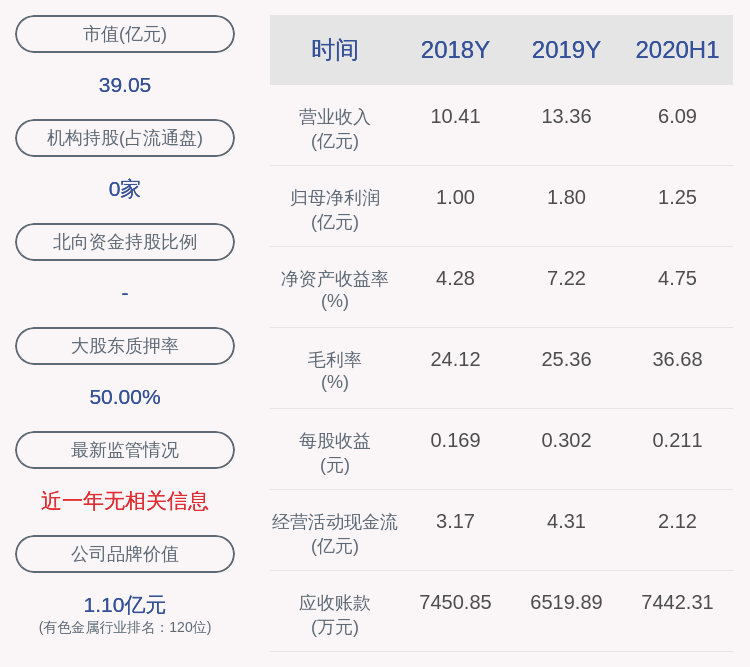
ж–Үз« жҸ’еӣҫ
иҝҷж · a е’Ң b еҸҳйҮҸе°ұдёҚдјҡеңЁеҗҢдёҖдёӘ Cache Line дёӯдәҶ пјҢ еҰӮдёӢеӣҫпјҡ

ж–Үз« жҸ’еӣҫ
жүҖд»Ҙ пјҢ йҒҝе…Қ Cache дјӘе…ұдә«е®һйҷ…дёҠжҳҜз”Ёз©әй—ҙжҚўж—¶й—ҙзҡ„жҖқжғі пјҢ жөӘиҙ№дёҖйғЁеҲҶ Cache з©әй—ҙ пјҢ д»ҺиҖҢжҚўжқҘжҖ§иғҪзҡ„жҸҗеҚҮ гҖӮ
жҲ‘们еҶҚжқҘзңӢдёҖдёӘеә”з”ЁеұӮйқўзҡ„规йҒҝж–№жЎҲ пјҢ жңүдёҖдёӘ JAVA 并еҸ‘жЎҶжһ¶ Disruptor дҪҝз”ЁгҖҢеӯ—иҠӮеЎ«е…… + 继жүҝгҖҚзҡ„ж–№ејҸ пјҢ жқҘйҒҝе…ҚдјӘе…ұдә«зҡ„й—®йўҳ гҖӮ
Disruptor дёӯжңүдёҖдёӘ RingBuffer зұ»дјҡз»Ҹеёёиў«еӨҡдёӘзәҝзЁӢдҪҝз”Ё пјҢ д»Јз ҒеҰӮдёӢпјҡ

ж–Үз« жҸ’еӣҫ
дҪ еҸҜиғҪдјҡи§үеҫ— RingBufferPad зұ»йҮҢ 7 дёӘ long зұ»еһӢзҡ„еҗҚеӯ—еҫҲеҘҮжҖӘ пјҢ дҪҶдәӢе®һдёҠ пјҢ е®ғ们иҷҪ然зңӢиө·жқҘжҜ«ж— дҪңз”Ё пјҢ дҪҶеҚҙеҜ№жҖ§иғҪзҡ„жҸҗеҚҮиө·еҲ°дәҶиҮіе…ійҮҚиҰҒзҡ„дҪңз”Ё гҖӮ
жҲ‘们йғҪзҹҘйҒ“ пјҢ CPU Cache д»ҺеҶ…еӯҳиҜ»еҸ–ж•°жҚ®зҡ„еҚ•дҪҚжҳҜ CPU Line пјҢ дёҖиҲ¬ 64 дҪҚ CPU зҡ„ CPU Line зҡ„еӨ§е°ҸжҳҜ 64 дёӘеӯ—иҠӮ пјҢ дёҖдёӘ long зұ»еһӢзҡ„ж•°жҚ®жҳҜ 8 дёӘеӯ—иҠӮ пјҢ жүҖд»Ҙ CPU дёҖдёӢдјҡеҠ иҪҪ 8 дёӘ long зұ»еһӢзҡ„ж•°жҚ® гҖӮ
ж №жҚ® JVM еҜ№иұЎз»§жүҝе…ізі»дёӯзҲ¶зұ»жҲҗе‘ҳе’Ңеӯҗзұ»жҲҗе‘ҳ пјҢ еҶ…еӯҳең°еқҖжҳҜиҝһз»ӯжҺ’еҲ—еёғеұҖзҡ„ пјҢ еӣ жӯӨ RingBufferPad дёӯзҡ„ 7 дёӘ long зұ»еһӢж•°жҚ®дҪңдёә Cache Line еүҚзҪ®еЎ«е…… пјҢ иҖҢ RingBuffer дёӯзҡ„ 7 дёӘ long зұ»еһӢж•°жҚ®еҲҷдҪңдёә Cache Line еҗҺзҪ®еЎ«е…… пјҢ иҝҷ 14 дёӘ long еҸҳйҮҸжІЎжңүд»»дҪ•е®һйҷ…з”ЁйҖ” пјҢ жӣҙдёҚдјҡеҜ№е®ғ们иҝӣиЎҢиҜ»еҶҷж“ҚдҪң гҖӮ

ж–Үз« жҸ’еӣҫ
еҸҰеӨ– пјҢ RingBufferFelds йҮҢйқўе®ҡд№үзҡ„иҝҷдәӣеҸҳйҮҸйғҪжҳҜ final дҝ®йҘ°зҡ„ пјҢ ж„Ҹе‘ізқҖ第дёҖж¬ЎеҠ иҪҪд№ӢеҗҺдёҚдјҡеҶҚдҝ®ж”№ пјҢ еҸҲз”ұдәҺгҖҢеүҚеҗҺгҖҚеҗ„еЎ«е……дәҶ 7 дёӘдёҚдјҡиў«иҜ»еҶҷзҡ„ long зұ»еһӢеҸҳйҮҸ пјҢ жүҖд»Ҙж— и®әжҖҺд№ҲеҠ иҪҪ Cache Line пјҢ иҝҷж•ҙдёӘ Cache Line йҮҢйғҪжІЎжңүдјҡеҸ‘з”ҹжӣҙж–°ж“ҚдҪңзҡ„ж•°жҚ® пјҢ дәҺжҳҜеҸӘиҰҒж•°жҚ®иў«йў‘з№Ғең°иҜ»еҸ–и®ҝй—® пјҢ е°ұиҮӘ然没жңүж•°жҚ®иў«жҚўеҮә Cache зҡ„еҸҜиғҪ пјҢ д№ҹеӣ жӯӨдёҚдјҡдә§з”ҹдјӘе…ұдә«зҡ„й—®йўҳ гҖӮ

ж–Үз« жҸ’еӣҫ
CPU еҰӮдҪ•йҖүжӢ©зәҝзЁӢзҡ„пјҹдәҶи§Је®Ң CPU иҜ»еҸ–ж•°жҚ®зҡ„иҝҮзЁӢеҗҺ пјҢ жҲ‘们еҶҚжқҘзңӢзңӢ CPU жҳҜж №жҚ®д»Җд№ҲжқҘйҖүжӢ©еҪ“еүҚиҰҒжү§иЎҢзҡ„зәҝзЁӢ гҖӮ
еңЁ Linux еҶ…ж ёдёӯ пјҢ иҝӣзЁӢе’ҢзәҝзЁӢйғҪжҳҜз”Ё tark_struct з»“жһ„дҪ“иЎЁзӨәзҡ„ пјҢ еҢәеҲ«еңЁдәҺзәҝзЁӢзҡ„ tark_struct з»“жһ„дҪ“йҮҢйғЁеҲҶиө„жәҗжҳҜе…ұдә«дәҶиҝӣзЁӢе·ІеҲӣе»әзҡ„иө„жәҗ пјҢ жҜ”еҰӮеҶ…еӯҳең°еқҖз©әй—ҙгҖҒд»Јз Ғж®өгҖҒж–Ү件жҸҸиҝ°з¬Ұзӯү пјҢ жүҖд»Ҙ Linux дёӯзҡ„зәҝзЁӢд№ҹиў«з§°дёәиҪ»йҮҸзә§иҝӣзЁӢ пјҢ еӣ дёәзәҝзЁӢзҡ„ tark_struct зӣёжҜ”иҝӣзЁӢзҡ„ tark_struct жүҝиҪҪзҡ„ иө„жәҗжҜ”иҫғе°‘ пјҢ еӣ жӯӨд»ҘгҖҢиҪ»гҖҚеҫ—еҗҚ гҖӮ
дёҖиҲ¬жқҘиҜҙ пјҢ жІЎжңүеҲӣе»әзәҝзЁӢзҡ„иҝӣзЁӢ пјҢ жҳҜеҸӘжңүеҚ•дёӘжү§иЎҢжөҒ пјҢ е®ғиў«з§°дёәжҳҜдё»зәҝзЁӢ гҖӮеҰӮжһңжғіи®©иҝӣзЁӢеӨ„зҗҶжӣҙеӨҡзҡ„дәӢжғ… пјҢ еҸҜд»ҘеҲӣе»әеӨҡдёӘзәҝзЁӢеҲҶеҲ«еҺ»еӨ„зҗҶ пјҢ дҪҶдёҚз®ЎжҖҺд№Ҳж · пјҢ е®ғ们еҜ№еә”еҲ°еҶ…ж ёйҮҢйғҪжҳҜ tark_struct гҖӮ

ж–Үз« жҸ’еӣҫ
жүҖд»Ҙ пјҢ Linux еҶ…ж ёйҮҢзҡ„и°ғеәҰеҷЁ пјҢ и°ғеәҰзҡ„еҜ№иұЎе°ұжҳҜ tark_struct пјҢ жҺҘдёӢжқҘжҲ‘们е°ұжҠҠиҝҷдёӘж•°жҚ®з»“жһ„з»ҹз§°дёәд»»еҠЎ гҖӮ
еңЁ Linux зі»з»ҹдёӯ пјҢ ж №жҚ®д»»еҠЎзҡ„дјҳе…Ҳзә§д»ҘеҸҠе“Қеә”иҰҒжұӮ пјҢ дё»иҰҒеҲҶдёәдёӨз§Қ пјҢ е…¶дёӯдјҳе…Ҳзә§зҡ„ж•°еҖји¶Ҡе°Ҹ пјҢ дјҳе…Ҳзә§и¶Ҡй«ҳпјҡ
- е®һж—¶д»»еҠЎ пјҢ еҜ№зі»з»ҹзҡ„е“Қеә”ж—¶й—ҙиҰҒжұӮеҫҲй«ҳ пјҢ д№ҹе°ұжҳҜиҰҒе°ҪеҸҜиғҪеҝ«зҡ„жү§иЎҢе®һж—¶д»»еҠЎ пјҢ дјҳе…Ҳзә§еңЁ 0~99 иҢғеӣҙеҶ…зҡ„е°ұз®—е®һж—¶д»»еҠЎпјӣ
- жҷ®йҖҡд»»еҠЎ пјҢ е“Қеә”ж—¶й—ҙжІЎжңүеҫҲй«ҳзҡ„иҰҒжұӮ пјҢ дјҳе…Ҳзә§еңЁ 100~139 иҢғеӣҙеҶ…йғҪжҳҜжҷ®йҖҡд»»еҠЎзә§еҲ«пјӣ
и°ғеәҰзұ»з”ұдәҺд»»еҠЎжңүдјҳе…Ҳзә§д№ӢеҲҶ пјҢ Linux зі»з»ҹдёәдәҶдҝқйҡңй«ҳдјҳе…Ҳзә§зҡ„д»»еҠЎиғҪеӨҹе°ҪеҸҜиғҪж—©зҡ„иў«жү§иЎҢ пјҢ дәҺжҳҜеҲҶдёәдәҶиҝҷеҮ з§Қи°ғеәҰзұ» пјҢ еҰӮдёӢеӣҫпјҡ

ж–Үз« жҸ’еӣҫ
Deadline е’Ң Realtime иҝҷдёӨдёӘи°ғеәҰзұ» пјҢ йғҪжҳҜеә”з”ЁдәҺе®һж—¶д»»еҠЎзҡ„ пјҢ иҝҷдёӨдёӘи°ғеәҰзұ»зҡ„и°ғеәҰзӯ–з•ҘеҗҲиө·жқҘе…ұжңүиҝҷдёүз§Қ пјҢ е®ғ们зҡ„дҪңз”ЁеҰӮдёӢпјҡ
- SCHED_DEADLINEпјҡжҳҜжҢүз…§ deadline иҝӣиЎҢи°ғеәҰзҡ„ пјҢ и·қзҰ»еҪ“еүҚж—¶й—ҙзӮ№жңҖиҝ‘зҡ„ deadline зҡ„д»»еҠЎдјҡиў«дјҳе…Ҳи°ғеәҰпјӣ
- SCHED_FIFOпјҡеҜ№дәҺзӣёеҗҢдјҳе…Ҳзә§зҡ„д»»еҠЎ пјҢ жҢүе…ҲжқҘе…ҲжңҚеҠЎзҡ„еҺҹеҲҷ пјҢ дҪҶжҳҜдјҳе…Ҳзә§жӣҙй«ҳзҡ„д»»еҠЎ пјҢ еҸҜд»ҘжҠўеҚ дҪҺдјҳе…Ҳзә§зҡ„д»»еҠЎ пјҢ д№ҹе°ұжҳҜдјҳе…Ҳзә§й«ҳзҡ„еҸҜд»ҘгҖҢжҸ’йҳҹгҖҚпјӣ
жҺЁиҚҗйҳ…иҜ»
- дёҖеҸЈж°”зңӢе®Ң45дёӘеҜ„еӯҳеҷЁпјҢCPUж ёеҝғжҠҖжңҜеӨ§жҸӯз§ҳ
- CPUи¶ҠжқҘи¶Ҡзғӯеҗ— дёҖж–ҮеёҰдҪ зңӢжҮӮжҖҺд№ҲйҖү
- 2020е№ҙ дҪ еҲ°еә•йңҖиҰҒд»Җд№Ҳж ·зҡ„CPUжқҘж»Ўи¶ідҪ зҡ„ж—ҘеёёдҪҝз”Ёе‘ўпјҹ
- е…ідәҺи·Ҝз”ұеҷЁзҡ„2.4Gд»ҘеҸҠ5GпјҢдҪ дёҚзҹҘйҒ“зҡ„йӮЈдәӣдәӢ
- CPUеӨ„зҗҶеҷЁ|жү“йҖ дёӢдёҖдёӘASMLпјҹиҚ·е…°жҠ•иө„77дәҝе…ғз ”еҸ‘зЎ…е…үеӯҗиҠҜзүҮжҠҖжңҜ
- CPUй’Ҳи„ҡеҜҶеҜҶйә»йә»пјҢеҮ еҚғж №й’Ҳи„ҡеқҸдәҶдёҖдёӨдёӘз«ҹ然иҝҳиғҪзӮ№дә®пјҹ
- еӣ дёәжІЎйҖүеҜ№CPUпјҢе°ҸдёҮе…ғзҡ„3080еәҹдәҶпјҒи®әз”өи„‘CPUеҰӮдҪ•йҖүиҙӯ
- i3пјҢi5пјҢi7зҡ„cpuеҲ°еә•жңүд»Җд№ҲеҢәеҲ«пјҹ
- JVMеёёи§ҒзәҝдёҠй—®йўҳ вҶ’ CPU 100%гҖҒеҶ…еӯҳжі„йңІ й—®йўҳжҺ’жҹҘ
- йғҪжҳҜиҠҜзүҮ дёәд»Җд№Ҳз”өи„‘CPUдёҚиғҪз”ЁеңЁжүӢжңәйҮҢ