дә”з§ҚIOжЁЎеһӢиҜҰи§Ј( дәҢ )
еҪ“然 пјҢ е®һзҺ°йӣ¶еӨҚеҲ¶жҠҖжңҜзҡ„ж–№жі•жңүеӨҡз§Қ пјҢ и§ҒжҲ‘зҡ„еҸҰдёҖзҜҮз»“жқҹйӣ¶еӨҚеҲ¶зҡ„ж–Үз« пјҡйӣ¶еӨҚеҲ¶(zero copy)жҠҖжңҜ гҖӮ
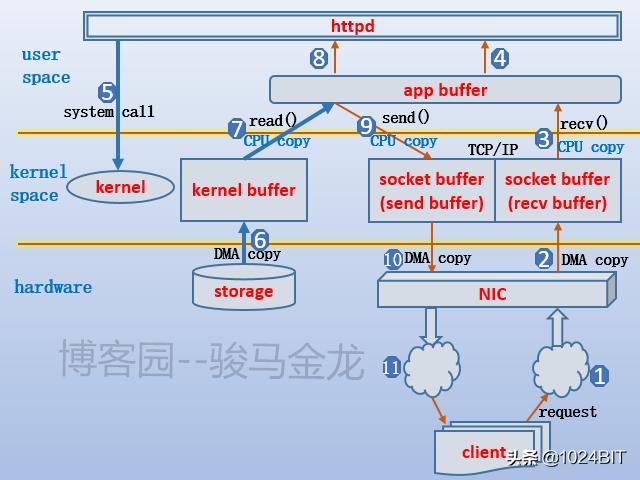
д»ҘдёӢжҳҜд»ҘhttpdиҝӣзЁӢеӨ„зҗҶж–Ү件зұ»иҜ·жұӮж—¶жҜ”иҫғе®Ңж•ҙзҡ„ж•°жҚ®ж“ҚдҪңжөҒзЁӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӨ§иҮҙи§ЈйҮҠдёӢпјҡе®ўжҲ·з«ҜеҸ‘иө·еҜ№жҹҗдёӘж–Ү件зҡ„иҜ·жұӮ пјҢ йҖҡиҝҮTCPиҝһжҺҘ пјҢ иҜ·жұӮж•°жҚ®иҝӣе…ҘTCPзҡ„recv buffer пјҢ еҶҚйҖҡиҝҮrecv()еҮҪж•°е°Ҷж•°жҚ®иҜ»е…ҘеҲ°app buffer пјҢ жӯӨж—¶httpdе·ҘдҪңиҝӣзЁӢеҜ№ж•°жҚ®иҝӣиЎҢдёҖз•Әи§Јжһҗ пјҢ зҹҘйҒ“иҜ·жұӮзҡ„жҳҜжҹҗдёӘж–Ү件 пјҢ дәҺжҳҜеҸ‘иө·readзі»з»ҹи°ғз”Ё пјҢ дәҺжҳҜеҶ…ж ёеҠ иҪҪиҜҘж–Ү件 пјҢ ж•°жҚ®д»ҺзЈҒзӣҳеӨҚеҲ¶еҲ°kernel bufferеҶҚеӨҚеҲ¶еҲ°app buffer пјҢ жӯӨж—¶httpdе°ұиҰҒејҖе§Ӣжһ„е»әе“Қеә”ж•°жҚ®дәҶ пјҢ еҸҜиғҪдјҡеҜ№ж•°жҚ®иҝӣиЎҢдёҖз•Әдҝ®ж”№ пјҢ дҫӢеҰӮеңЁе“Қеә”йҰ–йғЁдёӯеҠ дёҖдёӘеӯ—ж®ө пјҢ жңҖеҗҺе°Ҷдҝ®ж”№жҲ–жңӘдҝ®ж”№зҡ„ж•°жҚ®еӨҚеҲ¶(дҫӢеҰӮsend()еҮҪж•°)еҲ°send bufferдёӯ пјҢ еҶҚйҖҡиҝҮTCPиҝһжҺҘдј иҫ“з»ҷе®ўжҲ·з«Ҝ гҖӮ
2 I/OжЁЎеһӢжүҖи°“зҡ„IOжЁЎеһӢ пјҢ жҸҸиҝ°зҡ„жҳҜеҮәзҺ°I/Oзӯүеҫ…ж—¶иҝӣзЁӢзҡ„зҠ¶жҖҒд»ҘеҸҠеӨ„зҗҶж•°жҚ®зҡ„ж–№ејҸ гҖӮ еӣҙз»•зқҖиҝӣзЁӢзҡ„зҠ¶жҖҒгҖҒж•°жҚ®еҮҶеӨҮеҲ°kernel bufferеҶҚеҲ°app bufferзҡ„дёӨдёӘйҳ¶ж®өеұ•ејҖ гҖӮ е…¶дёӯж•°жҚ®еӨҚеҲ¶еҲ°kernel bufferзҡ„иҝҮзЁӢз§°дёәж•°жҚ®еҮҶеӨҮйҳ¶ж®ө пјҢ ж•°жҚ®д»Һkernel bufferеӨҚеҲ¶еҲ°app bufferзҡ„иҝҮзЁӢз§°дёәж•°жҚ®еӨҚеҲ¶йҳ¶ж®ө гҖӮ иҜ·и®°дҪҸиҝҷдёӨдёӘжҰӮеҝө пјҢ еҗҺйқўжҸҸиҝ°I/OжЁЎеһӢж—¶дјҡдёҖзӣҙз”ЁиҝҷдёӨдёӘжҰӮеҝө гҖӮ
жң¬ж–Үжҹҗдәӣең°ж–№д»ҘhttpdиҝӣзЁӢзҡ„TCPиҝһжҺҘж–№ејҸеӨ„зҗҶжң¬ең°ж–Ү件дёәдҫӢ пјҢ иҜ·ж— и§ҶhttpdжҳҜеҗҰзңҹзҡ„е®һзҺ°дәҶеҰӮжӯӨгҖҒйӮЈиҲ¬зҡ„еҠҹиғҪ пјҢ д№ҹиҜ·ж— и§ҶTCPиҝһжҺҘеӨ„зҗҶж•°жҚ®зҡ„з»ҶиҠӮ пјҢ иҝҷйҮҢд»…д»…еҸӘжҳҜдҪңдёәж–№дҫҝи§ЈйҮҠзҡ„зӨәдҫӢиҖҢе·І гҖӮ
еҶҚж¬ЎиҜҙжҳҺ пјҢ д»Һ硬件и®ҫеӨҮеҲ°еҶ…еӯҳзҡ„ж•°жҚ®дј иҫ“иҝҮзЁӢжҳҜдёҚйңҖиҰҒCPUеҸӮдёҺзҡ„ пјҢ иҖҢеҶ…еӯҳй—ҙдј иҫ“ж•°жҚ®жҳҜйңҖиҰҒеҶ…ж ёзәҝзЁӢеҚ з”ЁCPUжқҘеҸӮдёҺзҡ„ гҖӮ
2.1 Blocking I/OжЁЎеһӢеҰӮеӣҫпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
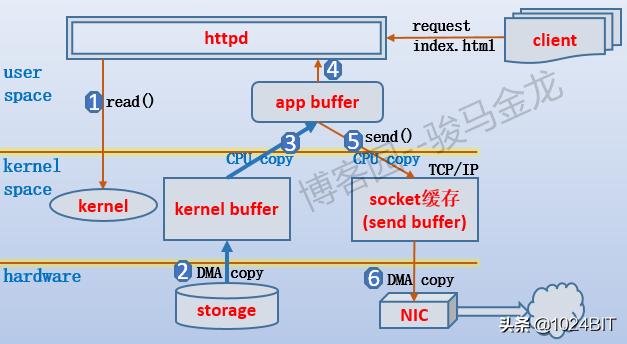
еҒҮи®ҫе®ўжҲ·з«ҜеҸ‘иө·index.htmlзҡ„ж–Ү件иҜ·жұӮ пјҢ httpdйңҖиҰҒе°Ҷindex.htmlзҡ„ж•°жҚ®д»ҺзЈҒзӣҳдёӯеҠ иҪҪеҲ°иҮӘе·ұзҡ„httpd app bufferдёӯ пјҢ 然еҗҺеӨҚеҲ¶еҲ°send bufferдёӯеҸ‘йҖҒеҮәеҺ» гҖӮ
дҪҶжҳҜеңЁhttpdжғіиҰҒеҠ иҪҪindex.htmlж—¶ пјҢ е®ғйҰ–е…ҲжЈҖжҹҘиҮӘе·ұзҡ„app bufferдёӯжҳҜеҗҰжңүindex.htmlеҜ№еә”зҡ„ж•°жҚ® пјҢ жІЎжңүе°ұеҸ‘иө·зі»з»ҹи°ғз”Ёи®©еҶ…ж ёеҺ»еҠ иҪҪж•°жҚ® пјҢ дҫӢеҰӮread() пјҢ еҶ…ж ёдјҡе…ҲжЈҖжҹҘиҮӘе·ұзҡ„kernel bufferдёӯжҳҜеҗҰжңүindex.htmlеҜ№еә”зҡ„ж•°жҚ® пјҢ еҰӮжһңжІЎжңү пјҢ еҲҷд»ҺзЈҒзӣҳдёӯеҠ иҪҪ пјҢ 然еҗҺе°Ҷж•°жҚ®еҮҶеӨҮеҲ°kernel buffer пјҢ еҶҚеӨҚеҲ¶еҲ°app bufferдёӯ пјҢ жңҖеҗҺиў«httpdиҝӣзЁӢеӨ„зҗҶ гҖӮ
еҰӮжһңдҪҝз”ЁBlocking I/OжЁЎеһӢпјҡ
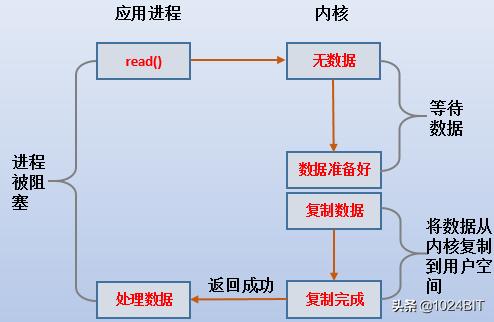
(1).еҪ“и®ҫзҪ®дёәblocking i/oжЁЎеһӢ пјҢ httpdд»ҺеҲ°йғҪжҳҜиў«йҳ»еЎһзҡ„ гҖӮ
(2).еҸӘжңүеҪ“ж•°жҚ®еӨҚеҲ¶еҲ°app bufferе®ҢжҲҗеҗҺ пјҢ жҲ–иҖ…еҸ‘з”ҹдәҶй”ҷиҜҜ пјҢ httpdжүҚиў«е”ӨйҶ’еӨ„зҗҶе®ғapp bufferдёӯзҡ„ж•°жҚ® гҖӮ
(3).cpuдјҡз»ҸиҝҮдёӨж¬ЎдёҠдёӢж–ҮеҲҮжҚўпјҡз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙеҶҚеҲ°з”ЁжҲ·з©әй—ҙ пјҢ 第дёҖж¬ЎжҳҜеҸ‘иө·зі»з»ҹи°ғз”Ёзҡ„еҲҮжҚў пјҢ 第дәҢж¬ЎжҳҜеҶ…ж ёе°Ҷж•°жҚ®жӢ·иҙқеҲ°app bufferе®ҢжҲҗеҗҺзҡ„еҲҮжҚў гҖӮ
(4).з”ұдәҺйҳ¶ж®өзҡ„жӢ·иҙқжҳҜдёҚйңҖиҰҒCPUеҸӮдёҺзҡ„ пјҢ жүҖд»ҘеңЁйҳ¶ж®өеҮҶеӨҮж•°жҚ®зҡ„иҝҮзЁӢдёӯ пјҢ cpuеҸҜд»ҘеҺ»еӨ„зҗҶе…¶е®ғиҝӣзЁӢзҡ„д»»еҠЎ гҖӮ
(5).йҳ¶ж®өзҡ„ж•°жҚ®еӨҚеҲ¶йңҖиҰҒCPUеҸӮдёҺ пјҢ е°Ҷhttpdйҳ»еЎһ гҖӮ
(6).иҝҷжҳҜжңҖзңҒдәӢгҖҒжңҖз®ҖеҚ•зҡ„IOжЁЎејҸ гҖӮ
еҰӮдёӢеӣҫпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
2.2 Non-Blocking I/OжЁЎеһӢ(1).еҪ“и®ҫзҪ®дёәnon-blockingж—¶ пјҢ httpd第дёҖж¬ЎеҸ‘иө·зі»з»ҹи°ғз”Ё(еҰӮread())еҗҺ пјҢ з«ӢеҚіиҝ”еӣһдёҖдёӘй”ҷиҜҜеҖјEWOULDBLOCK пјҢ иҖҢдёҚжҳҜи®©httpdиҝӣе…ҘзқЎзң зҠ¶жҖҒ гҖӮ UNPдёӯд№ҹжӯЈжҳҜиҝҷд№ҲжҸҸиҝ°зҡ„ гҖӮ
When we set a socket to be nonblocking, we are telling the kernel "when an I/O operation that I request cannot be completed without putting the process to sleep, do not put the process to sleep, but return an error instead.
(2).иҷҪ然read()з«ӢеҚіиҝ”еӣһдәҶ пјҢ дҪҶhttpdиҝҳиҰҒдёҚж–ӯең°еҺ»еҸ‘йҖҒread()жЈҖжҹҘеҶ…ж ёпјҡж•°жҚ®жҳҜеҗҰе·Із»ҸжҲҗеҠҹжӢ·иҙқеҲ°kernel bufferдәҶпјҹиҝҷз§°дёәиҪ®иҜў(polling) гҖӮ жҜҸж¬ЎиҪ®иҜўж—¶ пјҢ еҸӘиҰҒеҶ…ж ёжІЎжңүжҠҠж•°жҚ®еҮҶеӨҮеҘҪ пјҢ read()е°ұиҝ”еӣһй”ҷиҜҜдҝЎжҒҜEWOULDBLOCK гҖӮ
жҺЁиҚҗйҳ…иҜ»












- SatechiжҺЁеҮәDock5еӨҡи®ҫеӨҮе……з”өз«ҷ дёҖж¬ЎеҸҜеҗҢж—¶е……дә”з§Қи®ҫеӨҮ
- жһҒйҖҹйІЁиҜҫе Ӯ85пјҡжҳҫеҚЎжҖҺд№ҲжөӢиҜ• 3DMARKиҜҰи§Ј
- Google AIе»әз«ӢдәҶдёҖдёӘиғҪеӨҹеҲҶжһҗзғҳз„ҷйЈҹи°ұзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢ
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј
- OpenAIжҺЁDALL-EжЁЎеһӢпјҡиғҪж №жҚ®ж–Үеӯ—жҸҸиҝ°з”ҹжҲҗеӣҫзүҮ
- иҜҰи§Је·ҘзЁӢеёҲдёҚеҸҜдёҚдјҡзҡ„LRUзј“еӯҳж·ҳжұ°з®—жі•
- зҪ‘йҖҹеҶҚзҝ»еҖҚпјҢе®ҳж–№иҜҰи§Је°Ҹзұі 11 жҗӯиҪҪзҡ„ WiFi 6 еўһејәзүҲжҠҖжңҜ
- и°·жӯҢжҗңзҙўзҡ„зҒөйӯӮпјҒBERTжЁЎеһӢзҡ„еҙӣиө·дёҺиҚЈиҖҖ
- иӢ№жһңжҢҮеҚ—иҜҰи§ЈеҰӮжһңйҡҗз§ҒеҸ—еҲ°еЁҒиғҒпјҢеҰӮдҪ•й”Ғе®ҡiPhone
- дёҖж¬ЎжЁЎеһӢи®ӯз»ғзӣёеҪ“70дёҮе…¬йҮҢжҺ’ж”ҫйҮҸпјҹж·ұеәҰеӯҰд№ иҖ—иғҪи¶…д№ҺдҪ жғіиұЎ