python特征选择SelectKBest实战:期货相关特征( 二 )
(994,378)
说明又移除掉了几十个特征
- 查看移除低方差特征后 , 剩下的特征及所在的列
X_seleted_index=X_seleted.get_support(indices=True)#使用移除低方差特征后 , 留下的特征分别是第几个X_transformed_1=pd.DataFrame(X_transformed,columns=X.columns[X_seleted_index],index=data.iloc[:,0])#因为fit_transform得到的是numpy的array , #是没有index和columns的 , 所以我要手动给它添加回去!!!X_transformed_1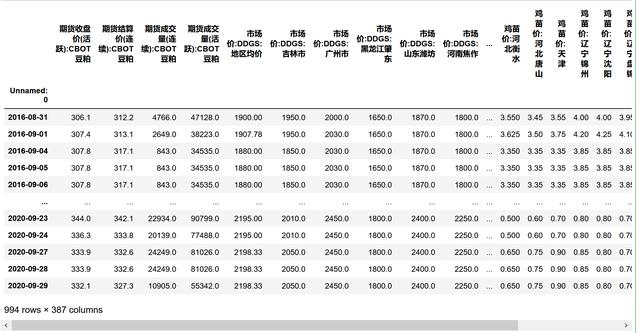 文章插图
文章插图- 使用SelectKBest , 查看每个特征与y的相关性
SKB=SelectKBest(mutual_info_regression,k=387)X_SKB=SKB.fit(X_transformed_1,y)X_SKB_transformed=SKB.fit_transform(X_transformed_1,y)X_SKB_scores=X_SKB.scores_X_SKB_scores_0=pd.DataFrame({"scores":X_SKB_scores},index=X_transformed_1.columns)X_SKB_scores_0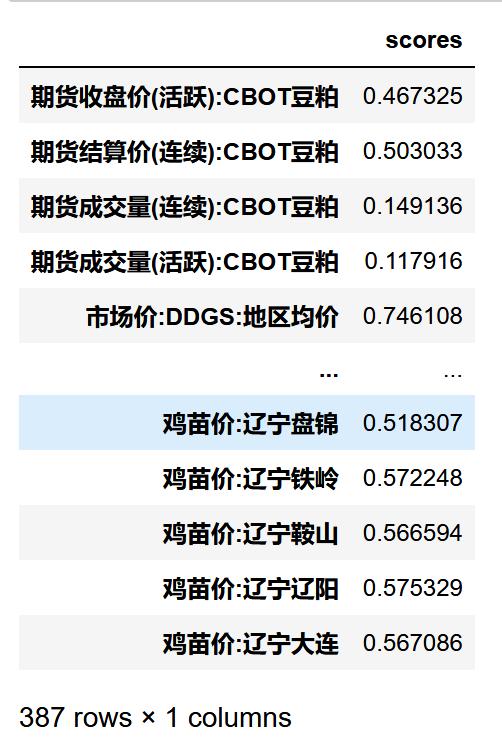 文章插图
文章插图排序
X_SKB_scores_sort=X_SKB_scores_0.sort_values(ascending=False,by="scores")X_SKB_scores_sort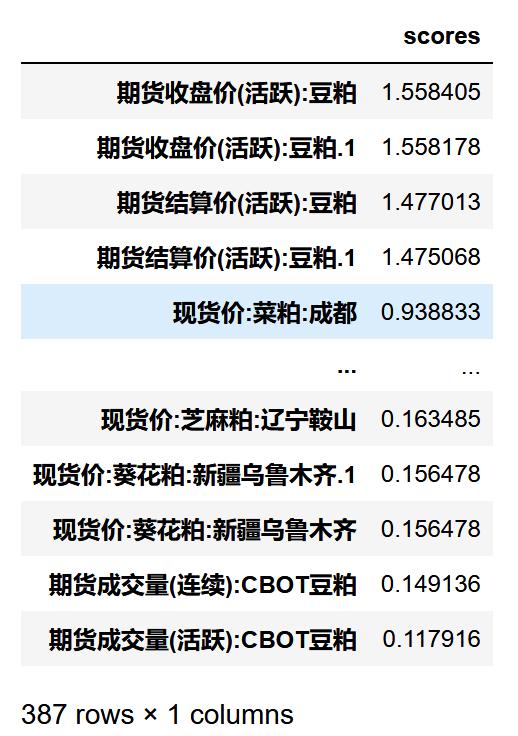 文章插图
文章插图查看相关性曲线
【python特征选择SelectKBest实战:期货相关特征】
X_SKB_scores_sort.plot()plt.xticks(range(0,400,20))plt.xlabel("index")plt.ylabel("scores")plt.show()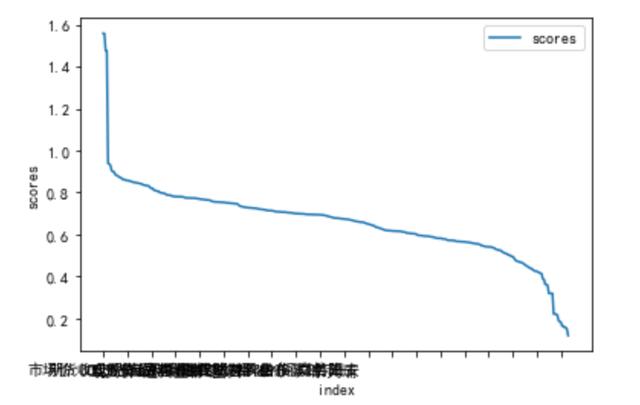 文章插图
文章插图将结果保存到csv
X_SKB_scores_sort.to_csv(r"D:\刘\预测\X_SKB_scores_sort3.csv")由图形可知 , 宜选择score在0.4到1之间的特征X_SKB_scores_seleted=X_SKB_scores_sort[(X_SKB_scores_sort["scores"]<1)&(X_SKB_scores_sort["scores"]>0.4)]print(X_SKB_scores_seleted.shape)(361,1)说明使用SelectKBest中的K取361最优
- 查看选择了特征后 , 剩下的特征及所在的列
X_SKB_seleted=pd.DataFrame(X_transformed_1,columns=X_SKB_scores_seleted.index,index=data.iloc[:,0])X_SKB_seleted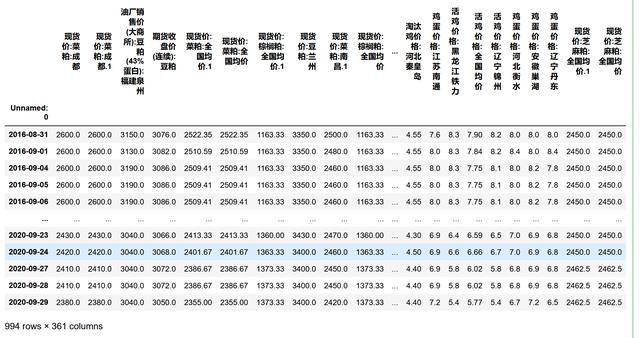 文章插图
文章插图和y合并并保存
X_SKB_seleted_Y=pd.concat((X_SKB_seleted,y),axis=1)X_SKB_seleted_Y.to_csv(r"D:\刘\预测\筛选后的特征2.csv")以上就是全部代码 , 是我实际操作过程中的经验总结 。分享不易 , 如果觉得对你有帮助 , 请帮忙点赞+收藏哦~~~
有什么不懂可以在评论区里留言~
推荐阅读


















- 计算机专业大一下学期,该选择学习Java还是Python
- Facebook向客户发邮件:对苹果隐私新规“别无选择”
- 点菜不应该只有扫码一种选择
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 团队奖就奖华为办公宝,跟着李成儒选择准没错
- ARM能否取代x86 小孩子才做选择题
- 从事Java开发时发现基础差,是否应该选择辞职自学一段时间
- 华为宣布新消息,老花粉迎来福利,Mate40不是唯一选择
- 2021年Java和Python的应用趋势会有什么变化?