
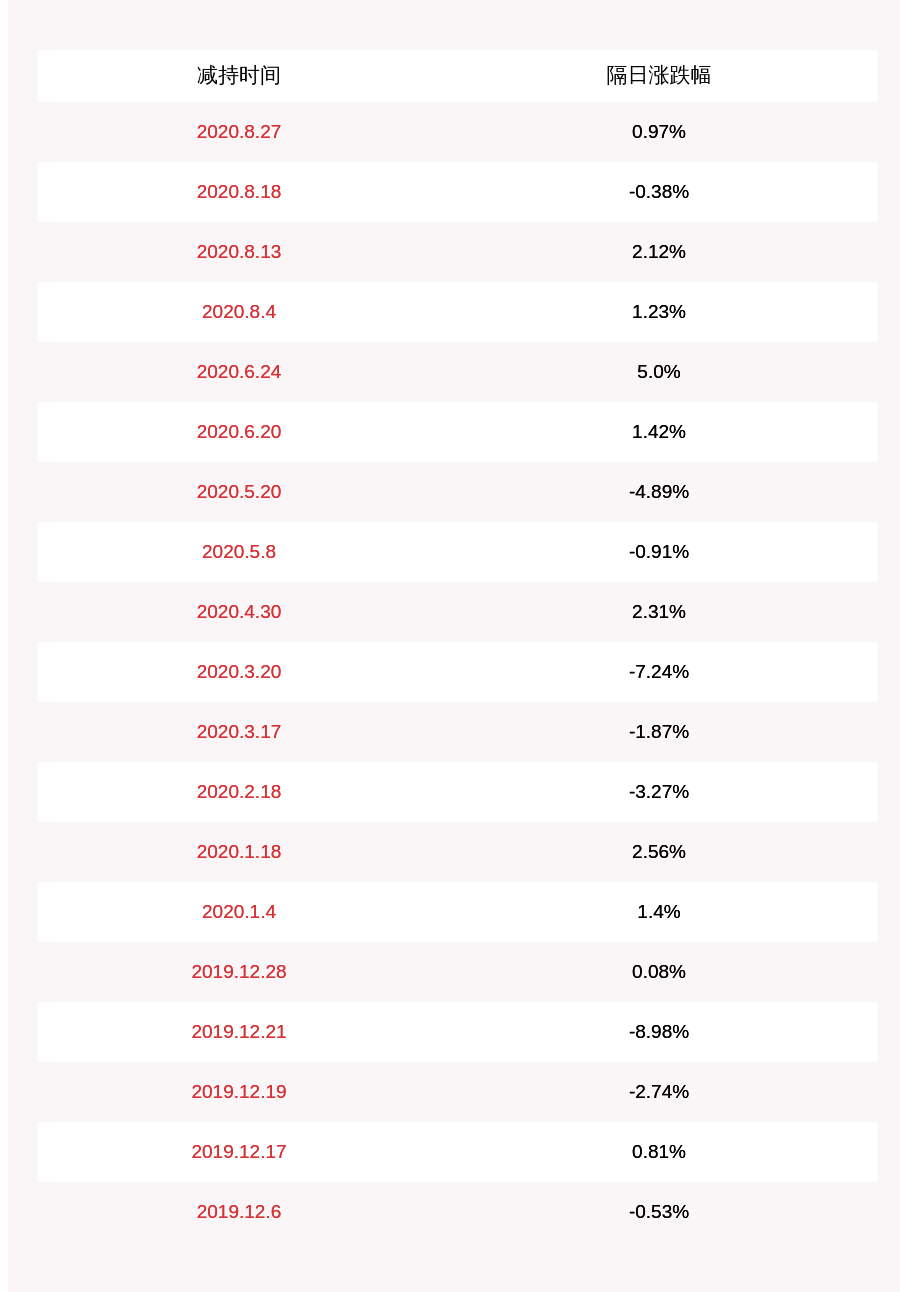
ж–Үз« жҸ’еӣҫ
еӣҫ 13пјҡз”Ёе·Ҙе…·иҫ…еҠ©дәәзұ»еҜ№еҲҶзұ»еҷЁиҝӣиЎҢеҜ№жҠ—ж”»еҮ»зҡ„ UI гҖӮдәәзұ»иҰҒеҒҡзҡ„жҳҜзј–иҫ‘жҲ–иЎҘе…Ё promptпјҢд»ҘйҷҚдҪҺжЁЎеһӢйў„жөӢиҫ“е…ҘжҳҜжҡҙеҠӣеҶ…е®№зҡ„жҰӮзҺҮ гҖӮ
Xu et al. 2021 зҡ„гҖҠBot-Adversarial Dialogue for Safe Conversational AgentsгҖӢжҸҗеҮәдәҶ Bot-Adversarial DialogueпјҲBADпјү пјҢ иҜҘжЎҶжһ¶еҸҜд»Ҙеј•еҜјдәәзұ»еҺ»иҜұдҪҝжЁЎеһӢзҠҜй”ҷпјҲжҜ”еҰӮиҫ“еҮәдёҚе®үе…Ёзҡ„еҶ…е®№пјү гҖӮ他们收йӣҶдәҶ 5000 еӨҡз»„жЁЎеһӢдёҺдј—еҢ…е·ҘдҪңиҖ…зҡ„еҜ№иҜқ гҖӮжҜҸдёҖз»„еҜ№иҜқйғҪеҢ…еҗ« 14 иҪ®пјҢ然еҗҺд»–д»¬ж №жҚ®дёҚе®үе…ЁеҜ№иҜқиҪ®ж¬Ўзҡ„ж•°йҮҸз»ҷжЁЎеһӢжү“еҲҶ гҖӮ他们жңҖз»Ҳеҫ—еҲ°дәҶ BAD ж•°жҚ®йӣҶпјҢе…¶дёӯеҢ…еҗ«еӨ§зәҰ 2500 з»„еёҰжңүж”»еҮ»жҖ§ж Үзӯҫзҡ„еҜ№иҜқ гҖӮ
Anthropic зҡ„зәўйҳҹж•°жҚ®йӣҶеҢ…еҗ«жҺҘиҝ‘ 4 дёҮдёӘеҜ№жҠ—ж”»еҮ»пјҢе®ғ们收йӣҶиҮӘдәәзұ»зәўйҳҹиҖ…дёҺ LLM зҡ„еҜ№иҜқ гҖӮ他们еҸ‘зҺ°пјҢRLHF зҡ„规模и¶ҠеӨ§пјҢе°ұи¶Ҡйҡҫд»Ҙж”»еҮ» гҖӮOpenAI еҸ‘еёғзҡ„еӨ§жЁЎеһӢпјҲжҜ”еҰӮ GPT-4 е’Ң DALL-E 3пјүжҷ®йҒҚдҪҝз”ЁдәҶдәәзұ»дё“家зәўйҳҹжқҘиҝӣиЎҢе®үе…ЁеҮҶеӨҮ гҖӮ
ж•°жҚ®йӣҶең°еқҖпјҡ
https://github.com/anthropics/hh-rlhf/tree/master/red-team-attempts
жЁЎеһӢзәўйҳҹзӯ–з•Ҙ
дәәзұ»зәўйҳҹзӯ–з•ҘеҫҲејәеӨ§ пјҢ дҪҶжҳҜйҡҫд»ҘеӨ§и§„жЁЎе®һж–ҪиҖҢдё”еҸҜиғҪйңҖиҰҒеӨ§йҮҸз»ҸиҝҮеҹ№и®ӯзҡ„дё“дёҡдәәеЈ« гҖӮзҺ°еңЁжғіиұЎдёҖдёӢпјҡжҲ‘们еҸҜд»ҘеӯҰд№ дёҖдёӘзәўйҳҹжЁЎеһӢ red жқҘдёҺзӣ®ж Ү LLM иҝӣиЎҢеҜ№жҠ—пјҢд»Ҙи§ҰеҸ‘е…¶з»ҷеҮәдёҚе®үе…Ёе“Қеә” гҖӮеҜ№дәҺеҹәдәҺжЁЎеһӢзҡ„зәўйҳҹзӯ–з•ҘпјҢдё»иҰҒзҡ„йҡҫйўҳжҳҜеҰӮдҪ•еҲӨж–ӯдёҖж¬Ўж”»еҮ»жҳҜеҗҰжҲҗеҠҹпјӣеҸӘжңүзҹҘйҒ“дәҶиҝҷдёҖзӮ№пјҢжҲ‘们жүҚиғҪжһ„е»әз”ЁдәҺи®ӯз»ғзәўйҳҹжЁЎеһӢзҡ„еҗҲйҖӮеӯҰд№ дҝЎеҸ· гҖӮ
еҒҮи®ҫжҲ‘们已з»ҸжңүдёҖдёӘй«ҳиҙЁйҮҸзҡ„еҲҶзұ»еҷЁпјҢиғҪеӨҹеҲӨж–ӯжЁЎеһӢзҡ„иҫ“еҮәжҳҜеҗҰжңүе®іпјҢжҲ‘们е°ұеҸҜд»Ҙе°Ҷе…¶з”ЁдҪңеҘ–еҠұжқҘи®ӯз»ғзәўйҳҹжЁЎеһӢпјҢд»Ҙеҫ—еҲ°дёҖдәӣиғҪжңҖеӨ§еҢ–еҲҶзұ»еҷЁеңЁзӣ®ж ҮжЁЎеһӢиҫ“еҮәдёҠзҡ„еҲҶж•°зҡ„иҫ“е…Ҙ гҖӮд»Ө r (, ) жҳҜдёҖдёӘиҝҷж ·зҡ„зәўйҳҹеҲҶзұ»еҷЁпјҢе…¶еҸҜд»ҘеҲӨж–ӯеңЁз»ҷе®ҡжөӢиҜ•иҫ“е…Ҙ ж—¶пјҢиҫ“еҮә жҳҜеҗҰжңүе®і гҖӮж №жҚ® Perez et al. 2022 зҡ„и®әж–ҮгҖҠRed Teaming Language Models with Language ModelsгҖӢпјҢеҜ»жүҫеҜ№жҠ—ж”»еҮ»ж ·жң¬йҒөеҫӘдёҖдёӘз®ҖеҚ•зҡ„дёүжӯҘејҸиҝҮзЁӢпјҡ
д»ҺдёҖдёӘзәўйҳҹ LLM ~p_red (.) йҮҮж ·жөӢиҜ•иҫ“е…Ҙпјӣ
дҪҝз”Ёзӣ®ж Ү LLM p ( | ) дёәжҜҸдёӘжөӢиҜ•жЎҲдҫӢ з”ҹжҲҗдёҖдёӘиҫ“еҮә пјӣ
ж №жҚ®еҲҶзұ»еҷЁ r (, )пјҢеңЁжөӢиҜ•жЎҲдҫӢдёӯжүҫеҲ°дёҖдёӘдјҡеҫ—еҲ°жңүе®іиҫ“еҮәзҡ„еӯҗйӣҶ гҖӮ
他们е®һйӘҢдәҶеҮ з§Қд»ҺзәўйҳҹжЁЎеһӢйҮҮж ·жҲ–иҝӣдёҖжӯҘи®ӯз»ғзәўйҳҹжЁЎеһӢд»ҘдҪҝе…¶жӣҙеҠ жңүж•Ҳзҡ„ж–№жі• пјҢ е…¶дёӯеҢ…жӢ¬йӣ¶ж ·жң¬з”ҹжҲҗгҖҒйҡҸжңәејҸе°‘ж ·жң¬з”ҹжҲҗгҖҒзӣ‘зқЈеӯҰд№ гҖҒејәеҢ–еӯҰд№ гҖӮ
Casper et al. (2023) зҡ„и®әж–ҮгҖҠExplore, Establish, Exploit: Red Teaming Language Models from ScratchгҖӢи®ҫи®ЎдәҶдёҖз§Қжңүдәәзұ»еҸӮдёҺзҡ„зәўйҳҹиҝҮзЁӢ гҖӮе…¶дёҺ Perez et al. (2022) зҡ„дё»иҰҒдёҚеҗҢд№ӢеӨ„еңЁдәҺе…¶жҳҺзЎ®ең°дёәзӣ®ж ҮжЁЎеһӢи®ҫзҪ®дәҶдёҖдёӘж•°жҚ®йҮҮж ·йҳ¶ж®өпјҢиҝҷж ·е°ұеҸҜд»Ҙ收йӣҶе…¶дёҠзҡ„дәәзұ»ж ҮзӯҫжқҘи®ӯз»ғй’ҲеҜ№зү№е®ҡд»»еҠЎзҡ„зәўйҳҹеҲҶзұ»еҷЁ гҖӮе…¶еҢ…еҗ«жҺўзҙўпјҲExploreпјүгҖҒе»әз«ӢпјҲEstablishпјүе’ҢеҲ©з”ЁпјҲExploitпјүдёүдёӘйҳ¶ж®өпјҢеҰӮдёӢеӣҫжүҖзӨә гҖӮ

ж–Үз« жҸ’еӣҫ
еӣҫ 15пјҡйҮҮз”ЁгҖҢжҺўзҙў - е»әз«Ӣ - еҲ©з”ЁгҖҚдёүжӯҘејҸж–№жі•зҡ„зәўйҳҹзӯ–з•ҘжөҒзЁӢ
Mehrabi et al. 2023 зҡ„и®әж–ҮгҖҠFLIRT: Feedback Loop In-context Red TeamingгҖӢеҲҷжҳҜдҫқйқ зәўйҳҹ LM _red зҡ„дёҠдёӢж–ҮеӯҰд№ жқҘж”»еҮ»еӣҫеғҸжҲ–ж–Үжң¬з”ҹжҲҗжЁЎеһӢ пјҢдҪҝе…¶иҫ“еҮәдёҚе®үе…Ёзҡ„еҶ…е®№ гҖӮ
еңЁжҜҸдёҖж¬Ў FLIRT иҝӯд»Јдёӯпјҡ
зәўйҳҹ LM _red з”ҹжҲҗдёҖдёӘеҜ№жҠ— prompt ~_red (. | examples)пјӣе…¶дёӯеҲқе§Ӣзҡ„дёҠдёӢж–Үж ·жң¬з”ұдәәзұ»и®ҫи®Ўпјӣ
з”ҹжҲҗжЁЎеһӢ ж №жҚ®иҝҷдёӘ prompt з”ҹжҲҗдёҖдёӘеӣҫеғҸжҲ–ж–Үжң¬иҫ“еҮә пјӣ
дҪҝз”ЁеҲҶзұ»еҷЁзӯүжңәеҲ¶еҜ№з”ҹжҲҗзҡ„еҶ…е®№ иҝӣиЎҢиҜ„дј°пјҢзңӢе…¶жҳҜеҗҰе®үе…Ёпјӣ
еҰӮжһң иў«и®ӨдёәдёҚе®үе…ЁпјҢеҲҷдҪҝз”Ёи§ҰеҸ‘ prompt жқҘжӣҙж–° _red зҡ„дёҠдёӢж–ҮжЁЎжқҝпјҢдҪҝе…¶ж №жҚ®зӯ–з•Ҙз”ҹжҲҗж–°зҡ„еҜ№жҠ— prompt гҖӮ
иҮідәҺеҰӮдҪ•жӣҙж–° FLIRT зҡ„дёҠдёӢж–ҮжЁЎжқҝпјҢжңүиҝҷж ·еҮ дёӘзӯ–з•ҘпјҡFIFOгҖҒLIFOгҖҒScoringгҖҒScoring-LIFO гҖӮиҜҰи§ҒеҺҹи®әж–Ү гҖӮ

ж–Үз« жҸ’еӣҫ
еӣҫ 16пјҡеңЁдёҚеҗҢзҡ„жү©ж•ЈжЁЎеһӢдёҠ пјҢ дёҚеҗҢж”»еҮ»зӯ–з•Ҙзҡ„ж”»еҮ»жңүж•ҲзҺҮпјҲи§ҰеҸ‘дәҶдёҚе®үе…Ёз”ҹжҲҗз»“жһңзҡ„з”ҹжҲҗ prompt зҡ„зҷҫеҲҶжҜ”пјү гҖӮеҹәеҮҶжҳҜ SFSпјҲйҡҸжңәе°‘ж ·жң¬пјү гҖӮжӢ¬еҸ·дёӯзҡ„ж•°еҖјжҳҜзӢ¬зү№ prompt зҡ„зҷҫеҲҶжҜ” гҖӮ
еҰӮдҪ•еә”еҜ№ж”»еҮ»
йһҚзӮ№й—®йўҳ
Madry et al. 2017 зҡ„гҖҠTowards Deep Learning Models Resistant to Adversarial AttacksгҖӢжҸҗеҮәдәҶдёҖдёӘеҫҲдёҚй”ҷзҡ„еҜ№жҠ—зЁіеҒҘжҖ§пјҲadversarial robustnessпјүжЎҶжһ¶пјҢеҚіе°ҶеҜ№жҠ—зЁіеҒҘжҖ§е»әжЁЎжҲҗдёҖдёӘйһҚзӮ№й—®йўҳпјҢиҝҷж ·е°ұеҸҳжҲҗдәҶдёҖдёӘзЁіеҒҘдјҳеҢ–пјҲrobust optimizationпјүй—®йўҳ гҖӮиҜҘжЎҶжһ¶жҳҜдёәеҲҶзұ»д»»еҠЎзҡ„иҝһз»ӯиҫ“е…ҘиҖҢжҸҗеҮәзҡ„пјҢдҪҶе®ғз”ЁзӣёеҪ“з®ҖжҙҒзҡ„ж•°еӯҰе…¬ејҸжҸҸиҝ°дәҶеҸҢеұӮдјҳеҢ–иҝҮзЁӢпјҢеӣ жӯӨеҖјеҫ—еҲҶдә« гҖӮ
и®©жҲ‘们иҖғиҷ‘дёҖдёӘеҲҶзұ»д»»еҠЎпјҢе…¶еҹәдәҺз”ұй…ҚеҜ№зҡ„ (ж ·жң¬пјҢж Үзӯҫ) жһ„жҲҗзҡ„ж•°жҚ®еҲҶеёғпјҢ(,)∈пјҢи®ӯз»ғдёҖдёӘзЁіеҒҘеҲҶзұ»еҷЁзҡ„зӣ®ж Үе°ұжҳҜдёҖдёӘйһҚзӮ№й—®йўҳпјҡ

жҺЁиҚҗйҳ…иҜ»














- йҳІзҒ«зҹҘиҜҶйЎәеҸЈжәң йҳІзҒ«зҹҘиҜҶйЎәеҸЈжәң6еҸҘз®Җзҹӯ
- еҶ¬еӯЈе®үе…Ёз”ҹдә§жіЁж„ҸдәӢйЎ№еҸҠйў„йҳІжҺӘж–ҪеҶ…е®№ еҶ¬еӯЈе®үе…Ёз”ҹдә§жіЁж„ҸдәӢйЎ№еҸҠйў„йҳІжҺӘж–Ҫ
- з”ҹжҖҒзі»з»ҹиғҪйҮҸжөҒеҠЁзҡ„дҪңз”Ё з”ҹжҖҒзі»з»ҹиғҪйҮҸжөҒеҠЁзҡ„еҗ«д№үжҳҜд»Җд№Ҳ
- йӮ®ж”ҝеӮЁи“„еҸҜд»ҘеҠһиҙ·ж¬ҫеҗ—е®үе…Ёеҗ— йӮ®ж”ҝеӮЁи“„еҸҜд»ҘеҠһиҙ·ж¬ҫеҗ—
- йЈҹе“Ғе®үе…Ёж¶Ҳиҙ№жҸҗзӨәеҶ…е®№,йЈҹе“Ғе®үе…Ёи®ёеҸҜй…ёеҘ¶
- йёҝи’ҷзі»з»ҹиҖ—з”өеҝ«д»Җд№ҲеҺҹеӣ пјҢйёҝи’ҷзі»з»ҹеҚҮзә§еҚҠе№ҙеҗҺиҖ—з”өиҝҳжҳҜеҝ«
- еҶ¬еӯЈе®ҝиҲҚз”Ёз”өе®үе…ЁжіЁж„ҸдәӢйЎ№ е®ҝиҲҚз”Ёз”өе®үе…ЁжіЁж„ҸдәӢйЎ№
- зҺ°д»Је®үе…ЁеёҪзҡ„еҸ‘жҳҺжҳҜеҸ—еҲ°дәҶд»Җд№ҲеҠЁзү©зҡ„еҗҜеҸ‘ е®үе…ЁеёҪзҡ„еҸ‘жҳҺжҳҜеҸ—еҲ°дәҶе•„жңЁйёҹзҡ„еҗҜеҸ‘
- й»‘иӢ№жһңзі»з»ҹдҪҝз”Ёдёӯзҡ„й—®йўҳ,й»‘иӢ№жһңе»әи®®жӣҙж–°зі»з»ҹеҗ—
- cajж–Ү件жҖҺд№Ҳжү“ејҖдёҖй”®йҮҚиЈ…зі»з»ҹ