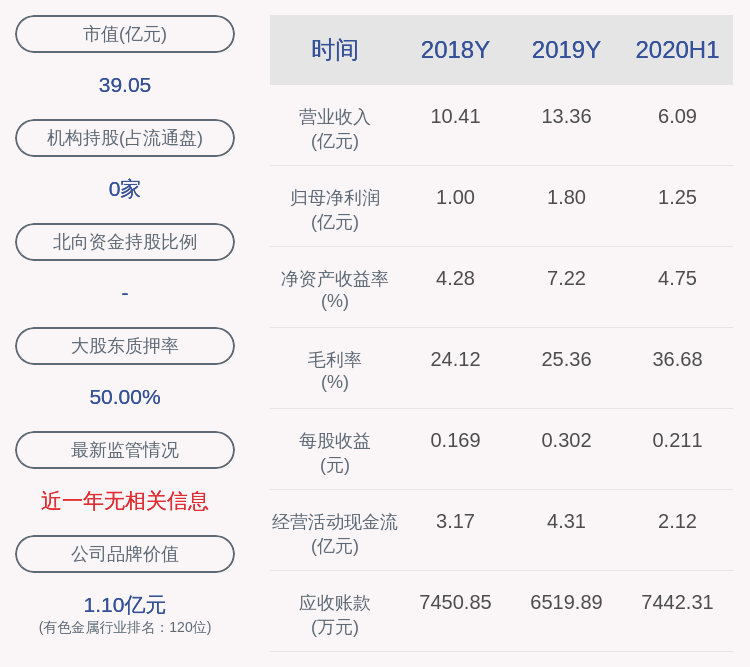
alive.onoff = TRUE;alive.keepalivetime = vhost->ka_time*1000;alive.keepaliveinterval = vhost->ka_interval*1000;if (WSAIoctl(fd, SIO_KEEPALIVE_VALS, &alive, sizeof(alive),, 0, &dwBytesRet, , ))return 1;}/* Disable Nagle */optval = 1;#ifndef _WIN32_WCEtcp_proto = getprotobyname("TCP");if (!tcp_proto) {lwsl_err("getprotobyname failed with error %dn", LWS_ERRNO);return 1;}protonbr = tcp_proto->p_proto;#elseprotonbr = 6;#endifsetsockopt(fd, protonbr, TCP_NODELAY, (const char *)&optval, optlen);/* We are nonblocking... */ioctlsocket(fd, FIONBIO, &optl);return 0;}
жүҖд»Ҙlibwebsocketsеә“зҡ„еҝғи·іи®ҫзҪ® пјҢ дҪҝз”Ёзҡ„иҝҳжҳҜTCPIPеҚҸи®®ж Ҳзҡ„еҝғи·і пјҢ дёҚжҳҜеә”з”ЁеұӮиҮӘе·ұе®һзҺ°зҡ„еҝғи·іжңәеҲ¶ гҖӮ
е…ідәҺTCPIPеҚҸи®®ж Ҳзҡ„дёүдёӘеҝғи·іеҸӮж•°зҡ„иҜҰз»ҶиҜҙжҳҺеҰӮдёӢпјҡ
пјҲ1пјүkeepalivetimeпјҡеҝғи·іжӯЈеёёж—¶ пјҢ жң¬з«ҜеҸ‘йҖҒдёҖдёӘеҝғи·іеҢ…з»ҷеҜ№з«Ҝ пјҢ 收еҲ°еҜ№з«Ҝеҝғи·іеҢ…зҡ„еӣһеә” пјҢ й—ҙйҡ”keepalivetimeж—¶й—ҙеҗҺ пјҢ еҸ‘дёӢдёҖеҢ…еҝғи·іеҢ… пјҢ windowsй»ҳи®Өзҡ„еҝғи·іеҢ…еҸ‘йҖҒй—ҙйҡ”жҳҜ2е°Ҹж—¶ гҖӮпјҲ2пјүkeepaliveintervalпјҡеҝғи·іејӮеёёж—¶ пјҢ жң¬з«ҜеҸ‘йҖҒеҝғи·іеҢ…еҗҺ没收еҲ°еҜ№з«Ҝзҡ„еӣһеә” пјҢ й—ҙйҡ”keepaliveintervalж—¶й—ҙеҗҺ пјҢ еҸ‘йҖҒдёӢдёҖдёӘеҝғи·іеҢ…пјҲ继з»ӯжҺўжөӢпјү гҖӮеҰӮжһңеӨҡж¬ЎжІЎжңү收еҲ°еҜ№з«Ҝзҡ„еӣһеә” пјҢ еҪ“жҺўжөӢж¬Ўж•°иҫҫеҲ°дёҠйҷҗпјҲkeep-alive probesпјүж—¶ пјҢ еҲҷеҚҸи®®ж Ҳи®ӨдёәиҝһжҺҘеҮәй—®йўҳ гҖӮпјҲ3пјүkeep-alive probesпјҡwindowsзі»з»ҹдёӯ пјҢ еҝғи·іеҢ…жҺўжөӢж¬Ўж•°keep-alive probesжҳҜдёҚеҸҜж”№еҸҳзҡ„ пјҢ еҚҸи®®ж Ҳеӣәе®ҡдёә10ж¬Ў гҖӮ
7гҖҒеңЁеӨҚжқӮзҪ‘з»ңзҺҜеўғдёӯдё»д»ҺжңҚеҠЎеҷЁеҲҮжҚўж—¶йҒҮеҲ°зҡ„еӨҡдёӘзҪ‘з»ңејӮеёёй—®йўҳ

ж–Үз« жҸ’еӣҫ
дё»жңҚеҠЎеҷЁе’Ңд»ҺжңҚеҠЎеҷЁе…ұз”ЁдёҖдёӘIP пјҢ еҪ“дё»жңҚеҠЎеҷЁеҮәй—®йўҳж—¶ пјҢ еҲҮжҚўеҲ°д»ҺжңҚеҠЎеҷЁдёҠ пјҢ 然еҗҺжңҚеҠЎеҷЁд»Ҙз»„ж’ӯзҡ„ж–№ејҸе°ҶжҠўIPзҡ„ж•°жҚ®еҢ…еҸ‘еҮәеҺ» пјҢ иҝҷдёӘж•°жҚ®еҢ…е§Ӣз»ҲжІЎжңүеҸ‘еҮәжқҘ пјҢ еҜјиҮҙжҠўIPж“ҚдҪңеӨұиҙҘ гҖӮйҖҡиҝҮжҺ’жҹҘеҫ—зҹҘ пјҢ з»„ж’ӯж•°жҚ®еҢ…дјҡиў«е®ўжҲ·зҪ‘з»ңзҺҜеўғдёӯзҡ„дёҖеҸ°еҚҺдёәи·Ҝз”ұеҷЁжӢҰжҲӘ пјҢ еҸҜиғҪжҳҜиҝҷеҸ°еҚҺдёәи·Ҝз”ұеҷЁжңүй—®йўҳ пјҢ дҪҶе®ўжҲ·иҰҒжұӮжҲ‘们д»ҺжҲ‘们жңҚеҠЎеҷЁиҝҷдёҖдҫ§еҺ»дҝ®ж”№ пјҢ еҗҺжқҘе°ҶеӨҡж’ӯж”№жҲҗеҚ•ж’ӯжүҚи§ЈеҶій—®йўҳ гҖӮ
е®ўжҲ·зҡ„зҪ‘з»ңи®ҫеӨҮдёҠй…ҚзҪ®дәҶеҫҲеӨҡе®ү全规еҲҷ пјҢ е…¶дёӯдёҖдёӘ规еҲҷжҳҜе°ҶIP-macең°еқҖз»‘е®ҡ пјҢ еҰӮжһңи®ҫеӨҮзҡ„IPе’ҢMACең°еқҖеҜ№дёҚдёҠ пјҢ и®ҫеӨҮеҸ‘еҮәжқҘзҡ„ж•°жҚ®еҢ…е°ұдјҡиў«зҪ‘з»ңи®ҫеӨҮи®ӨдёәжҳҜдёҚе®үе…Ёзҡ„ж•°жҚ® пјҢ дјҡзӣҙжҺҘиў«жӢҰжҲӘ гҖӮеңЁд»ҺжңҚеҠЎеҷЁжӢҝеҲ°дё»жңҚеҠЎеҷЁзҡ„IPд№ӢеҗҺ пјҢ IPеҜ№еә”зҡ„MACең°еқҖе°ұеҸҳдәҶ пјҢ жӯЈеҘҪе°ұи§ҰеҸ‘дәҶиҝҷдёӘIP-MACз»‘е®ҡ规еҲҷ пјҢ еҜјиҮҙж•°жҚ®еҢ…иў«жӢҰжҲӘ гҖӮеҗҺжқҘзҡ„и§ЈеҶіеҠһжі•жҳҜе°Ҷдё»д»ҺжңҚеҠЎеҷЁе…¬з”Ёзҡ„IPдҪңдёәзү№дҫӢиҝӣиЎҢж”ҫиЎҢ пјҢ еҚіеҜ№иҝҷдёӘIPдёҚиҝӣиЎҢжӢҰжҲӘ гҖӮ
8гҖҒLinuxзі»з»ҹзҡ„TCP/IPеҚҸи®®ж ҲйҮҚе®ҡеҗ‘йҖүйЎ№иў«е…ій—ӯ пјҢ ж— жі•е“Қеә”зҪ‘е…іеҸ‘жқҘзҡ„ICMPйҮҚе®ҡеҗ‘ж¶ҲжҒҜ пјҢ еҜјиҮҙ收еҸ‘ж•°жҚ®ж—¶еҮәзҺ°дёҘйҮҚзҡ„дёўеҢ…й—®йўҳ

ж–Үз« жҸ’еӣҫ
з»ҷе®ўжҲ·йғЁзҪІзҡ„зі»з»ҹдёӯ пјҢ жңүеҸ°и®ҫеӨҮж”ҫзҪ®дәҺжҹҗдёӘзҪ‘з»ңиҠӮзӮ№дёӢ пјҢ з»ҷиҜҘи®ҫеӨҮй…ҚзҪ®дәҶиҜҘиҠӮзӮ№дёӢзҡ„й»ҳи®ӨзҪ‘е…і пјҢ з»“жһңиҒ”и°ғдёӢжқҘеҸ‘зҺ° пјҢ жүҖжңүзҡ„е…¶д»–иҠӮзӮ№дёӢзҡ„е…¶д»–и®ҫеӨҮйғҪжІЎй—®йўҳ пјҢ е°ұиҝҷеҸ°и®ҫеӨҮжңүй—®йўҳ пјҢ иҝҷеҸ°и®ҫеӨҮеҸ‘еҮәжқҘзҡ„ж•°жҚ®жңүдёҘйҮҚзҡ„дёўеҢ…й—®йўҳ гҖӮ
зҺ°еңәдәәе‘ҳе’Ңе®ўжҲ·дёҖиө·еҒҡдәҶеҜ№жҜ”жөӢиҜ• пјҢ жҠҠе®ўжҲ·д№ӢеүҚиҙӯд№°зҡ„еҲ«зҡ„еҺӮе•Ҷзҡ„и®ҫеӨҮж”ҫзҪ®еңЁиҜҘзҪ‘з»ңиҠӮзӮ№дёӢ пјҢ еҲ«зҡ„еҺӮе•Ҷзҡ„и®ҫеӨҮйғҪжІЎжңүдёўеҢ…й—®йўҳ пјҢ е°ұжҲ‘们公еҸёзҡ„и®ҫеӨҮжңүй—®йўҳ гҖӮжңҹй—ҙ пјҢ жҲ‘们з»ҷе®ўжҲ·и°ғжӢЁдәҶдёҖдёӘжҲ‘们еҮ е№ҙеүҚз ”еҸ‘зҡ„дёҖж¬ҫиҖҒејҸи®ҫеӨҮ пјҢ ж”ҫзҪ®еңЁиҜҘиҠӮзӮ№дёӢд№ҹжІЎй—®йўҳ пјҢ е°ұеҪ“еүҚдҪҝз”Ёзҡ„ж–°ејҸи®ҫеӨҮжңүй—®йўҳ гҖӮ
иҝҷдёӘй—®йўҳжҠҳи…ҫзҡ„жҜ”иҫғд№… пјҢ е§Ӣз»ҲжІЎжңүжҹҘеҮәжқҘй—®йўҳ пјҢ еҗҺжқҘжүҫе…¬еҸёзҡ„йЎ¶зә§дё“家жқҘжҺ’жҹҘ пјҢ жүҚжҹҘеҮәжқҘй—®йўҳ гҖӮиҝҷеҸ°и®ҫеӨҮеҸ‘еҮәеҺ»зҡ„ж•°жҚ® пјҢ й»ҳи®Өжғ…еҶөдёӢйғҪиҰҒйҖҡиҝҮе…¶й…ҚзҪ®зҡ„й»ҳи®ӨзҪ‘е…іеҸ‘еҮәеҺ» пјҢ жҠ“еҢ…еҸ‘зҺ° пјҢ й»ҳи®ӨзҪ‘е…ідјҡз»ҷи®ҫеӨҮеҸ‘дәҶICMPйҮҚе®ҡеҗ‘ж¶ҲжҒҜ пјҢ иҜҘж¶ҲжҒҜдёӯжҗәеёҰдёҖдёӘIPең°еқҖ пјҢ иҜҘж¶ҲжҒҜжҳҜз”ЁжқҘе‘ҠиҜүи®ҫеӨҮ пјҢ иҰҒеҸ‘йҖҒж•°жҚ®йғҪд»ҺиҝҷдёӘIPеҸ‘еҮәеҺ» гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- дёҖж–ҮиҜҰи§Ји®Ўз®—жңәзҪ‘з»ңIPең°еқҖе’ҢеӯҗзҪ‘жҺ©з Ғ
- иҝҳжҳҜ4GйҰҷпјҹдёӯеӣҪ移еҠЁзӘҒ然жүҝи®Ө дёӯеӣҪ移еҠЁ4gзҪ‘з»ң
- еә”з”ЁйўҳеҸҠзӯ”жЎҲпјҲе°ҸеӯҰ1
- жӢЁеҸ·зҪ‘з»ңPPPoEзҡ„ең°еқҖиҪ¬жҚў pppoe жӢЁеҸ·иҪҜ件
- дёӯе…ҙжңәйЎ¶зӣ’зҡ„еҲ·жңәж•ҷзЁӢ дёӯе…ҙзҪ‘з»ңжңәйЎ¶зӣ’еҜҶз Ғ
- йҖӮеҗҲжҗ¬з –зҡ„зҪ‘з»ңжёёжҲҸжңүе“Әдәӣ еҚҒеӨ§жҗ¬з –зҪ‘жёёеңЁе®¶жҢЈй’ұ2022
- и°·еҫ·и®ҫи®ЎзҪ‘пјҹе»әзӯ‘дёҠжңүй—®йўҳдёҠе“ӘдәӣзҪ‘з«ҷеҸҜд»Ҙеҫ—еҲ°жҜ”иҫғдё“дёҡзҡ„еӣһзӯ”пјҹ
- arpanetеұһдәҺеҮ д»ЈзҪ‘з»ңпјҹARPANETиҝҷжҳҜд»Җд№Ҳж„ҸжҖқпјҹ
- з”өеҪұ|еҶҚеҲ·гҖҠй•ҝе®үеҚҒдәҢж—¶иҫ°гҖӢ й—®еҮ дёӘй—®йўҳ и°ҒиғҪеӣһзӯ”
- дәәдәәйҳ…иҜ»еҷЁ4.1з ҙи§Ј дәәдәәйҳ…иҜ»еҷЁиғҪеңЁжІЎжңүзҪ‘з»ңзҡ„зҺҜеўғдёӢдҪҝз”Ёеҗ—?