дә”з§ҚIOжЁЎеһӢиҜҰи§Ј( дёү )
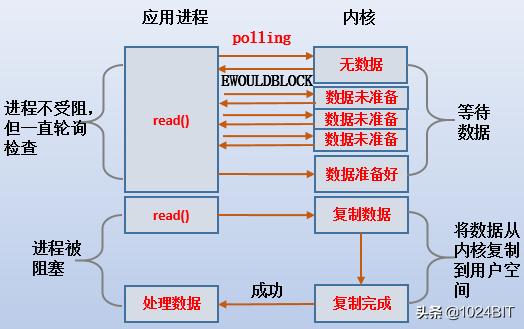
(3).зӣҙеҲ°kernel bufferдёӯж•°жҚ®еҮҶеӨҮе®ҢжҲҗ пјҢ еҶҚеҺ»иҪ®иҜўж—¶дёҚеҶҚиҝ”еӣһEWOULDBLOCK пјҢ иҖҢжҳҜе°Ҷhttpdйҳ»еЎһ пјҢ д»Ҙзӯүеҫ…ж•°жҚ®еӨҚеҲ¶еҲ°app buffer гҖӮ
(4).httpdеңЁеҲ°йҳ¶ж®өдёҚиў«йҳ»еЎһ пјҢ дҪҶжҳҜдјҡдёҚж–ӯеҺ»еҸ‘йҖҒread()иҪ®иҜў гҖӮ еңЁиў«йҳ»еЎһ пјҢ е°ҶcpuдәӨз»ҷеҶ…ж ёжҠҠж•°жҚ®copyеҲ°app buffer гҖӮ
еҰӮдёӢеӣҫпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
2.3 I/O MultiplexingжЁЎеһӢз§°дёәеӨҡи·ҜIOжЁЎеһӢжҲ–IOеӨҚз”Ё пјҢ ж„ҸжҖқжҳҜеҸҜд»ҘжЈҖжҹҘеӨҡдёӘIOзӯүеҫ…зҡ„зҠ¶жҖҒ гҖӮ жңүдёүз§ҚIOеӨҚз”ЁжЁЎеһӢпјҡselectгҖҒpollе’Ңepoll гҖӮ е…¶е®һе®ғ们йғҪжҳҜдёҖз§ҚеҮҪж•° пјҢ з”ЁдәҺзӣ‘жҺ§жҢҮе®ҡж–Ү件жҸҸиҝ°з¬Ұзҡ„ж•°жҚ®жҳҜеҗҰе°ұз»Ә гҖӮ
е°ұз»ӘжҢҮзҡ„жҳҜеҜ№жҹҗдёӘзі»з»ҹи°ғз”ЁдёҚеҶҚйҳ»еЎһдәҶ пјҢ еҸҜд»ҘзӣҙжҺҘжү§иЎҢIO гҖӮ дҫӢеҰӮеҜ№дәҺread()жқҘиҜҙ пјҢ ж•°жҚ®еҮҶеӨҮеҘҪдәҶе°ұжҳҜе°ұз»ӘзҠ¶жҖҒ пјҢ жӯӨж—¶read()еҸҜд»ҘзӣҙжҺҘеҺ»иҜ»еҸ–ж•°жҚ®дё”иғҪз«ӢеҚіиҜ»еҸ–еҲ°ж•°жҚ® пјҢ еҜ№write()жқҘиҜҙ пјҢ е°ұжҳҜжңүз©әй—ҙеҸҜд»ҘеҶҷе…Ҙж•°жҚ®дәҶ(жҜ”еҰӮзј“еҶІеҢәжңӘж»Ў) пјҢ жӯӨж—¶write()еҸҜд»ҘзӣҙжҺҘеҶҷе…Ҙ гҖӮ
е°ұз»Әз§Қзұ»еҢ…жӢ¬жҳҜеҗҰеҸҜиҜ»гҖҒжҳҜеҗҰеҸҜеҶҷд»ҘеҸҠжҳҜеҗҰејӮеёё пјҢ е…¶дёӯеҸҜиҜ»жқЎд»¶дёӯе°ұеҢ…жӢ¬дәҶж•°жҚ®жҳҜеҗҰеҮҶеӨҮеҘҪ пјҢ д№ҹеҚіж•°жҚ®жҳҜеҗҰе·Із»ҸеңЁkernel bufferдёӯ гҖӮ еҪ“е°ұз»Әд№ӢеҗҺ пјҢ е°ҶйҖҡзҹҘиҝӣзЁӢ пјҢ иҝӣзЁӢеҶҚеҸ‘йҖҒеҜ№ж•°жҚ®ж“ҚдҪңзҡ„зі»з»ҹи°ғз”Ё пјҢ еҰӮread() гҖӮ
жүҖд»Ҙ пјҢ иҝҷдёүдёӘеҮҪж•°д»…д»…еҸӘжҳҜеӨ„зҗҶдәҶж•°жҚ®жҳҜеҗҰеҮҶеӨҮеҘҪд»ҘеҸҠеҰӮдҪ•йҖҡзҹҘиҝӣзЁӢзҡ„й—®йўҳ гҖӮ еҸҜд»Ҙе°ҶиҝҷеҮ дёӘеҮҪж•°з»“еҗҲйҳ»еЎһе’Ңйқһйҳ»еЎһIOжЁЎејҸдҪҝз”Ё пјҢ дҪҶйҖҡеёёIOеӨҚз”ЁйғҪдјҡз»“еҗҲйқһйҳ»еЎһIOжЁЎејҸ гҖӮ
select()е’Ңpoll()е·®дёҚеӨҡ пјҢ е®ғ们зҡ„зӣ‘жҺ§е’ҢйҖҡзҹҘжүӢж®өжҳҜзұ»дјјзҡ„ пјҢ еҸӘдёҚиҝҮpoll()иҰҒжӣҙиҒӘжҳҺдёҖзӮ№ пјҢ жҹҗдәӣж—¶еҖҷж•ҲзҺҮд№ҹжӣҙй«ҳдәӣ пјҢ жӯӨеӨ„д»…д»Ҙselect()зӣ‘жҺ§еҚ•дёӘж–Ү件иҜ·жұӮдёәдҫӢз®ҖеҚ•д»Ӣз»ҚIOеӨҚз”Ё пјҢ иҮідәҺжӣҙе…·дҪ“зҡ„гҖҒзӣ‘жҺ§еӨҡдёӘж–Ү件д»ҘеҸҠepollзҡ„ж–№ејҸ пјҢ еңЁжң¬ж–Үзҡ„жңҖеҗҺдё“й—Ёи§ЈйҮҠ гҖӮ
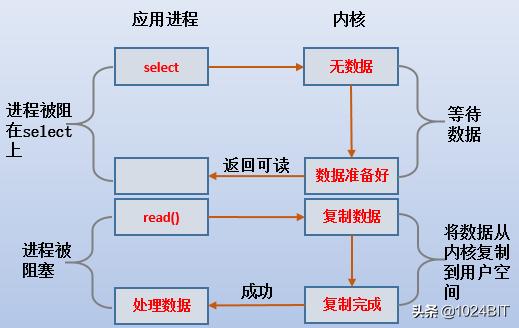
(1).еҪ“жғіиҰҒеҠ иҪҪжҹҗдёӘж–Ү件时 пјҢ еҒҮеҰӮhttpdиҰҒеҸ‘иө·read()зі»з»ҹи°ғз”Ё пјҢ еҰӮжһңжҳҜйҳ»еЎһжҲ–иҖ…йқһйҳ»еЎһжғ…еҪў пјҢ йӮЈд№Ҳread()дјҡж №жҚ®ж•°жҚ®жҳҜеҗҰеҮҶеӨҮеҘҪиҖҢеҶіе®ҡжҳҜеҗҰиҝ”еӣһ гҖӮ жҳҜеҗҰеҸҜд»Ҙдё»еҠЁеҺ»зӣ‘жҺ§иҝҷдёӘж•°жҚ®жҳҜеҗҰеҮҶеӨҮеҲ°дәҶkernel bufferдёӯе‘ў пјҢ дәҰжҲ–иҖ…жҳҜеҗҰеҸҜд»Ҙзӣ‘жҺ§send bufferдёӯжҳҜеҗҰжңүж–°ж•°жҚ®иҝӣе…Ҙе‘ўпјҹиҝҷе°ұжҳҜselect()/poll()/epollзҡ„дҪңз”Ё гҖӮ
(2).еҪ“дҪҝз”Ёselect()ж—¶ пјҢ иҝӣзЁӢиў«select()жүҖгҖҺйҳ»еЎһгҖҸ пјҢ д№ӢжүҖд»Ҙйҳ»еЎһиҰҒеҠ дёҠеј•еҸ· пјҢ жҳҜеӣ дёәselect()жңүж—¶й—ҙй—ҙйҡ”йҖүйЎ№еҸҜз”ЁжҺ§еҲ¶йҳ»еЎһж—¶й•ҝ пјҢ еҰӮжһңиҜҘйҖүйЎ№и®ҫзҪ®дёә0 пјҢ еҲҷselectдёҚйҳ»еЎһиҖҢжҳҜз«ӢеҚіиҝ”еӣһ пјҢ иҝҳеҸҜд»Ҙи®ҫзҪ®дёәж°ёд№…йҳ»еЎһ гҖӮ
(3).еҪ“select()зҡ„зӣ‘жҺ§еҜ№иұЎе°ұз»Әж—¶ пјҢ httpdиҝӣзЁӢйҖҡиҝҮиҪ®иҜўеҲӨж–ӯзҹҘйҒ“еҸҜд»Ҙжү§иЎҢread()дәҶ пјҢ дәҺжҳҜhttpdеҶҚеҸ‘иө·read()зі»з»ҹи°ғз”Ё пјҢ жӯӨж—¶ж•°жҚ®дјҡд»Һkernel bufferеӨҚеҲ¶еҲ°app bufferдёӯ并read()жҲҗеҠҹ гҖӮ
(4).httpdеҸ‘иө·read()зі»з»ҹи°ғз”ЁеҗҺеҲҮжҚўеҲ°еҶ…ж ё пјҢ з”ұеҶ…ж ёеҚ з”ЁCPUжқҘеӨҚеҲ¶ж•°жҚ®еҲ°app buffer пјҢ жүҖд»ҘhttpdиҝӣзЁӢиў«йҳ»еЎһ гҖӮ
дёҠйқўзҡ„жҸҸиҝ°еҸҜиғҪиҝҳеӨӘиҝҮжҠҪиұЎ пјҢ иҝҷйҮҢз”ЁshellдјӘд»Јз ҒжқҘз®ҖеҚ•жҸҸиҝ°select()зҡ„е·ҘдҪңж–№ејҸ(з»ҶиҠӮ并йқһеҮҶзЎ® пјҢ дҪҶжҳ“дәҺзҗҶи§Ј) гҖӮ еҒҮи®ҫжңүдёҖдёӘselectе‘Ҫд»Ө пјҢ дҪңз”Ёе’Ңselect()еҮҪж•°зӣёеҗҢ гҖӮ дјӘд»Јз ҒеҰӮдёӢпјҡ
# selectзӣ‘жҺ§жҢҮе®ҡзҡ„ж–Ү件жҸҸиҝ°з¬Ұ пјҢ 并иҝ”еӣһе·Іе°ұз»Әзҡ„жҸҸиҝ°з¬Ұж•°йҮҸз»ҷx # иҝӣзЁӢе°Ҷйҳ»еЎһеңЁselectе‘Ҫд»ӨдёҠ пјҢ зӣҙеҲ°selectиҝ”еӣһ x=$(select fd1 fd2 fd3)# еҰӮжһңxеӨ§дәҺ0 пјҢ иҜҙжҳҺжңүж–Ү件жҸҸиҝ°з¬Ұж•°жҚ®е°ұз»Ә пјҢ дәҺжҳҜйҒҚеҺҶжүҖжңүfd пјҢ# 并еҲҶеҲ«дҪҝз”ЁreadеҺ»иҜ»еҸ–иҝҷдәӣfd пјҢ дҪҶ并дёҚзҹҘйҒ“е…·дҪ“жҳҜе“ӘдёӘfdе·І # е°ұз»Ә пјҢ жүҖд»Ҙreadж—¶жңҖеҘҪжҳҜйқһйҳ»еЎһзҡ„иҜ»еҸ– пјҢ еҗҰеҲҷreadжҜҸдёҖдёӘжңӘ # е°ұз»Әзҡ„fdж—¶йғҪдјҡйҳ»еЎһ if [ x -gt 0 ];thenfor fd in fd1 fd2 fd3;doread -t 0 -u $fd# readж“ҚдҪңжңҖеҘҪжҳҜйқһйҳ»еЎһзҡ„done fiжүҖд»Ҙ пјҢ еңЁдҪҝз”ЁIOеӨҚз”ЁжЁЎеһӢж—¶ пјҢ зңҹжӯЈзҡ„IOж“ҚдҪң(жҜ”еҰӮread)жңҖеҘҪжҳҜйқһйҳ»еЎһж–№ејҸзҡ„ пјҢ дҪҶ并йқһеҝ…йЎ» гҖӮ жҜ”еҰӮеҸӘзӣ‘жҺ§дёҖдёӘж–Ү件жҸҸиҝ°з¬Ұж—¶ пјҢ selectиғҪиҝ”еӣһж„Ҹе‘ізқҖиҝҷдёӘж–Ү件жҸҸиҝ°з¬ҰдёҖе®ҡжҳҜе°ұз»Әзҡ„(selectиҝҳжңүе…¶е®ғиҝ”еӣһеҖј пјҢ дҪҶиҝҷйҮҢдёҚиҖғиҷ‘е…¶е®ғиҝ”еӣһеҖј гҖӮ
IOеӨҡи·ҜеӨҚз”Ёж—¶ пјҢ жЁЎеһӢеҰӮеӣҫпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»












- SatechiжҺЁеҮәDock5еӨҡи®ҫеӨҮе……з”өз«ҷ дёҖж¬ЎеҸҜеҗҢж—¶е……дә”з§Қи®ҫеӨҮ
- жһҒйҖҹйІЁиҜҫе Ӯ85пјҡжҳҫеҚЎжҖҺд№ҲжөӢиҜ• 3DMARKиҜҰи§Ј
- Google AIе»әз«ӢдәҶдёҖдёӘиғҪеӨҹеҲҶжһҗзғҳз„ҷйЈҹи°ұзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢ
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј
- OpenAIжҺЁDALL-EжЁЎеһӢпјҡиғҪж №жҚ®ж–Үеӯ—жҸҸиҝ°з”ҹжҲҗеӣҫзүҮ
- иҜҰи§Је·ҘзЁӢеёҲдёҚеҸҜдёҚдјҡзҡ„LRUзј“еӯҳж·ҳжұ°з®—жі•
- зҪ‘йҖҹеҶҚзҝ»еҖҚпјҢе®ҳж–№иҜҰи§Је°Ҹзұі 11 жҗӯиҪҪзҡ„ WiFi 6 еўһејәзүҲжҠҖжңҜ
- и°·жӯҢжҗңзҙўзҡ„зҒөйӯӮпјҒBERTжЁЎеһӢзҡ„еҙӣиө·дёҺиҚЈиҖҖ
- иӢ№жһңжҢҮеҚ—иҜҰи§ЈеҰӮжһңйҡҗз§ҒеҸ—еҲ°еЁҒиғҒпјҢеҰӮдҪ•й”Ғе®ҡiPhone
- дёҖж¬ЎжЁЎеһӢи®ӯз»ғзӣёеҪ“70дёҮе…¬йҮҢжҺ’ж”ҫйҮҸпјҹж·ұеәҰеӯҰд№ иҖ—иғҪи¶…д№ҺдҪ жғіиұЎ