з ”з©¶|дәәзұ»е’ҢжңәеҷЁж„ҹзҹҘжҜ”иҫғдёӯеёёи§Ғзҡ„дёүеӨ§йҷ·йҳұпјҢдҪ дёӯдәҶеҮ жқЎпјҹ( дәҢ )
жңүи¶Јзҡ„жҳҜпјҢжҲ‘们еҸ‘зҺ°пјҢеҚідҪҝжҸҗдҫӣз»ҷиҝҷдёӘжЁЎеһӢзҡ„еӣҫеқ—е°ҸдәҺй—ӯеҗҲиҪ®е»“пјҢDNN д»Қ然表зҺ°иүҜеҘҪгҖӮиҝҷдёҖеҸ‘зҺ°иЎЁжҳҺпјҢиҰҒи®©жЁЎеһӢжЈҖжөӢеҮәжҲ‘们жүҖдҪҝз”Ёзҡ„иҝҷдёҖз»„еӣҫеғҸеҲәжҝҖдёӯжҳҜеҗҰеҗ«жңүй—ӯеҗҲиҪ®е»“пјҢж•ҙдҪ“дҝЎжҒҜ并дёҚжҳҜеҝ…йЎ»зҡ„гҖӮдёӢеӣҫеұ•зӨәдәҶжЁЎеһӢеҸҜиғҪдҪҝз”Ёзҡ„еұҖйғЁзү№жҖ§:жҹҗдәӣзәҝзҡ„й•ҝеәҰдёәжӯЈзЎ®зҡ„еҲҶзұ»д»»еҠЎжҸҗдҫӣдәҶзәҝзҙўгҖӮ
дёҖдёӘеҸӘиғҪи®ҝй—®еұҖйғЁеҢәеҹҹзҡ„жЁЎеһӢпјҲBagNetпјүжҳҫзӨәпјҢеӣҫеҪўзҡ„ж•ҙдҪ“зү№жҖ§еҜ№дәҺжЁЎеһӢе®ҢжҲҗжҲ‘们зҡ„д»»еҠЎжқҘиҜҙпјҢ并дёҚжҳҜеҝ…йңҖзҡ„гҖӮзӣёеҸҚпјҢеұҖйғЁеҢәеҹҹеҮ д№Һе·Із»ҸеҸҜд»ҘдёәжӯЈзЎ®зҡ„еҲҶзұ»д»»еҠЎжҸҗдҫӣи¶іеӨҹзҡ„иҜҒжҚ®гҖӮжӣҙе…·дҪ“ең°иҜҙпјҢдёҖжқЎзҹӯзәҝе’ҢдёҖдёӘејҖж”ҫзҡ„е°ҫз«ҜдёәжЁЎеһӢе°ҶеӣҫеҪўеҲӨж–ӯдёәејҖж”ҫиҪ®е»“жҸҗдҫӣдәҶиҜҒжҚ®гҖӮ
дҪңдёәдәәзұ»пјҢжҲ‘们常常жү§зқҖдәҺеј„жё…дёҖдёӘзү№е®ҡзҡ„д»»еҠЎжҳҜеҰӮдҪ•иў«и§ЈеҶізҡ„гҖӮеңЁиҝҷдёӘжЎҲдҫӢдёӯпјҢжҲ‘们и®ӨдёәеҸӘжңүйҖҡиҝҮиҪ®е»“ж•ҙеҗҲжүҚиғҪи§ЈеҶій—ӯеҗҲиҪ®е»“иҜҶеҲ«иҝҷдёҖй—®йўҳпјҢ然иҖҢз»“жһңиҜҒжҳҺиҝҷдёӘеҒҮи®ҫжҳҜй”ҷзҡ„гҖӮ
зӣёеҸҚпјҢжӣҙз®ҖеҚ•зҡ„и§ЈеҶіж–№жЎҲжҳҜд»Һдәәзұ»зҡ„и§’еәҰеҹәдәҺеұҖйғЁзү№еҫҒиҝӣиЎҢиҜҶеҲ«пјҢиҝҷжҳҜйҡҫд»Ҙйў„ж–ҷеҫ—еҲ°зҡ„гҖӮ
еңЁжҜ”иҫғдәәи„‘е’ҢжңәеҷЁжЁЎеһӢж—¶пјҢиҝҷдёҖзӮ№йңҖиҰҒи°Ёи®°дәҺеҝғвҖ”вҖ”DNNsиғҪеӨҹжүҫеҲ°дёҺжҲ‘们жңҹжңӣе®ғ们дҪҝз”Ёзҡ„ж–№жі•е®Ңе…ЁдёҚеҗҢзҡ„и§ЈеҶіж–№жЎҲгҖӮдёәдәҶйҒҝе…ҚжҲ‘们仓дҝғеҫ—еҮәжңүдәәдёәеҒҸи§Ғзҡ„з»“и®әпјҢеҪ»еә•жЈҖжҹҘж•ҙдёӘжЁЎеһӢпјҢеҢ…жӢ¬е…¶еҶізӯ–иҝҮзЁӢе’Ңж•°жҚ®йӣҶпјҢжҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮ
йҷ·йҳұ2пјҡеҫҲйҡҫеҫ—еҮәи¶…еҮәжөӢиҜ•жһ¶жһ„е’Ңи®ӯз»ғиҝҮзЁӢзҡ„дёҖиҲ¬жҖ§з»“и®ә
дёӢеӣҫжҳҫзӨәдәҶеҗҲжҲҗи§Ҷи§үжҺЁзҗҶжөӢиҜ•пјҲSVRTпјүзҡ„дёӨдёӘзӨәдҫӢпјҲFleuretзӯүдәә 2011е№ҙзҡ„е·ҘдҪңгҖҠComparing machines and humans on a visual categorization testгҖӢпјүгҖӮ
дҪ иғҪи§ЈеҶідёӢйқўзҡ„й—®йўҳеҗ—пјҹ
ж–Үз« еӣҫзүҮ
SVRTж•°жҚ®йӣҶзҡ„23дёӘй—®йўҳдёӯпјҢжҜҸдёҖдёӘй—®йўҳйғҪеҸҜд»Ҙзӣёеә”ең°еҲҶй…ҚеҲ°дёӨдёӘд»»еҠЎзұ»еҲ«зҡ„е…¶дёӯд№ӢдёҖгҖӮ第дёҖзұ»з§°дёәвҖңзӣёеҗҢ-дёҚеҗҢд»»еҠЎвҖқпјҢйңҖиҰҒжЁЎеһӢеҲӨж–ӯеҪўзҠ¶жҳҜеҗҰзӣёеҗҢгҖӮ第дәҢзұ»з§°дёәвҖңз©әй—ҙд»»еҠЎвҖқпјҢйңҖиҰҒж №жҚ®еҪўзҠ¶еңЁз©әй—ҙдёҠзҡ„жҺ’еҲ—ж–№ејҸеҒҡеҮәеҲӨж–ӯпјҢдҫӢеҰӮпјҢж №жҚ®дёҖдёӘеҪўзҠ¶жҳҜеҗҰдҪҚдәҺеҸҰдёҖдёӘеҪўзҠ¶зҡ„дёӯеҝғеҒҡеҮәеҲӨж–ӯгҖӮ
дәәзұ»йҖҡеёёйқһеёёж“…й•ҝи§ЈеҶіSVRTй—®йўҳпјҢеҸӘйңҖиҰҒеҮ дёӘзӨәдҫӢеӣҫеғҸе°ұеҸҜд»ҘеӯҰд№ жҪңеңЁзҡ„规еҲҷпјҢ然еҗҺе°ұиғҪжӯЈзЎ®ең°еҜ№ж–°еӣҫеғҸиҝӣиЎҢеҲҶзұ»гҖӮ
жӣҫжңүдёӨдёӘз ”з©¶е°Ҹз»„з”ЁSVRTж•°жҚ®йӣҶжөӢиҜ•дәҶж·ұеәҰзҘһз»ҸзҪ‘з»ңгҖӮ他们еҸ‘зҺ°иҝҷдёӨдёӘд»»еҠЎзұ»еҲ«зҡ„жөӢиҜ•з»“жһңеӯҳеңЁеҫҲеӨ§е·®ејӮпјҡ他们зҡ„жЁЎеһӢеңЁз©әй—ҙд»»еҠЎдёҠиЎЁзҺ°иүҜеҘҪпјҢдҪҶеңЁвҖңзӣёеҗҢ-дёҚеҗҢд»»еҠЎвҖқдёҠеҚҙиЎЁзҺ°дёҚдҪігҖӮKimзӯүдәәеңЁ2018е№ҙжҸҗеҮәпјҢеҸҜиғҪжҳҜдәәзұ»еӨ§и„‘дёӯеғҸе‘ЁжңҹжҖ§иҝһжҺҘиҝҷж ·зҡ„еҸҚйҰҲжңәеҲ¶пјҢеҜ№дәҺе®ҢжҲҗзӣёеҗҢ-дёҚеҗҢд»»еҠЎжқҘиҜҙиҮіе…ійҮҚиҰҒгҖӮ
иҝҷдәӣз»“жһңе·Із»Ҹиў«еј•иҜҒдёәжӣҙе№ҝжіӣзҡ„иҜҙжі•вҖ”вҖ”DNNsдёҚиғҪеҫҲеҘҪең°е®ҢжҲҗвҖңзӣёеҗҢ-дёҚеҗҢд»»еҠЎвҖқгҖӮиҖҢдёӢйқўжҲ‘们е°ҶиҰҒжҸҗеҲ°зҡ„е®һйӘҢпјҢе°ҶиҜҒжҳҺдәӢе®һ并йқһеҰӮжӯӨгҖӮ
KimзӯүдәәдҪҝз”Ёзҡ„DNNsеҸӘеҢ…жӢ¬2-6еұӮпјҢдҪҶйҖҡеёёз”ЁдәҺеҜ№иұЎеҲҶзұ»д»»еҠЎзҡ„DNNsзӣёжҜ”д№ӢдёӢиҰҒеӨ§еҫ—еӨҡгҖӮжҲ‘们жғізҹҘйҒ“ж ҮеҮҶзҡ„DNNsжҳҜеҗҰд№ҹдјҡеҮәзҺ°зұ»дјјзҡ„з»“жһңгҖӮдёәжӯӨпјҢжҲ‘们дҪҝз”ЁResNet-50иҝӣиЎҢдәҶеҗҢж ·зҡ„е®һйӘҢгҖӮ
жңүи¶Јзҡ„жҳҜпјҢжҲ‘们еҸ‘зҺ°ResNet-50е®ҢжҲҗзҡ„жүҖжңүд»»еҠЎ(еҢ…жӢ¬зӣёеҗҢ-дёҚеҗҢд»»еҠЎ)зҡ„еҮҶзЎ®зҺҮеқҮиҫҫеҲ°90%д»ҘдёҠпјҢеҚідҪҝдёҺKimзӯүдәәдҪҝз”Ёзҡ„100дёҮеј еӣҫеғҸзӣёжҜ”пјҢжҲ‘们еҸӘдҪҝз”ЁдәҶ28000еј и®ӯз»ғеӣҫеғҸгҖӮиҝҷиЎЁжҳҺеүҚйҰҲзҘһз»ҸзҪ‘з»ңзЎ®е®һеҸҜд»ҘеңЁвҖңзӣёеҗҢ-дёҚеҗҢд»»еҠЎвҖқдёҠиҫҫеҲ°иҫғй«ҳзҡ„зІҫеәҰгҖӮ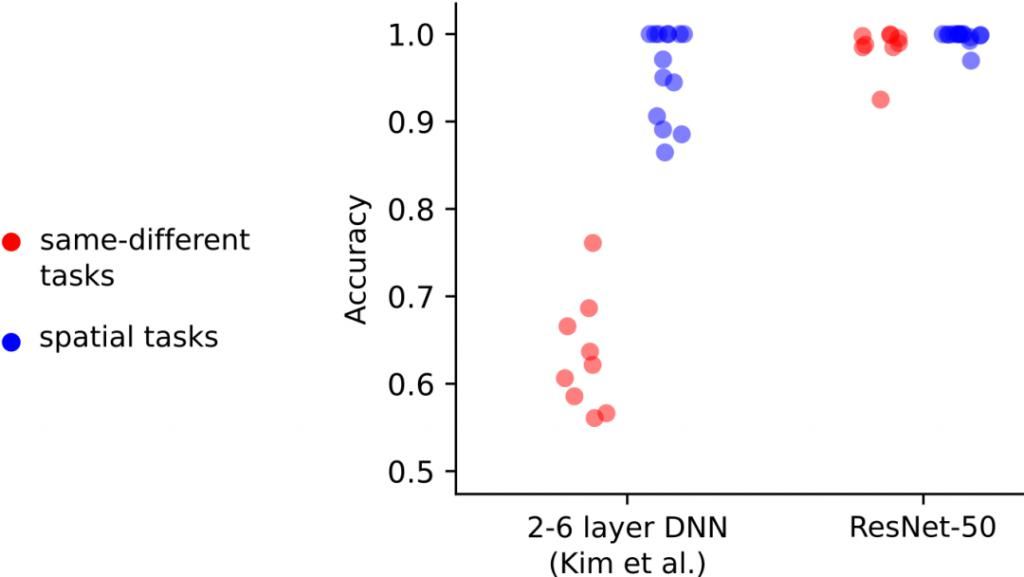
ж–Үз« еӣҫзүҮ
Kimзӯүдәәзҡ„з ”з©¶з»“жһңиЎЁжҳҺпјҢеҸӘеҢ…еҗ«2-6еұӮзҡ„DNNsеҸҜд»ҘеҫҲе®№жҳ“ең°и§ЈеҶіз©әй—ҙд»»еҠЎпјҢдҪҶжҳҜеҜ№вҖңзӣёеҗҢ-дёҚеҗҢд»»еҠЎвҖқиЎЁзҺ°дёҚдҪігҖӮжҲ‘们жүҫеҲ°дәҶдёҖдёӘжЁЎеһӢ(ResNet-50)пјҢе®ғеҜ№дёӨз§Қзұ»еһӢзҡ„д»»еҠЎйғҪиғҪиҫҫеҲ°еҫҲй«ҳзҡ„еҮҶзЎ®зҺҮгҖӮиҝҷдёҖеҸ‘зҺ°иЎЁжҳҺпјҢзӣёеҗҢ-дёҚеҗҢд»»еҠЎеҜ№еүҚйҰҲжЁЎеһӢжІЎжңүеӣәжңүзҡ„йҷҗеҲ¶гҖӮ
еңЁз¬¬дәҢдёӘе®һйӘҢдёӯпјҢжҲ‘们еҸӘдҪҝз”ЁдәҶ1000дёӘи®ӯз»ғж ·жң¬гҖӮеңЁиҝҷдёӘеңәжҷҜдёӯпјҢжҲ‘们еҸ‘зҺ°еҜ№дәҺеӨ§еӨҡж•°з©әй—ҙд»»еҠЎпјҢжЁЎеһӢд»Қ然еҸҜд»ҘиҫҫеҲ°иҫғй«ҳзҡ„еҮҶзЎ®еәҰпјҢиҖҢеҜ№дәҺзӣёеҗҢ-дёҚеҗҢд»»еҠЎпјҢеҮҶзЎ®еәҰдјҡдёӢйҷҚгҖӮиҝҷжҳҜеҗҰж„Ҹе‘ізқҖзӣёеҗҢ-дёҚеҗҢд»»еҠЎжӣҙеҠ еӣ°йҡҫпјҹжҲ‘们и®ӨдёәпјҢдҪҺж•°жҚ®жЁЎејҸ并дёҚйҖӮеҗҲз”ЁдәҺеҶіе®ҡд»»еҠЎзҡ„йҡҫеәҰгҖӮеӯҰд№ йҖҹеәҰеҫҲеӨ§зЁӢеәҰдёҠеҸ–еҶідәҺзі»з»ҹзҡ„еҲқе§ӢжқЎд»¶гҖӮдёҺжҲ‘们зҡ„DNNsдёҚеҗҢпјҢдәәзұ»жҳҜд»Һз»Ҳиә«еӯҰд№ дёӯиҺ·зӣҠгҖӮжҚўиЁҖд№ӢпјҢеҰӮжһңд»Һйӣ¶ејҖе§Ӣи®ӯз»ғдәәзұ»и§Ҷи§үзі»з»ҹе®ҢжҲҗиҝҷдёӨзұ»д»»еҠЎпјҢеҲҷдәәзұ»и§Ҷи§үзі»з»ҹд№ҹеҫҲеҸҜиғҪдјҡеңЁж ·жң¬ж•ҲзҺҮдёҠиЎЁзҺ°еҮәдёҺResNet-50зӣёдјјзҡ„е·®ејӮгҖӮ
йӮЈд№ҲжҲ‘们д»ҺиҝҷдёӘжЎҲдҫӢз ”з©¶дёӯеӯҰеҲ°дәҶд»Җд№ҲеҸҜд»Ҙз”ЁдәҺжҜ”иҫғдәәзұ»и§Ҷи§үе’ҢжңәеҷЁи§Ҷи§үе‘ўпјҹ
йҰ–е…ҲпјҢеҒҡеҮәд»»дҪ•е…ідәҺDNNsдёҚиғҪеҫҲеҘҪең°жү§иЎҢжҹҗдёӘзү№е®ҡд»»еҠЎзҡ„з»“и®әпјҢжҲ‘们йғҪеҝ…йЎ»иҰҒи°Ёж…ҺгҖӮи®ӯз»ғDNNsжҳҜдёҖдёӘеӨҚжқӮзҡ„д»»еҠЎпјҢиҖҢдё”е®ғ们зҡ„жҖ§иғҪеҫҲеӨ§зЁӢеәҰдёҠеҸ–еҶідәҺз»ҸиҝҮжөӢиҜ•зҡ„дҪ“зі»з»“жһ„е’Ңи®ӯз»ғиҝҮзЁӢзҡ„еҗ„дёӘж–№йқўгҖӮе…¶ж¬ЎпјҢжҳҺзҷҪDNNsе’Ңдәәзұ»жңүдёҚеҗҢзҡ„еҲқе§ӢжқЎд»¶иҝҷдёҖзӮ№д№ҹеҫҲйҮҚиҰҒгҖӮеӣ жӯӨпјҢеҪ“жҲ‘们д»ҺдҪҝз”ЁеҫҲе°‘зҡ„и®ӯз»ғж•°жҚ®зҡ„зҺҜеўғдёӯеҫ—еҮәз»“и®әж—¶пјҢе°Өе…¶йңҖиҰҒе°Ҹеҝғи°Ёж…ҺгҖӮ
жҖ»иҖҢиЁҖд№ӢпјҢеңЁеҫ—еҮәи¶…еҮәжөӢиҜ•жһ¶жһ„е’Ңи®ӯз»ғиҝҮзЁӢзҡ„дёҖиҲ¬жҖ§з»“и®әж—¶пјҢжҲ‘们еҝ…йЎ»дҝқжҢҒи°Ёж…ҺгҖӮ
йҷ·иҝӣ3пјҡеңЁжҜ”иҫғдәәе’ҢжңәеҷЁж—¶пјҢе®һйӘҢжқЎд»¶еә”иҜҘжҳҜе®Ңе…ЁзӣёеҗҢзҡ„гҖӮ
иҜ·зңӢдёӢйқўе·Ұиҫ№иҝҷеј еӣҫгҖӮеҫҲжҳҺжҳҫдҪ еҸҜд»ҘзңӢеҲ°дёҖеүҜзңјй•ңпјҢзҺ°еңЁеҰӮжһңзЁҚеҫ®иЈҒеүӘдёҖдёӢз…§зүҮпјҢжҲ‘们д»Қ然еҸҜд»Ҙжё…жҷ°ең°зңӢеҲ°жҳҜдёҖеүҜзңјй•ңгҖӮ继з»ӯиЈҒеүӘеҮ ж¬ЎпјҢжҲ‘们д»Қ然иғҪеӨҹиҜҶеҲ«еҮәиҝҷжҳҜдёҖеүҜзңјй•ңгҖӮ
然иҖҢпјҢд»ҺжҹҗдёӘж—¶еҲ»ејҖе§ӢпјҢжғ…еҶөе°ұеҸ‘з”ҹдәҶеҸҳеҢ–пјҡжҲ‘们дёҚиғҪеҶҚиҜҶеҲ«еҮәиҝҷжҳҜеүҜзңјй•ңдәҶгҖӮ
д»ҺеҸҜд»ҘиҜҶеҲ«еҮәзү©дҪ“зҡ„иЈҒеүӘиҝҮжёЎеҲ°ж— жі•иҜҶеҲ«еҮәзү©дҪ“зҡ„иЈҒеүӘпјҢе…¶дёӯжңүи¶Јзҡ„дёҖзӮ№жҳҜе®ғзҡ„жё…жҷ°еәҰзҡ„еҸҳеҢ–пјҡз•ҘеӨ§зҡ„иЈҒеүӘпјҲжҲ‘们称д№ӢдёәвҖңжңҖе°ҸеҸҜиҜҶеҲ«иЈҒеүӘвҖқпјүиғҪеӨҹиў«еӨ§еӨҡж•°дәәжӯЈзЎ®еҲҶзұ»пјҲдҫӢеҰӮ90%пјүпјҢиҖҢз•Ҙе°Ҹзҡ„иЈҒеүӘ(жңҖеӨ§дёҚеҸҜиҜҶеҲ«иЈҒеүӘ)еҸӘжңүе°‘ж•°еҮ дёӘдәәпјҲдҫӢеҰӮ20%пјүиғҪжӯЈзЎ®ең°еҲҶзұ»гҖӮиҝҷдёӘиҜҶеҲ«еәҰзҡ„йҷҚдҪҺиў«з§°дёәвҖңеҸҜиҜҶеҲ«е·®вҖқ(еҸҜеҸӮиҖғUllman зӯүдәә 2016е№ҙзҡ„е·ҘдҪң)гҖӮе®ғзҡ„и®Ўз®—ж–№жі•жҳҜд»ҺжӯЈзЎ®еҲҶзұ»вҖңжңҖе°ҸеҸҜиҜҶеҲ«иЈҒеүӘзү©вҖқзҡ„дәәзҡ„жҜ”дҫӢдёӯеҮҸеҺ»жӯЈзЎ®еҲҶзұ»вҖңжңҖеӨ§дёҚеҸҜиҜҶеҲ«иЈҒеүӘзү©вҖқзҡ„дәәзҡ„жҜ”дҫӢгҖӮеңЁдёӢйқўзҡ„еӣҫдёӯпјҢеҸҜиҜҶеҲ«е·®дёәпјҡ0.9 - 0.2 = 0.7гҖӮ
жҺЁиҚҗйҳ…иҜ»















- иҝӣиЎҢ|вҖңдә’иҒ”зҪ‘ж—¶д»Ј+вҖқиғҢжҷҜдёӢе“ҒзүҢз«ҘиЈ…жҠҳжүЈеә—зҡ„еҸ‘еұ•еҜ№зӯ–з ”з©¶
- |гҖҠжҲ‘зҡ„еҘіеҸӢжҳҜжңәеҷЁдәәгҖӢйҰ–жӣқиҠұзө®пјҢиҫӣиҠ·и•ҫеҢ…иҙқе°”жҗһжҖӘ
- жһ—еҝ—йў–|еҪ“жҳҺжҳҹйғҪе«ҢжқҘй’ұж…ўпјҹжһ—еҝ—йў–з ”з©¶иҮӘе·ұпјҢеј еәӯеӨ«еҰҮеҚ–йқўиҶң
- з–ҜзӢӮжҠ№й»‘пјҒдёӨеҗҚдёӯеӣҪзұҚй«ҳж Ўз ”з©¶дәәе‘ҳеңЁзҫҺиў«жҚ•пјҢзҫҺеҸёжі•йғЁе®Јз§°е…¶вҖңз ҙеқҸиҜҒжҚ®вҖқвҖңзӘғеҸ–жңәеҜҶвҖқ
- жңәеҷЁдәә|AIи®ӯз»ғеёҲи®©жңәеҷЁдәәжӣҙиҒӘжҳҺ
- жҫіеӨ§еҲ©дәҡжҲҳз•Ҙж”ҝзӯ–з ”з©¶жүҖпјҡиҮӯеҗҚжҳӯи‘—зҡ„вҖңзүөзәҝжңЁеҒ¶вҖқпјҒ
- иө·еә•жҫіеӨ§еҲ©дәҡжҲҳз•Ҙж”ҝзӯ–з ”з©¶жүҖпјҡиҮӯеҗҚжҳӯи‘—зҡ„вҖңзүөзәҝжңЁеҒ¶вҖқпјҒ
- гҖҢж–°жөӘ科жҠҖгҖҚиҜҰ解马ж–Ҝе…ӢNeuralinkеӨ–科жүӢжңҜжңәеҷЁдәәж–°жөӘ科жҠҖ2020-08-29 08:30:180йҳ…
- IT|з ”з©¶еҸ‘зҺ°ж— зҘһи®әиҖ…еңЁзқЎзң иҙЁйҮҸж–№йқўиғңиҝҮе®—ж•ҷж•ҷеҫ’
- и®әж–Ү|дёӯ科еӨ§еӯҰжңҜ委е‘ҳдјҡеӣһеә”вҖңжғ…дҫЈйҖҒзӨјз ”究вҖқеҚҡеЈ«и®әж–ҮпјҡдёҚиҜ„д»·еҘҪеқҸ