
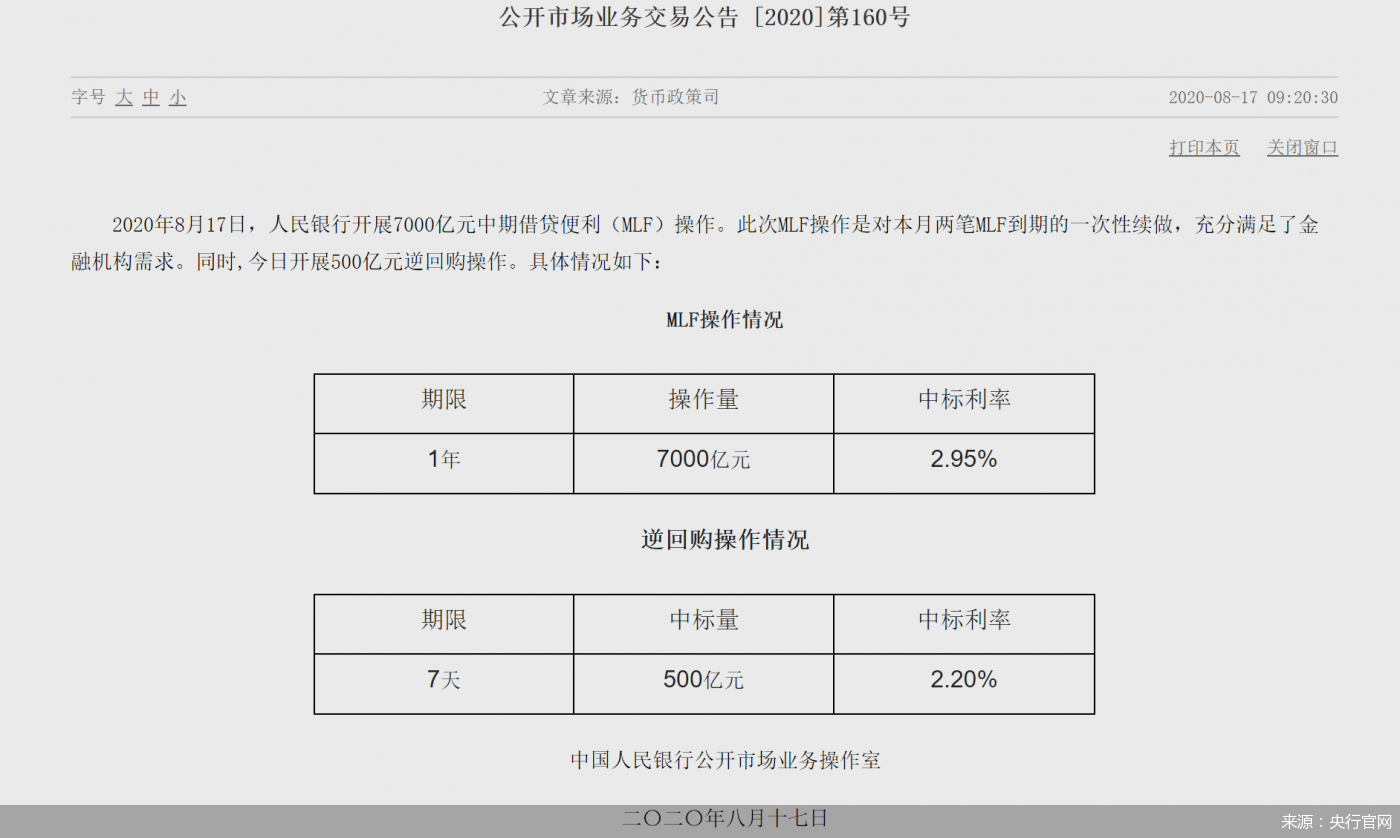
ж–Үз« жҸ’еӣҫ
дёҖиҲ¬жқҘиҜҙпјҢTerm Index йғҪжҳҜе…ЁйғЁзј“еӯҳеңЁеҶ…еӯҳдёӯпјҢжҹҘиҜўж—¶пјҢе…ҲйҖҡиҝҮе…¶еҝ«йҖҹе®ҡдҪҚеҲ° Term Dictionary еҜ№еә”зҡ„еӨ§иҮҙиҢғеӣҙпјҢ然еҗҺеҶҚиҝӣиЎҢзЈҒзӣҳиҜ»еҸ–жҹҘжүҫеҜ№еә”зҡ„ TermпјҢиҝҷж ·е°ұеӨ§еӨ§еҮҸе°‘дәҶзЈҒзӣҳ I/O зҡ„ж¬Ўж•° гҖӮ
иҒ”еҗҲзҙўеј•жҹҘиҜў
дәҶи§ЈдәҶ ElasticSearch зҡ„еҖ’жҺ’зҙўеј•еҗҺпјҢжҲ‘们еҶҚжқҘзңӢзңӢе…¶еҰӮдҪ•еӨ„зҗҶеӨҚжқӮзҡ„иҒ”еҗҲзҙўеј•жҹҘиҜў гҖӮжҜ”еҰӮдёҠиҝ°д№ҰзұҚдҫӢеӯҗдёӯпјҢжҲ‘们йңҖиҰҒжҹҘиҜўиҜ„еҲҶзӯүдәҺ2.2并且дҪңиҖ…еҗҚз§°еҸ« Tomзҡ„д№ҰзұҚ гҖӮ
зҗҶи®әдёҠпјҢжҲ‘们еҸӘйңҖиҰҒеҲҶеҲ«жҢүз…§ Score е’Ң Author еӯ—ж®өзҡ„еҖ’жҺ’зҙўеј•иҝӣиЎҢжҹҘиҜўпјҢиҺ·еҸ–е“Қеә”зҡ„ Posting ListпјҢеҶҚе°Ҷе…¶еҒҡдәӨйӣҶеҗҲ并еҚіеҸҜ гҖӮ
иҝҷйҮҢеҸҲиҰҒеҗҗж§ҪдёҖдёӢ MySQLпјҢе®ғжҳҜдёҚж”ҜжҢҒиҝҷдёӘеҗҲ并ж“ҚдҪңзҡ„пјҢе®ғеҸӘиғҪжҢүз…§дёҖдёӘеӯ—ж®өзҡ„зҙўеј•иҝӣиЎҢжҹҘиҜўпјҢ然еҗҺж №жҚ®еҸҰеӨ–дёҖдёӘеӯ—ж®өзҡ„жқЎд»¶еҒҡеҶ…еӯҳиҝҮж»Ө гҖӮйЎәдҫҝиҜҙдёҖдёӢпјҢMySQL зҡ„ join еҠҹиғҪд№ҹејұзҲҶдәҶпјҢж„ҹе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘдәҶи§ЈдёҖдёӢиҝҷзҜҮж–Үз«
иҖҢ ElasticSearch еҲҷж”ҜжҢҒдҪҝз”Ёи·іиЎЁ Skip Listе’Ң Bitset зҡ„ж–№ејҸе°Ҷж•°жҚ®йӣҶиҝӣиЎҢеҗҲ并 гҖӮ
дҪҝз”Ё Skip List з»“жһ„пјҢеҗҢж—¶йҒҚеҺҶ Score е’Ң Author жҹҘиҜўеҮәжқҘзҡ„ Posting ListпјҢеҲ©з”Ёе…¶ Skip List з»“жһ„пјҢзӣёдә’и·іи·ғеҜ№жҜ”пјҢеҫ—еҮәеҗҲйӣҶ гҖӮ
дҪҝз”Ё Bitset з»“жһ„пјҢеҜ№ Score е’Ң Author жҹҘиҜўеҮәжқҘзҡ„ Posting List зҡ„еҖји®Ўз®—еҮәеҗ„иҮӘзҡ„ BitsetпјҢ然еҗҺиҝӣиЎҢ AND ж“ҚдҪң гҖӮ
и·іиЎЁеҗҲ并зӯ–з•Ҙ
ElasticSearch еңЁеӯҳеӮЁ Posting List ж•°жҚ®ж—¶пјҢе°ұдҝқеӯҳдәҶеҜ№еә”зҡ„еӨҡзә§и·іиЎЁз»“жһ„е“Қеә”зҡ„ж•°жҚ®пјҢиҝҷд№ҹдҪ“зҺ°дәҶе…¶з©әй—ҙжҚўж—¶й—ҙзҡ„еҹәжң¬жҖқжғі гҖӮ
иҝҷйҮҢе…Ҳд»Ӣз»ҚдёҖдёӢи·іиЎЁзҡ„еҹәжң¬жҰӮеҝөпјҢе®ғе…¶е®һжҳҜдёҖз§ҚеҸҜд»ҘиҝӣиЎҢдәҢеҲҶжҹҘжүҫзҡ„жңүеәҸй“ҫиЎЁ гҖӮи·іиЎЁеңЁеҺҹжңүзҡ„жңүеәҸй“ҫиЎЁдёҠйқўеўһеҠ дәҶеӨҡзә§зҙўеј•пјҢйҖҡиҝҮзҙўеј•жқҘе®һзҺ°еҝ«йҖҹжҹҘжүҫ гҖӮйҰ–е…ҲеңЁжңҖй«ҳзә§зҙўеј•дёҠжҹҘжүҫжңҖеҗҺдёҖдёӘе°ҸдәҺеҪ“еүҚжҹҘжүҫе…ғзҙ зҡ„дҪҚзҪ®пјҢ然еҗҺеҶҚи·іеҲ°ж¬Ўй«ҳзә§зҙўеј•з»§з»ӯжҹҘжүҫпјҢзӣҙеҲ°и·іеҲ°жңҖеә•еұӮдёәжӯўпјҢйҖҡиҝҮиҝҷз§Қж–№ејҸпјҢеҠ еҝ«дәҶжҹҘиҜўзҡ„йҖҹеәҰ гҖӮ
жҜ”еҰӮпјҢжҢүз…§ Score жҹҘеҮәжқҘзҡ„ Posting List дёә[2,3,4,5,7,9,10,11]пјҢжҢүз…§ Author жҹҘеҮәжқҘзҡ„з»“жһңдёә [3,8,9,12,13]пјҢеҲҷдәҢиҖ…зҡ„и·іиЎЁз»“жһ„еҰӮдёӢеӣҫжүҖзӨә гҖӮ

ж–Үз« жҸ’еӣҫ
е…·дҪ“еҗҲ并иҝҮзЁӢеҲҷжҳҜе…ҲйҖүжңҖзҹӯзҡ„ posting listпјҢд№ҹе°ұжҳҜ Author зҡ„з»“жһңйӣҶпјҢд»Һе…¶жңҖе°Ҹзҡ„дёҖдёӘ id ејҖе§ӢпјҢе°Ҷе…¶дҪңдёәеҪ“еүҚжңҖеӨ§еҖј гҖӮ然еҗҺдҫқж¬Ўеү©дҪҷ posting list дёӯжҹҘжүҫеӨ§дәҺжҲ–зӯүдәҺиҜҘеҖјзҡ„дҪҚзҪ® гҖӮ
жҜ”еҰӮдёҠиҝ°з»“жһңйӣҶдёӯпјҢе…ҲеҺ» Score з»“жһңйӣҶдёӯжҹҘжүҫ 3пјҢжүҫеҲ°еҗҺпјҢе°ұиЎЁжҳҺ 3жҳҜдәҢиҖ…зҡ„еҗҲйӣҶе…ғзҙ д№ӢдёҖпјӣ然еҗҺеҶҚйҮҚж–°ејҖеҗҜдёҖиҪ®пјҢйҖүеҸ– Author з»“жһңйӣҶдёӯ 3 зҡ„дёӢдёҖдёӘеҖј 8пјҢеҺ» Score з»“жһңйӣҶжҹҘиҜў 8пјҢеҸ‘зҺ°дәҶеӨ§дәҺзӯүдәҺ 8 зҡ„жңҖе°Ҹзҡ„еҖјжҳҜ 9пјҢжүҖд»ҘдёҚеҸҜиғҪжңүе…ұеҗҢзҡ„еҖј 8пјҢ然еҗҺеҶҚеҺ» Author з»“жһңйӣҶжҹҘжүҫ 9пјҢеҸ‘зҺ°е…¶еӨ§дәҺзӯүдәҺ 9 зҡ„жңҖе°ҸеҖјжҳҜ 12пјҢжүҖд»ҘеҶҚеҺ» Score з»“жһңйӣҶдёӯжҹҘжүҫеӨ§дәҺзӯүдәҺ 12зҡ„еҖјпјҢеҸ‘зҺ°е№¶дёҚеӯҳеңЁпјӣжңҖз»Ҳеҫ—еҮәдәҢиҖ…зҡ„еҗҲйӣҶе°ұеҸӘжңү[3] гҖӮ
еңЁжҹҘиҜўиҝҮзЁӢдёӯпјҢжҜҸдёӘ posting list йғҪеҸҜд»Ҙж №жҚ®еҪ“еүҚ id йҖҡиҝҮ skip list еҝ«йҖҹи·іиҝҮдёҚз¬ҰеҗҲзҡ„ id еҖјпјҢеҠ йҖҹж•ҙдёӘеҗҲ并еҸ–дәӨйӣҶзҡ„иҝҮзЁӢ гҖӮ
ElasticSearch еҜ№дәҺиҫғй•ҝзҡ„ posting list д№ҹдјҡдҪҝз”Ё Frame Of Reference иҝӣиЎҢеҺӢзј©зј–з ҒпјҢеҮҸе°‘дәҶзЈҒзӣҳеҚ з”ЁпјҢеҮҸе°‘дәҶзҙўеј•е°әеҜё гҖӮжңүе…іе…·дҪ“еӯҳеӮЁз»“жһ„зҡ„е®һзҺ°жҲ‘们еҗҺз»ӯеҶҚиҝӣиЎҢз»ҶиҒҠ гҖӮ
Bitset еҗҲ并зӯ–з•Ҙ
ElasticSearchйҷӨдәҶдҪҝз”Ё skipList жқҘиҝӣиЎҢж•°жҚ®зЈҒзӣҳиҜ»еҸ–ж—¶зҡ„еҗҲ并ж“ҚдҪңеӨ–пјҢиҝҳдјҡе°ҶдёҖдәӣжҹҘиҜўжқЎд»¶еҜ№еә”зҡ„з»“жһңйӣҶ posting list иҝӣиЎҢеҶ…еӯҳзј“еӯҳпјҢд№ҹе°ұжҳҜжүҖи°“зҡ„ Filter CacheпјҢдёәдәҶеҗҺз»ӯеҶҚж¬ЎеӨҚз”Ё гҖӮ
дёәдәҶеҮҸе°‘еҶ…еӯҳзј“еӯҳжүҖж¶ҲиҖ—зҡ„еҶ…еӯҳз©әй—ҙеӨ§е°ҸпјҢElasticSearch жІЎжңүдҪҝз”ЁеҚ•зәҜзҡ„ж•°з»„е’Ң bitset жқҘеӯҳеӮЁ posting listпјҢиҖҢжҳҜдҪҝз”ЁиҰҒеҺӢзј©ж•ҲзҺҮжӣҙй«ҳзҡ„ Roaring Bitmap гҖӮ
жҲ‘们еҸҜд»Ҙе…ҲжқҘи®ІдёҖдёӢеҚ•зәҜж•°з»„жҲ– bitset ж•°жҚ®з»“жһ„дёәд»Җд№Ҳ并дёҚдҪҝз”Ё гҖӮжҜ”еҰӮеҰӮдёӢдёҖйҒ“иҫғдёәеёёи§Ғзҡ„йқўиҜ•йўҳзӣ®пјҡ
з»ҷе®ҡеҗ«жңү40дәҝдёӘдёҚйҮҚеӨҚзҡ„дҪҚдәҺ[0, 2^32 - 1]еҢәй—ҙеҶ…зҡ„ж•ҙж•°зҡ„йӣҶеҗҲпјҢеҰӮдҪ•еҝ«йҖҹеҲӨе®ҡжҹҗдёӘж•°жҳҜеҗҰеңЁиҜҘйӣҶеҗҲеҶ…пјҹ
еҰӮжһңжҲ‘们иҰҒдҪҝз”Ё unsigned long ж•°з»„жқҘеӯҳеӮЁе®ғзҡ„иҜқпјҢд№ҹе°ұйңҖиҰҒж¶ҲиҖ— 40дәҝ * 32 дҪҚ = 160 ByteпјҢеӨ§иҮҙжҳҜ 16000 MB гҖӮ
еҰӮжһңиҰҒдҪҝз”ЁдҪҚеӣҫ Bitset жқҘеӯҳеӮЁзҡ„иҜқпјҢеҚіжҹҗдёӘж•°дҪҚдәҺеҺҹйӣҶеҗҲеҶ…пјҢе°ұе°Ҷе®ғеҜ№еә”зҡ„дҪҚеӣҫеҶ…зҡ„жҜ”зү№зҪ®дёә1пјҢеҗҰеҲҷдҝқжҢҒдёә0 гҖӮиҝҷж ·еҸӘйңҖиҰҒж¶ҲиҖ— 2 ^ 32 дҪҚ = 512 MBпјҢиҝҷеҸҜеҸӘжңүеҺҹжқҘзҡ„ 3.2 % е·ҰеҸі гҖӮ
дҪҶжҳҜпјҢBitset д№ҹжңүе…¶зјәйҷ·пјҢд№ҹе°ұжҳҜзЁҖз–ҸеӯҳеӮЁзҡ„й—®йўҳпјҢжҜ”еҰӮдёҠиҝ°йӣҶеҗҲ并дёҚжҳҜ 40дәҝпјҢиҖҢжҳҜеҸӘжңү2пјҢ3дёӘпјҢйӮЈд№Ҳ Bitset дёӯеҸӘжңүе°‘ж•°еҮ дҪҚжҳҜ1пјҢе…¶д»–дҪҚйғҪжҳҜ 0пјҢдҪҶжҳҜе®ғд»Қ然еҚ з”ЁдәҶ 512 MB гҖӮ
иҖҢ RoaringBitmap е°ұжҳҜдёәдәҶи§ЈеҶізЁҖз–ҸеӯҳеӮЁзҡ„й—®йўҳ гҖӮдёӢеӣҫе°ұжҳҜ RoaringBitmap зҡ„еҹәжң¬еҺҹзҗҶзӨәж„Ҹеӣҫ гҖӮ

ж–Үз« жҸ’еӣҫ
йҰ–е…ҲпјҢеҰӮдёҠеӣҫжүҖзӨәпјҢи®Ўз®—еҮә32дҪҚж— з¬ҰеҸ·ж•ҙж•°е’Ң 65536 зҡ„йҷӨж•°е’ҢдҪҷж•° гҖӮе…¶еҗ«д№үиЎЁзӨәпјҢе°Ҷ32дҪҚж— з¬ҰеҸ·ж•ҙж•°жҢүз…§й«ҳ16дҪҚеҲҶжЎ¶пјҢеҚіжңҖеӨҡеҸҜиғҪжңү2^16=65536дёӘжЎ¶пјҢжңҜиҜӯжғ©жІ»дёә container гҖӮеӯҳеӮЁж•°жҚ®ж—¶пјҢжҢүз…§ж•°жҚ®зҡ„й«ҳ16дҪҚжүҫеҲ° containerпјҲжүҫдёҚеҲ°е°ұдјҡж–°е»әдёҖдёӘпјүпјҢеҶҚе°ҶдҪҺ16дҪҚж”ҫе…Ҙcontainerдёӯ гҖӮд№ҹе°ұжҳҜиҜҙпјҢдёҖдёӘ RoaringBitmap е°ұжҳҜеҫҲеӨҡcontainerзҡ„йӣҶеҗҲ гҖӮ
жҺЁиҚҗйҳ…иҜ»













- еҖјеҫ—зҺ°еңЁе°ұеҺ»е°қиҜ•зҡ„еӣӣж¬ҫејҖжәҗиҒҠеӨ©еә”з”ЁиҪҜ件
- SpringBootдәӢ件зӣ‘еҗ¬пјҡеә”з”Ёзӣ‘еҗ¬жҺҘеҸЈзҡ„дҪҝз”Ё
- дёҚзҲұи·іж§Ҫзҡ„зЁӢеәҸе‘ҳйӣҶдёӯеңЁ8-17kпјҢжҸӯжҷ“дёӯеӣҪејҖеҸ‘иҖ…зҡ„зңҹе®һзҺ°зҠ¶
- 2020е№ҙдҪіеЈ«еҫ—жӢҚеҚ–йў„еұ• дҪіеЈ«еҫ—еңЁзәҝиүәжңҜе“ҒжӢҚеҚ–
- еҚҒеӨ§з§‘еӯҰжңӘи§Јд№Ӣи°ң 科еӯҰ家жңүдёүеӨ§жңӘи§Јд№Ӣи°ң
- з”өеҪұзғӯеёҰйӣЁжһ—еҺҶйҷ©и®° зғӯеёҰйӣЁжһ—еҺҶйҷ©з”өеҪұ
- й»‘жҙһдә’зӣёеҗһеҷ¬ й»‘жҙһдјҡеҗһеҷ¬еӨӘйҳіеҗ—
- еҫ®дҝЎжӯЈеңЁз”Ёзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶ејҖжәҗпјҒж”ҜжҢҒзЁҖз–Ҹеј йҮҸпјҢеҹәдәҺC++ејҖеҸ‘
- windowsеҹҹиҪҜ件дёӢеҸ‘зӯ–з•Ҙ
- дёүи§’йҫҷзҡ„еҢ–зҹіжҳҜеңЁе“ӘйҮҢеҸ‘зҺ°зҡ„ зңҹжӯЈзҡ„жҒҗйҫҷиӣӢеҢ–зҹіеӣҫзүҮ