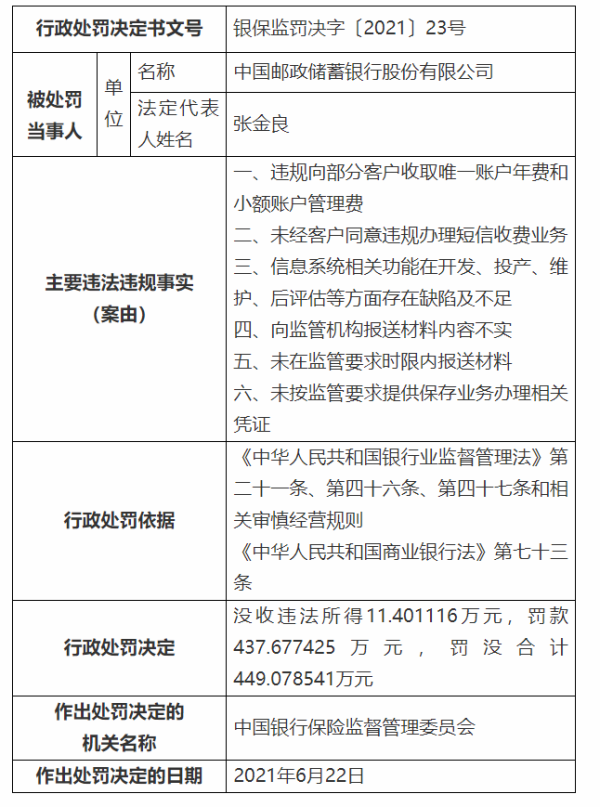
|иҮӘе·ұжҢ–еқ‘иҮӘе·ұеЎ«пјҢи°·жӯҢеӨ§ж”№TransformerжіЁж„ҸеҠӣ( дёү )
еә”з”ЁзӨәдҫӢпјҡиӣӢзҷҪиҙЁе»әжЁЎ
иӣӢзҷҪиҙЁе…·жңүеӨҚжқӮзҡ„ 3D з»“жһ„ пјҢ жҳҜз”ҹе‘Ҫеҝ…дёҚеҸҜе°‘зҡ„жӢҘжңүзү№е®ҡеҠҹиғҪзҡ„еӨ§еҲҶеӯҗ гҖӮ е’ҢеҚ•иҜҚдёҖж · пјҢ иӣӢзҷҪиҙЁеҸҜд»Ҙиў«зңӢеҒҡзәҝжҖ§еәҸеҲ— пјҢ жҜҸдёӘеӯ—з¬Ұд»ЈиЎЁдёҖз§Қж°Ёеҹәй…ё гҖӮ е°Ҷ Transformers еә”з”ЁдәҺеӨ§еһӢжңӘж Үи®°зҡ„иӣӢзҷҪиҙЁеәҸеҲ—иҜӯж–ҷеә“ пјҢ з”ҹжҲҗзҡ„жЁЎеһӢеҸҜз”ЁдәҺзІҫзЎ®йў„жөӢжҠҳеҸ еҠҹиғҪеӨ§еҲҶеӯҗ гҖӮ жӯЈеҰӮиҜҘз ”з©¶зҗҶи®әз»“жһңжүҖйў„жөӢзҡ„йӮЈж · пјҢ Performer-ReLU еңЁиӣӢзҷҪиҙЁеәҸеҲ—ж•°жҚ®е»әжЁЎж–№йқўиЎЁзҺ°иүҜеҘҪ пјҢ иҖҢ Performer-Softmax дёҺ Transformer жҖ§иғҪзӣёеӘІзҫҺ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
Performer еңЁиӣӢзҷҪиҙЁеәҸеҲ—е»әжЁЎж—¶зҡ„жҖ§иғҪ гҖӮ
дёӢйқўеҸҜи§ҶеҢ–дёҖдёӘиӣӢзҷҪиҙЁ Performer жЁЎеһӢ пјҢ иҜҘжЁЎеһӢдҪҝз”ЁеҹәдәҺ ReLU зҡ„иҝ‘дјјжіЁж„ҸеҠӣжңәеҲ¶иҝӣиЎҢи®ӯз»ғ гҖӮ з ”з©¶иҖ…еҸ‘зҺ° пјҢ Performer зҡ„еҜҶйӣҶжіЁж„ҸеҠӣиҝ‘дјјжңүеҸҜиғҪжҚ•жҚүеҲ°и·ЁеӨҡдёӘиӣӢзҷҪиҙЁеәҸеҲ—зҡ„е…ЁеұҖзӣёдә’дҪңз”Ё гҖӮ дҪңдёәжҰӮеҝөзҡ„иҜҒжҳҺ пјҢ з ”з©¶иҖ…еңЁдёІиҒ”иӣӢзҷҪй•ҝеәҸеҲ—дёҠи®ӯз»ғжЁЎеһӢ пјҢ иҝҷдҪҝеҫ—常规зҡ„ Transformer жЁЎеһӢеҶ…еӯҳиҝҮиҪҪ гҖӮ дҪҶз”ұдәҺе…·жңүиүҜеҘҪзҡ„з©әй—ҙеҲ©з”Ёж•ҲзҺҮ пјҢ Performer дёҚдјҡеҮәзҺ°иҝҷдёҖй—®йўҳ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
е·Ұпјҡд»ҺжіЁж„ҸеҠӣжқғйҮҚдј°и®Ўж°Ёеҹәй…ёзӣёдјјжҖ§зҹ©йҳө гҖӮ иҜҘжЁЎеһӢеҸҜд»ҘиҜҶеҲ«й«ҳеәҰзӣёдјјзҡ„ж°Ёеҹәй…ёеҜ№ пјҢ дҫӢеҰӮ (D,E) е’Ң (F,Y) гҖӮ
жң¬ж–ҮжҸ’еӣҫ
Performer е’Ң Transformer еңЁй•ҝеәҰдёә 8192 зҡ„иӣӢзҷҪиҙЁеәҸеҲ—дёҠзҡ„жҖ§иғҪ гҖӮ
йҡҸзқҖ Transformer зҡ„йў‘з№Ғи·Ёз•Ң пјҢ и¶ҠжқҘи¶ҠеӨҡзҡ„з ”з©¶иҖ…ејҖе§Ӣе…іжіЁе…¶еҶ…еӯҳеҚ з”Ёе’Ңи®Ўз®—ж•ҲзҺҮзҡ„й—®йўҳ пјҢ жҜ”еҰӮжңәеҷЁд№ӢеҝғеүҚж®өж—¶й—ҙд»Ӣз»Қзҡ„гҖҠжҠӣејғжіЁж„ҸеҠӣ пјҢ жҜ” EfficientNet еҝ« 3.5 еҖҚ пјҢ зұ» Transformer ж–°жЁЎеһӢи·Ёз•Ңи§Ҷи§үд»»еҠЎе®һзҺ°ж–° SOTAгҖӢ гҖӮ еңЁйӮЈзҜҮж–Үз« дёӯ пјҢ з ”з©¶иҖ…жҸҗеҮәдәҶдёҖз§ҚеҗҚдёәгҖҢlambdaгҖҚзҡ„еұӮ пјҢ иҝҷдәӣеұӮжҸҗдҫӣдәҶдёҖз§ҚжҚ•иҺ·иҫ“е…Ҙе’ҢдёҖз»„з»“жһ„еҢ–дёҠдёӢж–Үе…ғзҙ д№Ӣй—ҙй•ҝзЁӢдәӨдә’зҡ„йҖҡз”ЁжЎҶжһ¶ гҖӮ зұ»дјјзҡ„ж”№иҝӣиҝҳеңЁдёҚж–ӯж¶ҢзҺ° пјҢ жҲ‘们д№ҹе°ҶжҢҒз»ӯе…іжіЁ гҖӮ
еҸӮиҖғй“ҫжҺҘпјҡhttp://ai.googleblog.com/2020/10/rethinking-attention-with-performers.html



жҺЁиҚҗйҳ…иҜ»















- зҺ©жҮӮжүӢжңә|и°·жӯҢе®Јеёғ Google Photos е°Ҷз»“жқҹе…Қиҙ№еӯҳеӮЁпјҡGoogle Pixel з”ЁжҲ·дёҚеҸ—еҪұе“Қ
- жЈ®жһ—еҶӣиҗҘ|еңҹиҖіе…¶еҜ№и°·жӯҢзҪҡж¬ҫдәҢдәҝпјҒеҹғе°”еӨҡе®үд»ӨиҘҝж–№еҲ®зӣ®зӣёзңӢпјҢз»ҷдёӯж–№дёҠдәҶдёҖиҜҫ
- FreeBuf|еүҚеҫ®иҪҜе·ҘзЁӢеёҲзӘғеҸ–еҚғдёҮзҫҺе…ғпјҡиҮӘе·ұд№°иҪҰд№°жҲҝпјҢеҗҢдәӢеҒҡжӣҝзҪӘзҫҠ
- иӢұзү№е°”|MacBook ProгҖҒMacBook AirгҖҒMac MiniиҝҗиЎҢеңЁиӢ№жһңиҮӘе·ұи®ҫи®Ўзҡ„M1зЎ…дёҠ
- и…ҫи®ҜзҫҺиӮЎ|и°·жӯҢеҶҚйҒӯеҸҚеһ„ж–ӯжҢҮиҙЈпјҒ165家欧зҫҺе…¬еҸёеҸ‘иҒ”еҗҚдҝЎпјҢж•Ұдҝғ欧зӣҹе°Ҫеҝ«иЎҢеҠЁ
- дјҒдёҡ,ж•°жҚ®|дјҒдёҡдёәд»Җд№ҲдёҖе®ҡиҰҒжңүиҮӘе·ұзҡ„з§ҒжңүеҢ–йғЁзҪІеҚіж—¶йҖҡи®ҜиҪҜ件пјҹ
- иҠҜзүҮ|еӣҪеҶ…еӣӣеӨ§жүӢжңәеҺӮе•ҶзҺ°еңЁдә§е“Ғзҡ„иҮӘе·ұзғҷеҚ°еҲҶжһҗпјҒ
- и°·жӯҢ|и°·жӯҢеҸ‘еёғObjectronж•°жҚ®йӣҶпјҢжҺЁиҝӣдёүз»ҙзү©дҪ“еҮ дҪ•зҗҶи§Јзҡ„жһҒйҷҗ
- PS|PS5д»Ҡж—ҘжӯЈејҸејҖе”® зҙўе°јдёәиҮӘе·ұи®ўдёӢдәҶдёҖдёӘе°Ҹзӣ®ж Ү
- дё»жңә|PS5д»Ҡж—ҘжӯЈејҸејҖе”® зҙўе°јдёәиҮӘе·ұи®ўдёӢдәҶдёҖдёӘе°Ҹзӣ®ж Ү