еӯӨзӢ¬й…’йҰҶ|6000+еӯ—пјҢ30+еј еӣҫгҖӮJAVAзәҝдёҠж•…йҡңжҺ’жҹҘе…ЁеҘ—и·ҜжҖ»з»“( еӣӣ )
NMTжҳҜJava7U40еј•е…Ҙзҡ„HotSpotж–°зү№жҖ§ пјҢ й…ҚеҗҲjcmdе‘Ҫд»ӨжҲ‘们е°ұеҸҜд»ҘзңӢеҲ°е…·дҪ“еҶ…еӯҳз»„жҲҗдәҶ гҖӮ йңҖиҰҒеңЁеҗҜеҠЁеҸӮж•°дёӯеҠ е…Ҙ -XX:NativeMemoryTracking=summary жҲ–иҖ… -XX:NativeMemoryTracking=detail пјҢ дјҡжңүз•Ҙеҫ®жҖ§иғҪжҚҹиҖ— гҖӮ
дёҖиҲ¬еҜ№дәҺе ҶеӨ–еҶ…еӯҳзј“ж…ўеўһй•ҝзӣҙеҲ°зҲҶзӮёзҡ„жғ…еҶөжқҘиҜҙ пјҢ еҸҜд»Ҙе…Ҳи®ҫдёҖдёӘеҹәзәҝjcmd pid VM.native_memory baseline гҖӮ
然еҗҺзӯүж”ҫдёҖж®өж—¶й—ҙеҗҺеҶҚеҺ»зңӢзңӢеҶ…еӯҳеўһй•ҝзҡ„жғ…еҶө пјҢ йҖҡиҝҮjcmd pid VM.native_memory detail.diff(summary.diff)еҒҡдёҖдёӢsummaryжҲ–иҖ…detailзә§еҲ«зҡ„diff гҖӮ
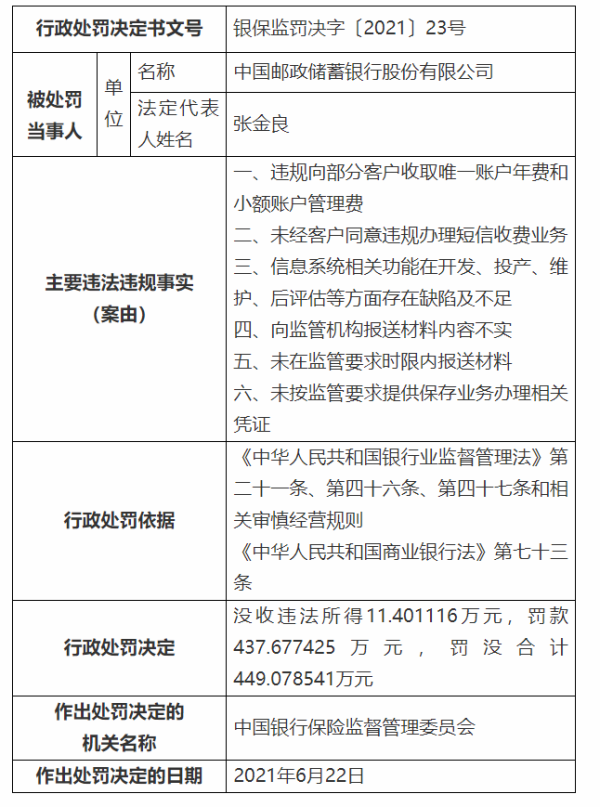
еҸҜд»ҘзңӢеҲ°jcmdеҲҶжһҗеҮәжқҘзҡ„еҶ…еӯҳеҚҒеҲҶиҜҰз»Ҷ пјҢ еҢ…жӢ¬е ҶеҶ…гҖҒзәҝзЁӢд»ҘеҸҠgc(жүҖд»ҘдёҠиҝ°е…¶д»–еҶ…еӯҳејӮеёёе…¶е®һйғҪеҸҜд»Ҙз”ЁnmtжқҘеҲҶжһҗ) пјҢ иҝҷиҫ№е ҶеӨ–еҶ…еӯҳжҲ‘们йҮҚзӮ№е…іжіЁInternalзҡ„еҶ…еӯҳеўһй•ҝ пјҢ еҰӮжһңеўһй•ҝеҚҒеҲҶжҳҺжҳҫзҡ„иҜқйӮЈе°ұжҳҜжңүй—®йўҳдәҶ гҖӮ detailзә§еҲ«зҡ„иҜқиҝҳдјҡжңүе…·дҪ“еҶ…еӯҳж®өзҡ„еўһй•ҝжғ…еҶө пјҢ еҰӮдёӢеӣҫ гҖӮ
жӯӨеӨ–еңЁзі»з»ҹеұӮйқў пјҢ жҲ‘们иҝҳеҸҜд»ҘдҪҝз”Ёstraceе‘Ҫд»ӨжқҘзӣ‘жҺ§еҶ…еӯҳеҲҶй…Қ strace -f -e "brk,mmap,munmap" -p pidиҝҷиҫ№еҶ…еӯҳеҲҶй…ҚдҝЎжҒҜдё»иҰҒеҢ…жӢ¬дәҶpidе’ҢеҶ…еӯҳең°еқҖ гҖӮ
дёҚиҝҮе…¶е®һдёҠйқўйӮЈдәӣж“ҚдҪңд№ҹеҫҲйҡҫе®ҡдҪҚеҲ°е…·дҪ“зҡ„й—®йўҳзӮ№ пјҢ е…ій”®иҝҳжҳҜиҰҒзңӢй”ҷиҜҜж—Ҙеҝ—ж Ҳ пјҢ жүҫеҲ°еҸҜз–‘зҡ„еҜ№иұЎ пјҢ жҗһжё…жҘҡе®ғзҡ„еӣһ收жңәеҲ¶ пјҢ 然еҗҺеҺ»еҲҶжһҗеҜ№еә”зҡ„еҜ№иұЎ гҖӮ жҜ”еҰӮDirectByteBufferеҲҶй…ҚеҶ…еӯҳзҡ„иҜқ пјҢ жҳҜйңҖиҰҒfull GCжҲ–иҖ…жүӢеҠЁsystem.gcжқҘиҝӣиЎҢеӣһ收зҡ„(жүҖд»ҘжңҖеҘҪдёҚиҰҒдҪҝз”Ё-XX:+DisableExplicitGC) гҖӮ йӮЈд№Ҳе…¶е®һжҲ‘们еҸҜд»Ҙи·ҹиёӘдёҖдёӢDirectByteBufferеҜ№иұЎзҡ„еҶ…еӯҳжғ…еҶө пјҢ йҖҡиҝҮjmap -histo:live pidжүӢеҠЁи§ҰеҸ‘fullGCжқҘзңӢзңӢе ҶеӨ–еҶ…еӯҳжңүжІЎжңүиў«еӣһ收 гҖӮ еҰӮжһңиў«еӣһ收дәҶ пјҢ йӮЈд№ҲеӨ§жҰӮзҺҮжҳҜе ҶеӨ–еҶ…еӯҳжң¬иә«еҲҶй…Қзҡ„еӨӘе°ҸдәҶ пјҢ йҖҡиҝҮ-XX:MaxDirectMemorySizeиҝӣиЎҢи°ғж•ҙ гҖӮ еҰӮжһңжІЎжңүд»Җд№ҲеҸҳеҢ– пјҢ йӮЈе°ұиҰҒдҪҝз”ЁjmapеҺ»еҲҶжһҗйӮЈдәӣдёҚиғҪиў«gcзҡ„еҜ№иұЎ пјҢ д»ҘеҸҠе’ҢDirectByteBufferд№Ӣй—ҙзҡ„еј•з”Ёе…ізі»дәҶ гҖӮ
GCй—®йўҳе ҶеҶ…еҶ…еӯҳжі„жјҸжҖ»жҳҜе’ҢGCејӮеёёзӣёдјҙ гҖӮ дёҚиҝҮGCй—®йўҳдёҚеҸӘжҳҜе’ҢеҶ…еӯҳй—®йўҳзӣёе…і пјҢ иҝҳжңүеҸҜиғҪеј•иө·CPUиҙҹиҪҪгҖҒзҪ‘з»ңй—®йўҳзӯүзі»еҲ—并еҸ‘з—Ү пјҢ еҸӘжҳҜзӣёеҜ№жқҘиҜҙе’ҢеҶ…еӯҳиҒ”зі»зҙ§еҜҶдәӣ пјҢ жүҖд»ҘжҲ‘们еңЁжӯӨеҚ•зӢ¬жҖ»з»“дёҖдёӢGCзӣёе…ій—®йўҳ гҖӮ
жҲ‘们еңЁcpuз« д»Ӣз»ҚдәҶдҪҝз”ЁjstatжқҘиҺ·еҸ–еҪ“еүҚGCеҲҶд»ЈеҸҳеҢ–дҝЎжҒҜ гҖӮ иҖҢжӣҙеӨҡж—¶еҖҷ пјҢ жҲ‘们жҳҜйҖҡиҝҮGCж—Ҙеҝ—жқҘжҺ’жҹҘй—®йўҳзҡ„ пјҢ еңЁеҗҜеҠЁеҸӮж•°дёӯеҠ дёҠ-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStampsжқҘејҖеҗҜGCж—Ҙеҝ— гҖӮ еёёи§Ғзҡ„Young GCгҖҒFull GCж—Ҙеҝ—еҗ«д№үеңЁжӯӨе°ұдёҚеҒҡиөҳиҝ°дәҶ гҖӮ
й’ҲеҜ№gcж—Ҙеҝ— пјҢ жҲ‘们е°ұиғҪеӨ§иҮҙжҺЁж–ӯеҮәyoungGCдёҺfullGCжҳҜеҗҰиҝҮдәҺйў‘з№ҒжҲ–иҖ…иҖ—ж—¶иҝҮй•ҝ пјҢ д»ҺиҖҢеҜ№з—ҮдёӢиҚҜ гҖӮ жҲ‘们дёӢйқўе°ҶеҜ№G1еһғеңҫ收йӣҶеҷЁжқҘеҒҡеҲҶжһҗ пјҢ иҝҷиҫ№д№ҹе»әи®®еӨ§е®¶дҪҝз”ЁG1-XX:+UseG1GC гҖӮ
youngGCиҝҮйў‘з№ҒyoungGCйў‘з№ҒдёҖиҲ¬жҳҜзҹӯе‘Ёжңҹе°ҸеҜ№иұЎиҫғеӨҡ пјҢ е…ҲиҖғиҷ‘жҳҜдёҚжҳҜEdenеҢә/ж–°з”ҹд»Ји®ҫзҪ®зҡ„еӨӘе°ҸдәҶ пјҢ зңӢиғҪеҗҰйҖҡиҝҮи°ғж•ҙ-XmnгҖҒ-XX:SurvivorRatioзӯүеҸӮж•°и®ҫзҪ®жқҘи§ЈеҶій—®йўҳ гҖӮ еҰӮжһңеҸӮж•°жӯЈеёё пјҢ дҪҶжҳҜyoung gcйў‘зҺҮиҝҳжҳҜеӨӘй«ҳ пјҢ е°ұйңҖиҰҒдҪҝз”ЁJmapе’ҢMATеҜ№dumpж–Ү件иҝӣиЎҢиҝӣдёҖжӯҘжҺ’жҹҘдәҶ гҖӮ
youngGCиҖ—ж—¶иҝҮй•ҝиҖ—ж—¶иҝҮй•ҝй—®йўҳе°ұиҰҒзңӢGCж—Ҙеҝ—йҮҢиҖ—ж—¶иҖ—еңЁе“ӘдёҖеқ—дәҶ гҖӮ д»ҘG1ж—Ҙеҝ—дёәдҫӢ пјҢ еҸҜд»Ҙе…іжіЁRoot ScanningгҖҒObject CopyгҖҒRef Procзӯүйҳ¶ж®ө гҖӮ Ref ProcиҖ—ж—¶й•ҝ пјҢ е°ұиҰҒжіЁж„Ҹеј•з”Ёзӣёе…ізҡ„еҜ№иұЎ гҖӮ Root ScanningиҖ—ж—¶й•ҝ пјҢ е°ұиҰҒжіЁж„ҸзәҝзЁӢж•°гҖҒи·Ёд»Јеј•з”Ё гҖӮ Object CopyеҲҷйңҖиҰҒе…іжіЁеҜ№иұЎз”ҹеӯҳе‘Ёжңҹ гҖӮ иҖҢдё”иҖ—ж—¶еҲҶжһҗе®ғйңҖиҰҒжЁӘеҗ‘жҜ”иҫғ пјҢ е°ұжҳҜе’Ңе…¶д»–йЎ№зӣ®жҲ–иҖ…жӯЈеёёж—¶й—ҙж®өзҡ„иҖ—ж—¶жҜ”иҫғ гҖӮ жҜ”еҰӮиҜҙеӣҫдёӯзҡ„Root Scanningе’ҢжӯЈеёёж—¶й—ҙж®өжҜ”еўһй•ҝиҫғеӨҡ пјҢ йӮЈе°ұжҳҜиө·зҡ„зәҝзЁӢеӨӘеӨҡдәҶ гҖӮ
жҺЁиҚҗйҳ…иҜ»















- еӯӨзӢ¬й…’йҰҶ|NVIDIA еҠ©еҠӣж–ҮиҝңзҹҘиЎҢеңЁиҮӘеҠЁй©ҫ驶зҡ„и·ҜдёҠвҖңд№ҳйЈҺз ҙжөӘвҖқ
- еӯӨзӢ¬й…’йҰҶ|ж—Ҙжң¬з ”究жңәжһ„жӢҶи§ЈеҚҺдёәP30 ProпјҡзҫҺдјҒйӣ¶йғЁд»¶жҜ”дҫӢдёҚеҲ°1%
- жіҪе®Үи®ІеҺҶеҸІ|еҘіе„ҝеҒҡдәҶеӨ–еӣҪзҡҮеҗҺпјҢдёҚж„ҝеҗ‘ж—Ҙжң¬жұӮеҠ©пјҢ49еІҒеӯӨзӢ¬еҺ»дё–пјҢзҲ¶дәІжҳҜеҚҺдәә
- зҺҜзҗғзҪ‘|вҖңдё–з•ҢдёҠжңҖеӯӨзӢ¬зҡ„еӨ§иұЎвҖқиў«и§Јж•‘пјҢжӣҫиў«е…ідәҶж•ҙж•ҙ35е№ҙ
- ж–°йІңдәӢе„ҝ|еҚҙиў«жёЈз”·жҠӣејғз»Ҳиә«дёҚеӯ•пјҢиҖҢд»ҠеӯӨзӢ¬дёҖдәәпјҢеҘ№жҳҜ80е№ҙд»ЈжңҖзҒ«зҡ„вҖңзҗјз‘¶еҘійғҺвҖқ
- вҖңдё–з•ҢдёҠжңҖеӯӨзӢ¬зҡ„еӨ§иұЎвҖқиў«и§Јж•‘пјҢжӣҫиў«е…ідәҶж•ҙж•ҙ35е№ҙ
- дё–з•ҢдёҠжңҖеӯӨзӢ¬зҡ„еӨ§иұЎиў«и§Јж•‘пјҡвҖңдё–з•ҢдёҠжңҖеӯӨзӢ¬зҡ„еӨ§иұЎвҖқиў«и§Јж•‘пјҢжӣҫиў«е…ідәҶж•ҙж•ҙ35е№ҙ
- kaavan|д»Һе°Ҹиў«еҪ“иөҡй’ұе·Ҙе…·пјҢ35е№ҙеҗҺпјҢдё–з•ҢдёҠжңҖеӯӨзӢ¬зҡ„еӨ§иұЎз»ҲдәҺи§Јж”ҫдәҶвҖҰвҖҰ
- гҖҢеӯӨзӢ¬гҖҚд№қжңҲпјҢеҘҪеҘҪз”ҹжҙ»пјҢеҘҪеҘҪзҲұ
- зҒөйӯӮдјҙдҫЈ|еҪ“еҒ¶еғҸжңүеӨҡеӯӨзӢ¬пјҹвҖңйҹ©еӣҪжңҖзҫҺзҡ„з”·дәәвҖқ38еІҒж”№еҸҳеҪўиұЎпјҢжӣҫз»Ҹзҡ„зҒөйӯӮдјҙдҫЈе·ІиҪ¬е«Ғд»–дәә