дё»иҰҒз»„жҲҗйғЁеҲҶ пјҢ жүҖд»ҘиҰҒзЎ®дҝқиҝҷдәӣеўһејәеҜ№дҪ зҡ„йўҶеҹҹжңүж„Ҹд№ү гҖӮ дҫӢеҰӮ пјҢ еҰӮжһңеҸҜз”Ёзҡ„жү©еұ•йӣҶеҢ…жӢ¬ж°ҙе№ізҝ»иҪ¬ пјҢ йӮЈд№Ҳи®ӯз»ғз”ЁдәҺеҢәеҲҶе·Ұз®ӯеӨҙе’ҢеҸіз®ӯеӨҙзҡ„иҫ№жЎҶзҡ„еҲҶзұ»еҷЁжҳҫ然дјҡеҸ—еҲ°еҪұе“Қ гҖӮ
жӯӨеӨ– пјҢ еңЁSTACе’ҢNoisy Studentдёӯ пјҢ 他们и§ӮеҜҹеҲ° пјҢ еңЁиҮӘи®ӯз»ғдёӯ пјҢ еҜ№ж•ҷеёҲжЁЎеһӢдҪҝз”Ёж•°жҚ®еўһејәдјҡеҜјиҮҙиҫғе·®зҡ„дёӢжёёеӯҰз”ҹжЁЎеһӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
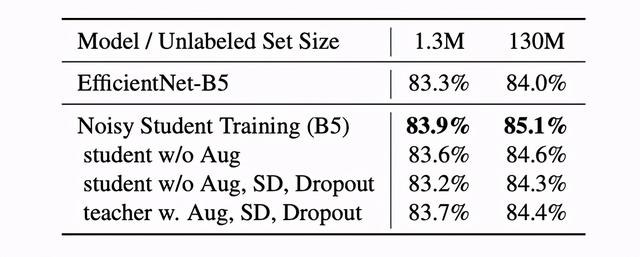
иЎЁ6жқҘиҮӘXie et al., 2019 гҖӮ еңЁиҝҷйЎ№ж¶ҲиһҚз ”з©¶дёӯ пјҢ 他们表жҳҺ пјҢ жңүеўһејәзҡ„ж•ҷеёҲжЁЎеһӢжҜ”жІЎжңүеўһејәзҡ„ж•ҷеёҲжЁЎеһӢиЎЁзҺ°з•Ҙе·®(еңЁ130MжңӘж Үи®°еӣҫеғҸдёҠ пјҢ еҲҶеҲ«дёә84.4%е’Ң85.1%) гҖӮ
然иҖҢ пјҢ жҲ‘们еҸ‘зҺ° пјҢ еңЁжҲ‘们зҡ„ж•°жҚ®йӣҶдёҠ пјҢ дҪҝз”Ёж•°жҚ®еўһејәзҡ„ж•ҷеёҲжЁЎеһӢзҡ„Noisy Studentе’ҢSTACзҡ„жҖ§иғҪдёҺдёҚдҪҝз”Ёеўһејәзҡ„ж•ҷеёҲжЁЎеһӢзӣёеҪ“жҲ–з•ҘеҘҪ гҖӮ иҷҪ然жҲ‘们зҡ„з»“жһңеҸҜиғҪжҳҜжҲ‘们иҮӘе·ұзҡ„ж•°жҚ®йӣҶзҡ„дёҖдёӘзү№дҫӢ пјҢ дҪҶжҲ‘们зӣёдҝЎиҝҷжҳҫзӨәдәҶе№ҝжіӣе®һйӘҢзҡ„йҮҚиҰҒжҖ§ пјҢ 并еҜ№дҪ еңЁи®әж–ҮдёӯиҜ»еҲ°зҡ„и§ӮзӮ№зҡ„жүҖи°“жҲҗеҠҹе’ҢеӨұиҙҘдҝқжҢҒеҘҪеҘҮ гҖӮ и®әж–ҮдёӯжҳҫзӨәзҡ„е®һиҜҒз»“жһңжҳҜдёҖдёӘеҫҲеҘҪзҡ„ејҖе§Ӣ пјҢ дҪҶжҲҗеҠҹиӮҜе®ҡжҳҜдёҚиғҪдҝқиҜҒзҡ„ пјҢ еңЁSSLдёӯд»Қжңүи®ёеӨҡд»ҺзҗҶи®әи§’еәҰе°ҡдёҚжё…жҘҡзҡ„зҗҶи§Ј гҖӮ
дёҙеҲ«иө иЁҖеңЁиҝҮеҺ»зҡ„дёҖе№ҙйҮҢ пјҢ еҚҠзӣ‘зқЈеӯҰд№ (SSL)жҳҜжҲ‘们е·ҘдҪңзҡ„дёҖдёӘд»Өдәәе…ҙеҘӢзҡ„йўҶеҹҹ пјҢ е®ғеңЁжҲ‘们зҡ„з”ҹдә§жЁЎеһӢдёӯзҡ„жңҖз»Ҳз»“жһңеҗ‘жҲ‘们(д№ҹеёҢжңӣдҪ 们жүҖжңүдәә)иЎЁжҳҺ пјҢ еңЁжҹҗдәӣжғ…еҶөдёӢеҸҜд»ҘиҖҢдё”еә”иҜҘиҖғиҷ‘SSL гҖӮ
зү№еҲ«жҳҜеңЁNoisy StudentдёӯиҝӣиЎҢиҮӘи®ӯз»ғ пјҢ еҜ№дәҺж”№иҝӣжҲ‘们зҡ„зӣ®ж ҮжЈҖжөӢжЁЎеһӢжҳҜжңүж•Ҳзҡ„ гҖӮ д»ҘдёӢжҳҜжҲ‘们еңЁз ”究е’Ңз”ҹдә§ж·ұеұӮSSLжҠҖжңҜж—¶жүҖеӯҰеҲ°зҡ„3дёӘдё»иҰҒж•ҷи®ӯпјҡ
- з®ҖеҚ•дёәзҺӢ
- дҪҝз”ЁеҗҜеҸ‘ејҸзҡ„дјӘж ҮзӯҫдјҳеҢ–жҳҜйқһеёёжңүж•Ҳзҡ„
- еҚҠзӣ‘зқЈеӣҫеғҸеҲҶзұ»зҡ„иҝӣеұ•еҫҲйҡҫиҪ¬еҢ–дёәзӣ®ж ҮжЈҖжөӢ
иӢұж–ҮеҺҹж–Үпјҡ@nairvarun18/from-research-to-production-with-deep-semi-supervised-learning-7caaedc39093
жӣҙеӨҡеҶ…е®№ пјҢ иҜ·е…іжіЁеҫ®дҝЎе…¬дј—еҸ·вҖңAIе…¬еӣӯвҖқ гҖӮ
жҺЁиҚҗйҳ…иҜ»

![[и¶Јж—…жёё]жұҹдёҠиҖҒжё”зҝҒжҢ‘зҒҜиЎҘзҪ‘пјҢжӢҚз…§жғЁйҒӯвҖңиҖҒжі•еёҲвҖқй©ұиө¶пјҢеҫҪе·һеҸӨеҹҺзҡ„жё”жўҒеққ](https://imgcdn.toutiaoyule.com/20200418/20200418100617281380a_t.jpeg)














- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- еҒҮжңҹејҜйҒ“и¶…иҪҰ еӣҪзҫҺеӯҰд№ вҖңзҘһеҷЁвҖқеҠ©еӯ©еӯҗеҸҳиә«вҖңеӯҰйңёвҖқ
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- жҲ–дҪҝз”ЁеӨ©зҺ‘1000+иҠҜзүҮпјҹиҚЈиҖҖV40е·Іе…Ёжё йҒ“ејҖеҗҜйў„зәҰ
- иӢ№жһңе°ҶжҺЁеҮәдҪҝз”Ёmini LEDеұҸзҡ„iPad Pro
- жүӢжңәиғҪз”ЁеӨҡд№…пјҹеҰӮжһңеҮәзҺ°иҝҷ3з§ҚеҫҒе…ҶпјҢиҜҙжҳҺвҖңй»ҳи®ӨдҪҝз”Ёж—¶й—ҙвҖқе·ІеҲ°
- Google AIе»әз«ӢдәҶдёҖдёӘиғҪеӨҹеҲҶжһҗзғҳз„ҷйЈҹи°ұзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢ