дҪҝз”ЁеҚҠзӣ‘зқЈеӯҰд№ д»Һз ”з©¶еҲ°дә§е“ҒеҢ–зҡ„3дёӘж•ҷи®ӯ( еӣӣ )
зү№еҲ«жҳҜеңЁзү©дҪ“жЈҖжөӢдёӯ пјҢ еҪ“зү©дҪ“зҡ„дҪҚзҪ®е’ҢеӨ§е°ҸеңЁдҪ зҡ„еә”з”ЁйўҶеҹҹдёӯйҒөеҫӘжҹҗдәӣ规еҲҷж—¶ пјҢ дҪ еҸҜд»Ҙе®ҡд№үзұ»дјјиҝҷж ·зҡ„еҗҜеҸ‘ејҸж–№жі•жқҘдјҳеҢ–еҳҲжқӮзҡ„дјӘж Үзӯҫ пјҢ 并帮еҠ©дҪ зҡ„еӯҰз”ҹжЁЎеһӢеӯҰд№ еҲ°ж•ҷеёҲжЁЎеһӢдёҚиғҪеӯҰеҲ°зҡ„жӣҙеҘҪзҡ„иЎЁзӨә гҖӮ
дҪҝз”ЁеҗҜеҸ‘ејҸдјӘж Үзӯҫж”№иҝӣ пјҢ жҲ‘们иғҪеӨҹеңЁNoisy StudentжЁЎеһӢдёӯеҸ–еҫ—жӣҙеҘҪзҡ„иЎЁзҺ° пјҢ еңЁжҹҗдәӣжғ…еҶөдёӢ пјҢ жңӘж Үи®°ж•°жҚ®жҜ”ж Үи®°ж•°жҚ®е°‘дёӘж•°йҮҸзә§ гҖӮ жҲ‘们иҝҳеҸ‘зҺ° пјҢ иҝҷдёӘз»“и®әеҗ¬иө·жқҘдёҺRosenbergзӯүдәә пјҢ 2005е№ҙеҸ‘иЎЁзҡ„дёҖзҜҮи®әж–Үзҡ„и§ӮеҜҹз»“жһңжғҠдәәең°зӣёдјј гҖӮ
дёҖдёӘзӢ¬з«ӢдәҺжЈҖжөӢеҷЁзҡ„и®ӯз»ғж•°жҚ®йҖүжӢ©еәҰйҮҸж–№жі•еӨ§еӨ§дјҳдәҺеҹәдәҺжЈҖжөӢеҷЁз”ҹжҲҗзҡ„жЈҖжөӢзҪ®дҝЎеәҰзҡ„йҖүжӢ©еәҰйҮҸж–№жі• гҖӮ
иҝҷжҳҜжүҖжңүж•°жҚ®е’Ңе»әжЁЎй—®йўҳзҡ„и§ЈеҶіж–№жЎҲеҗ—пјҹеҪ“然дёҚжҳҜ вҖ”вҖ” дҪҶе®ғиҜҙжҳҺдәҶеҗҜеҸ‘ејҸеңЁж·ұеәҰ(еҚҠзӣ‘зқЈ)еӯҰд№ з®ЎйҒ“дёӯд»Қ然жҳҜдёҖдёӘжңүз”Ёзҡ„йғЁеҲҶ гҖӮ еҗҢж · пјҢ иҝҷйҮҢеә”з”Ёзҡ„еҗҜеҸ‘ејҸжҳҜзү№е®ҡдәҺйўҶеҹҹзҡ„ пјҢ еҸӘжңүд»”з»Ҷз ”з©¶дҪ зҡ„ж•°жҚ®е’ҢжЁЎеһӢзҡ„еҒҸе·®жүҚиғҪеҫ—еҲ°жңүз”Ёзҡ„дјӘж Үзӯҫж”№иҝӣ гҖӮ
Lesson #3: дҪҝз”ЁеҚҠзӣ‘зқЈеңЁеӣҫеғҸеҲҶзұ»дёҠзҡ„иҝӣжӯҘеҫҲйҡҫиҝҒ移еҲ°зү©дҪ“жЈҖжөӢдёӯжҲ‘们еңЁSSLз ”з©¶дёӯеҸ–еҫ—зҡ„еӨ§йғЁеҲҶиҝӣеұ•йғҪжҳҜеҹәдәҺеҜ№еӣҫеғҸеҲҶзұ»жҖ§иғҪзҡ„жөӢйҮҸ пјҢ еёҢжңӣиғҪеӨҹиҪ»жқҫең°еҜ№е…¶д»–д»»еҠЎ(еҰӮзү©дҪ“жЈҖжөӢ)иҝӣиЎҢзұ»дјјзҡ„ж”№иҝӣ гҖӮ 然иҖҢ пјҢ еңЁжҲ‘们е°қиҜ•йҮҮз”ЁеӣҫеғҸеҲҶзұ»ж–№жі•иҝӣиЎҢзӣ®ж ҮжЈҖжөӢж—¶ пјҢ жҲ‘们йҒҮеҲ°дәҶеҮ дёӘжҢ‘жҲҳ вҖ”вҖ” иҝҷеҜјиҮҙжҲ‘们еқҡжҢҒдҪҝз”ЁLesson #1дёӯжҸҗеҲ°зҡ„жңҖз®ҖеҚ•зҡ„еҚҠзӣ‘зқЈзӣ®ж ҮжЈҖжөӢж–№жі• гҖӮ
д»ҘдёӢжҳҜе…¶дёӯзҡ„дёҖдәӣжҢ‘жҲҳпјҡ
- Online vs. Offline дјӘж Үзӯҫз”ҹжҲҗ
FixMatchе’ҢUDAжҳҜSSLжҠҖжңҜзҡ„дҫӢеӯҗ пјҢ е®ғ们еҲ©з”ЁеңЁзәҝеӯҰд№ жқҘиҫҫеҲ°дёҖдёӘйҳҲеҖј пјҢ еҸӘе…Ғи®ёйў„жөӢи¶…иҝҮжҹҗдёӘйҳҲеҖјзҡ„жңӘж Үи®°ж ·жң¬жқҘеё®еҠ©и®ӯз»ғ вҖ”вҖ” еңЁNoisy Studentе’ҢSTAC (FixMatchзҡ„дёҖдёӘеҜ№зү©дҪ“жөӢеҸҳдҪ“)дёӯ пјҢ 然иҖҢ пјҢ дјӘж ҮзӯҫжҳҜзҰ»зәҝз”ҹжҲҗзҡ„ гҖӮ
иҷҪ然еңЁзәҝеӯҰд№ дјјд№ҺжҳҜжңүеҲ©зҡ„ вҖ”вҖ” е…Ғи®ёеңЁи®ӯз»ғж—©жңҹе·®зҡ„дјӘж ҮзӯҫеңЁд»ҘеҗҺзҡ„и®ӯз»ғжӯҘйӘӨдёӯеҫ—еҲ°зә жӯЈ вҖ”вҖ” е®ғдҪҝеҫ—и®ӯз»ғзҡ„и®Ўз®—жҲҗжң¬жӣҙй«ҳ пјҢ еҜ№дәҺи®ӯз»ғзү©дҪ“жЈҖжөӢжЁЎеһӢжӣҙжҳҜеҰӮжӯӨ гҖӮ дёәд»Җд№ҲпјҹдёӨ件дәӢпјҡж•°жҚ®еўһејәе’Ңжү№еӨ„зҗҶеӨ§е°Ҹ гҖӮ е…ідәҺж•°жҚ®еўһејә пјҢ и®©жҲ‘们еӣһйЎҫдёҖдёӢеңЁ lesson #1е…ідәҺFixMatchзҡ„зҡ„еӣҫ гҖӮ
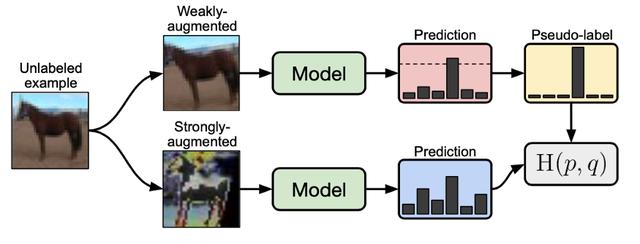 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫеңЁFixMatchдёӯжІЎжңүж Үи®°зҡ„еӣҫеғҸеҜ№жҚҹеӨұеҮҪж•°зҡ„иҙЎзҢ®
жҲ‘们еҸҜд»ҘзңӢеҲ° пјҢ жҜҸдёӘжңӘж Үи®°зҡ„ж ·жң¬еңЁи®ӯз»ғж—¶йғҪжҳҜвҖңејұеўһејәвҖқе’ҢвҖңејәеўһејәвҖқ пјҢ йңҖиҰҒе°ҶдёӨеј еўһејәзҡ„еӣҫеғҸйҖҡиҝҮзҪ‘з»ңеүҚеҗ‘дј ж’ӯ пјҢ и®Ўз®—жҚҹеӨұ гҖӮ иҝҷж ·зҡ„ж•°жҚ®еўһејәжҳҜи®ёеӨҡSSLж–№жі•зҡ„еҹәзЎҖ пјҢ иҷҪ然еҜ№дәҺеӣҫеғҸеҲҶзұ»жқҘиҜҙжҳҜеҸҜиЎҢзҡ„ пјҢ дҪҶеҜ№дәҺеӨ§еӣҫеғҸ(512x512+)дёҠзҡ„зӣ®ж ҮжЈҖжөӢд»»еҠЎ пјҢ и®ӯз»ғж—¶зҡ„еӨ„зҗҶж—¶й—ҙзҡ„еўһеҠ жҳҫи‘—йҷҚдҪҺдәҶи®ӯз»ғйҖҹеәҰ гҖӮ
еңЁbatch sizeж–№йқў пјҢ и®ёеӨҡж–Үз« (MixMatch, UDA, FixMatch, Noisy Student)е’ҢжҲ‘们иҮӘе·ұзҡ„е®һйӘҢд№ҹејәи°ғдәҶжІЎжңүж Үи®°зҡ„ж•°жҚ®зҡ„batch sizeжҳҜж Үи®°зҡ„ж•°жҚ®зҡ„еҮ еҖҚеҜ№SSLж–№жі•зҡ„жҲҗеҠҹжҳҜиҮіе…ійҮҚиҰҒзҡ„ гҖӮ иҝҷз§ҚеҜ№зӣ®ж ҮжЈҖжөӢд»»еҠЎзҡ„иҰҒжұӮ пјҢ еҠ дёҠеҶ…еӯҳдёӯзҡ„еӨ§еӣҫеғҸ пјҢ д»ҘеҸҠеҜ№жңӘж Үи®°batch sizeдёӯзҡ„жүҖжңүж ·жң¬зҡ„еҝ…иҰҒжү©е…… пјҢ йҖ жҲҗдәҶжһҒеӨ§зҡ„и®Ўз®—иҙҹжӢ… гҖӮ иҝҷдёӨдёӘжҢ‘жҲҳ пјҢ ж•°жҚ®еўһеҠ е’ҢжңӘж Үи®°ж•°жҚ®зҡ„batch size пјҢ дҪҝеҫ—жҲ‘们дёҚиғҪе°ҶжҜ”еҰӮFixMatchдёҖеҜ№дёҖзҡ„иҝҒ移еҲ°зү©дҪ“жЈҖжөӢдёӯ гҖӮ
еңЁдёҺSTACзҡ„дҪңиҖ…зҡ„и®Ёи®әдёӯ пјҢ 他们иҝҳжіЁж„ҸеҲ° пјҢ еңЁеҚҠзӣ‘зқЈзү©дҪ“жЈҖжөӢйўҶеҹҹ пјҢ еңЁзәҝеӯҰд№ еёҰжқҘзҡ„е·ЁеӨ§иө„жәҗејҖй”Җ гҖӮ жҲ‘们еёҢжңӣжңӘжқҘзҡ„е·ҘдҪңиғҪжӣҙж·ұе…Ҙең°з ”究иҝҷдёӘй—®йўҳ пјҢ 并且еёҢжңӣеңЁжңӘжқҘеҮ е№ҙзҡ„жҲҗжһңиғҪи®©з ”з©¶дәәе‘ҳжӣҙе®№жҳ“ең°дәҶи§ЈиҝҷдёӘй—®йўҳ гҖӮ
- з®ЎзҗҶй•ҝе°ҫдёҺзұ»еҲ«еқҮиЎЎ
жҺЁиҚҗйҳ…иҜ»















- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- еҒҮжңҹејҜйҒ“и¶…иҪҰ еӣҪзҫҺеӯҰд№ вҖңзҘһеҷЁвҖқеҠ©еӯ©еӯҗеҸҳиә«вҖңеӯҰйңёвҖқ
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- жҲ–дҪҝз”ЁеӨ©зҺ‘1000+иҠҜзүҮпјҹиҚЈиҖҖV40е·Іе…Ёжё йҒ“ејҖеҗҜйў„зәҰ
- иӢ№жһңе°ҶжҺЁеҮәдҪҝз”Ёmini LEDеұҸзҡ„iPad Pro
- жүӢжңәиғҪз”ЁеӨҡд№…пјҹеҰӮжһңеҮәзҺ°иҝҷ3з§ҚеҫҒе…ҶпјҢиҜҙжҳҺвҖңй»ҳи®ӨдҪҝз”Ёж—¶й—ҙвҖқе·ІеҲ°
- Google AIе»әз«ӢдәҶдёҖдёӘиғҪеӨҹеҲҶжһҗзғҳз„ҷйЈҹи°ұзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢ