ж–°зҡ„еӨ§иҲӘжө·ж—¶д»Јпјҡд»Җд№ҲжҳҜвҖңиҷҡжӢҹдё–з•ҢвҖқпјҹ( дёғ )
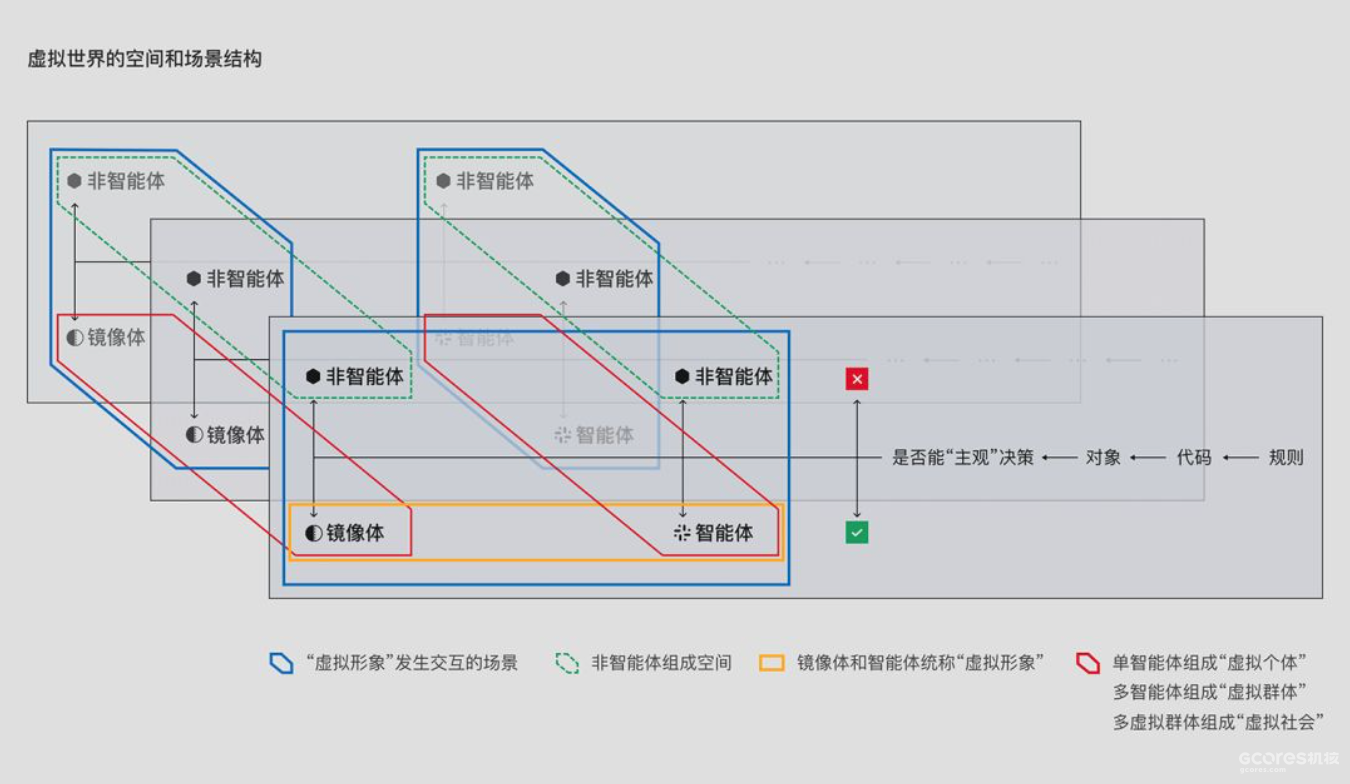
еңЁиҷҡжӢҹдё–з•Ңдёӯ пјҢ жңҖеә•еұӮзҡ„规еҲҷжҳҜ 1 е’Ң 0 з»„жҲҗзҡ„ пјҢ 然еҗҺеңЁжӯӨеҹәзЎҖдёҠеҪўжҲҗдәҶд»Јз Ғе’Ңеҗ„з§ҚжҠҖжңҜжЎҶжһ¶ пјҢ жҺҘзқҖдәә们еҲ©з”Ёиҝҷдәӣд»Јз Ғ пјҢ жү“йҖ дәҶдёҖзі»еҲ—зҡ„ж•°еӯ—еҢ–еҜ№иұЎ гҖӮ жҲ‘们жүҖзңӢеҲ°зҡ„еҗ„з§Қз”өеӯҗжёёжҲҸгҖҒйҹід№җгҖҒеӣҫзүҮгҖҒжөҸи§ҲеҷЁзӯүзӯү пјҢ йғҪжҳҜиҷҡжӢҹдё–з•ҢйҮҢзҡ„ж•°еӯ—еҢ–еҜ№иұЎ гҖӮеҗҢж · пјҢ жҲ‘们еҸӮиҖғзңҹе®һдё–з•Ңдёӯзү©дҪ“зҡ„еҲҶзұ»ж–№жі• пјҢ йҖҡиҝҮеҲӨж–ӯж•°еӯ—еҢ–еҜ№иұЎжҳҜеҗҰиғҪвҖңдё»и§ӮвҖқеҶізӯ– пјҢ жқҘеҜ№е®ғ们иҝӣиЎҢеҢәеҲҶ гҖӮ дәӢе®һдёҠ пјҢ иҝҷж ·еҲҶзұ»зҡ„ж„Ҹд№ү пјҢ дёҚд»…дёәдәҶе’Ңзңҹе®һдё–з•Ңдёӯзҡ„ж–№ејҸдҝқжҢҒз»ҹдёҖ пјҢ д№ҹз¬ҰеҗҲдәҶдәә们еҜ№дәҺж•°еӯ—еҢ–жҷәиғҪдҪ“зҡ„жҺўзҙўдёҺжңҹжңӣ гҖӮеңЁ 1950 е№ҙзҡ„иҝҷзҜҮ Computing machinery and intelligence и®әж–ҮйҮҢ пјҢ ж•°еӯҰ家 Alan Turing иҜҰз»Ҷи®Ёи®әдәҶвҖңжңәеҷЁиғҪеҗҰжӢҘжңүжҷәиғҪвҖқзҡ„й—®йўҳ гҖӮ дәӢе®һдёҠ пјҢ еӣҫзҒөжҲҗеҠҹе®ҡд№үдәҶд»Җд№ҲжҳҜжңәеҷЁ пјҢ дҪҶд»–еҚҙдёҚиғҪе®ҡд№үд»Җд№ҲжҳҜжҷәиғҪ гҖӮ еҗҢж—¶ пјҢ д»–иҮӘе·ұд№ҹиҜҙиҝҮвҖңдәәзұ»иҮӘе·ұе°ұж— жі•еҸҚиҝҮжқҘжҲҗеҠҹдјӘиЈ…жҲҗжңәеҷЁвҖқ пјҢ 并жҸҗеҮәдәҶдёҖдёӘеҸҚй—®вҖңйҡҫйҒ“иў«и®ӨдёәжӢҘжңүжҷәиғҪзҡ„жңәеҷЁ пјҢ е°ұдёҚиғҪиЎЁзҺ°еҮәе’Ңдәәзұ»дёҚеҗҢзҡ„иЎҢдёәеҗ—пјҹвҖқ гҖӮ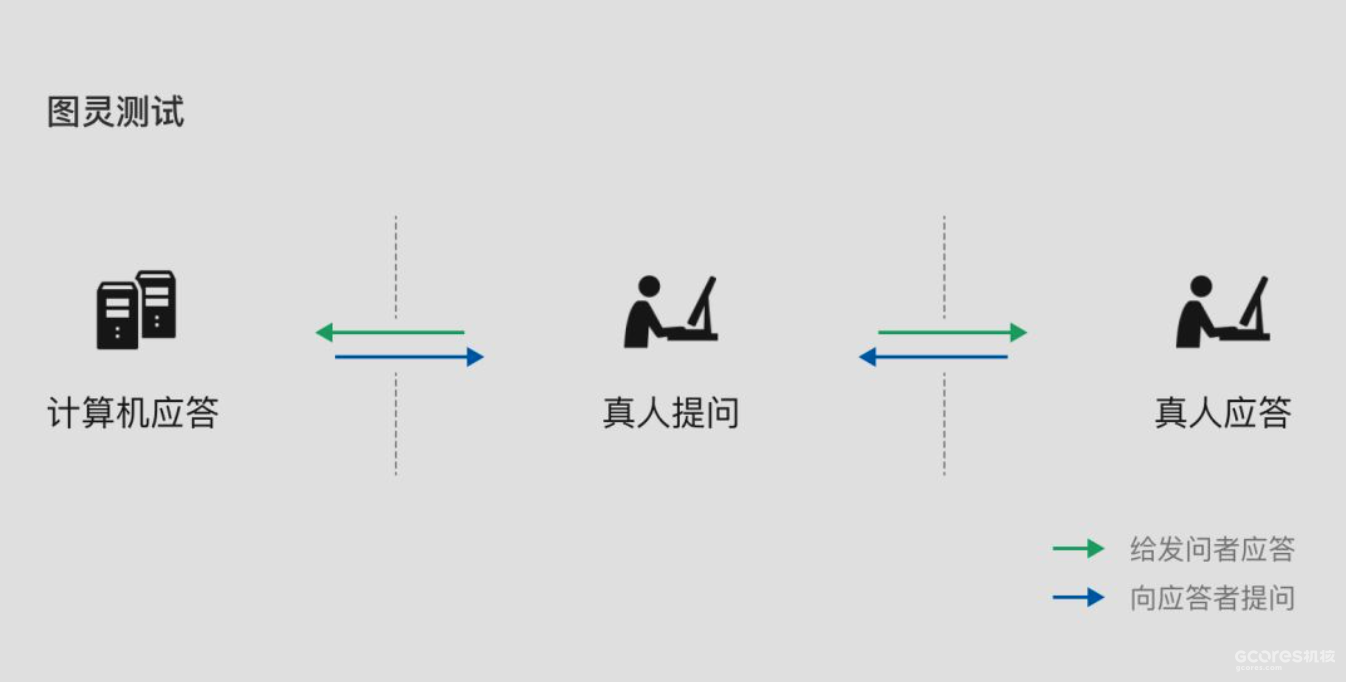
дёҺжӯӨеҗҢж—¶ пјҢ еӨ§йғЁеҲҶзҡ„дәәе·ҘжҷәиғҪзӣёе…із ”究 пјҢ йғҪжҳҜеңЁе…іжіЁпјҡеҰӮдҪ•жЁЎжӢҹдәәзұ»зҡ„зәҜзІ№жҷәиғҪжҙ»еҠЁ пјҢ иҖҢдёҚжҳҜе…ЁйғЁзҡ„и„‘еҠӣжҙ»еҠЁ гҖӮ жҲ–иҖ…жҲ‘们еҸҜд»ҘзҗҶи§Јдёә пјҢ жҲ‘们еҜ№дәҺжҷәиғҪдҪ“зҡ„жңҹжңӣжҳҜпјҡиғҪеғҸдәәдёҖж ·еҺ»еҲӣйҖ гҖӮ дҪҶеҸҚиҝҮжқҘзңӢжҲ‘们иҮӘе·ұ пјҢ дәәзұ»иғҪиҝӣиЎҢеҲӣйҖ зҡ„еүҚжҸҗжҳҜеҸҜд»ҘжҢүз…§иҮӘе·ұзҡ„ж„Ҹж„ҝиҝӣиЎҢеҶізӯ– пјҢ д№ҹе°ұжҳҜдё»и§ӮеҶізӯ– гҖӮеӣ жӯӨ пјҢ жҲ‘们е°ҶиҷҡжӢҹдё–з•Ңдёӯзҡ„еҜ№иұЎеҲҶдёәвҖңеҸҜд»Ҙдё»и§ӮеҶізӯ–зҡ„зү©дҪ“вҖқе’ҢвҖңдёҚиғҪдё»и§ӮеҶізӯ–зҡ„зү©дҪ“вҖқ пјҢ д»ҺиҖҢеҢәеҲҶе…¶жҷәиғҪжҖ§ гҖӮзҗҶжғізҠ¶жҖҒдёӢ пјҢ еҸҜд»ҘиҝӣиЎҢвҖңдё»и§ӮвҖқеҶізӯ–зҡ„жҷәиғҪдҪ“иғҪеӨҹеңЁиҷҡжӢҹдё–з•ҢдёӯиҮӘдё»ең°еҲӣйҖ дҝЎжҒҜе’Ңзү©иҙЁ пјҢ иҖҢе…¶д»–зҡ„йқһжҷәиғҪдҪ“ж—ўеҸҜд»ҘжҳҜжқҘжәҗдәҺдәәдёәи®ҫи®Ў пјҢ д№ҹеҸҜд»ҘжҳҜжқҘжәҗдәҺжҷәиғҪдҪ“зҡ„дё»еҠЁз”ҹжҲҗ гҖӮ еӣ жӯӨ пјҢ иҝҷдәӣйқһжҷәиғҪдҪ“зҡ„з»„еҗҲ пјҢ д№ҹе°ұжһ„жҲҗдәҶиҷҡжӢҹдё–з•Ңзҡ„вҖңз©әй—ҙвҖқ гҖӮ иҝҷйҮҢзҡ„з©әй—ҙжӣҙеӨҡжҢҮзҡ„жҳҜпјҡжҲ‘们еңЁиҷҡжӢҹдё–з•ҢдёӯеҸҜд»Ҙж„ҹеҸ—зҡ„зү©зҗҶз©әй—ҙ пјҢ иҖҢдёҚжҳҜж•°еӯ—з©әй—ҙ гҖӮдҪҶзҺ°е®һжҳҜ пјҢ жҲ‘们зӣ®еүҚзҡ„ AI жҠҖжңҜиҝҳжІЎжңүе®һзҺ°дёҠйқўжүҖжҸҗеҲ°зҡ„еҸҜд»ҘвҖңдё»и§ӮвҖқеҶізӯ–зҡ„жҷәиғҪдҪ“ пјҢ еӣ жӯӨдјҡеӯҳеңЁдёҖдәӣејұеҢ–зүҲжң¬зҡ„жҲҗжһң гҖӮ жңҖејұеҢ–зүҲжң¬зҡ„жҷәиғҪдҪ“жҳҜвҖңй•ңеғҸдҪ“вҖқ пјҢ д№ҹе°ұжҳҜдәә们еңЁиҷҡжӢҹдё–з•Ңдёӯзҡ„еҪўиұЎжҳ е°„ гҖӮд№ӢеүҚеңЁж•°еӯ—еҢ–зҡ„зңҹе®һдё–з•Ңдёӯд№ҹжҸҗеҲ°дәҶ пјҢ жҲ‘们еңЁдә’иҒ”зҪ‘дёҠзҡ„еҗ„з§ҚиҙҰеҸ·е°ұжҳҜдёҖз§ҚвҖңй•ңеғҸдҪ“вҖқ пјҢ иҝҷз§ҚиҷҡжӢҹеҪўиұЎеӨҡд»Ҙж•°жҚ®е‘ҲзҺ° пјҢ жҜ”еҰӮ姓еҗҚгҖҒе№ҙйҫ„иҝҷдәӣжҜ”иҫғзӣҙи§Ӯзҡ„жҸҸиҝ° пјҢ е°ұжҳҜз”ұз”ЁжҲ·иҮӘе·ұеҫҖиҷҡжӢҹдё–з•ҢдёӯжҸҗдҫӣдҝЎжҒҜпјӣиҖҢе…ідәҺдёҖдәӣе–ңеҘҪгҖҒеҒҸеҘҪзӯүжҸҸиҝ° пјҢ е°ұжҳҜйҖҡиҝҮз»ҷз”ЁжҲ·жү“ж Үзӯҫзҡ„ж–№ејҸе®ҢжҲҗ пјҢ жҜ”еҰӮжөҸи§ҲиҝҮд»Җд№Ҳзұ»еһӢзҡ„е•Ҷе“ҒгҖҒйҖҖеҮәеҗҺзҡ„и·Ҝеҫ„жҳҜд»Җд№Ҳзӯүзӯү гҖӮдәӢе®һдёҠ пјҢ иҝҷе°ұжҳҜеӨ§ж•°жҚ®е’ҢжҺЁиҚҗз®—жі•зҡ„ж•Ҳжһң пјҢ еҗҢж—¶иҝҷйғЁеҲҶдҝЎжҒҜеҸҜд»ҘзҗҶи§ЈдёәжҳҜдёҖз§ҚйҖ»иҫ‘еұӮйқўзҡ„дҝЎжҒҜ гҖӮ йҖҡиҝҮж•°жҚ®жқҘе°Ҷзңҹе®һдё–з•Ңдёӯдәәзҡ„еҗ„з§Қз»ҙеәҰдҝЎжҒҜ пјҢ еҪўжҲҗдёҖзі»еҲ—зҡ„йҖ»иҫ‘з»“жһ„ пјҢ дёҠдј еҲ°иҷҡжӢҹдё–з•Ңдёӯ пјҢ йҖҗжёҗдё°еҜҢвҖңй•ңеғҸдҪ“вҖқзҡ„дҝЎжҒҜ гҖӮеҸҰдёҖж–№йқў пјҢ йҷӨдәҶйҖ»иҫ‘з«ҜдҝЎжҒҜ пјҢ дёҖдёӘе®Ңж•ҙзҡ„вҖңй•ңеғҸдҪ“вҖқиҝҳйңҖиҰҒжңүеӣҫеғҸз«ҜдҝЎжҒҜ пјҢ е°ұеғҸдәҶи§ЈдёҖдёӘдәәдёҚд»…йңҖиҰҒеҗ¬д»–иҜҙзҡ„иҜқгҖҒзңӢд»–еҒҡзҡ„дәӢ пјҢ д№ҹйңҖиҰҒжӣҙеҠ зӣҙжҺҘең°зҹҘйҒ“д»–зҡ„дҪ“еһӢгҖҒй•ҝзӣёзӯү гҖӮ еңЁдәә们жңҖејҖе§Ӣиҝӣе…ҘиҷҡжӢҹдё–з•Ңж—¶ пјҢ жҠҖжңҜж°ҙе№ійҷҗеҲ¶дәҶвҖңй•ңеғҸдҪ“вҖқзҡ„иЎЁзҺ°зЁӢеәҰ гҖӮ иҝһжёёжҲҸиҝҷз§ҚйңҖиҰҒйқһеёёејәзҡ„жІүжөёејҸдҪ“йӘҢж•Ҳжһңзҡ„иҷҡжӢҹдҪ“йӘҢ пјҢ йғҪеҸӘиғҪеңЁдёҖејҖе§Ӣз”Ёйқһеёёз®ҖеҚ•зҡ„еӣҫеғҸжқҘиЎЁзӨәиҷҡжӢҹзҡ„еҪўиұЎе’ҢеҶ…е®№пјӣе…¶д»–йўҶеҹҹеә”з”Ёе°ұжӣҙеҠ дёҚдјҡиҝҮеӨҡиҖғиҷ‘еӣҫеғҸдәҶ гҖӮдҪҶйҡҸзқҖжҠҖжңҜзҡ„зӘҒз ҙдёҺиҝӣжӯҘ пјҢ жҲ‘们еҸҜд»ҘеңЁиҷҡжӢҹдё–з•Ңдёӯе®һзҺ°жӣҙеҘҪгҖҒжӣҙзІҫиҮҙзҡ„еӣҫеғҸдәҶ пјҢ д№ҹе°ұжҳҜиҜҙжҲ‘们еңЁиҷҡжӢҹдё–з•ҢйҮҢеҲӣйҖ дәҶж–°зҡ„дҝЎжҒҜ гҖӮ ж №жҚ®дёҠж–ҮжҲ‘们зҹҘйҒ“ пјҢ ж–°зҡ„дҝЎжҒҜдјҡж»Ўи¶іж–°зҡ„йңҖжұӮ пјҢ д»ҺиҖҢеёҰжқҘж–°зҡ„д»·еҖј пјҢ иҝҷд№ҹжҳҜй©ұеҠЁиЎҢдёҡеҸ‘еұ•зҡ„йҮҚиҰҒеҺҹеӣ д№ӢдёҖ гҖӮеңЁиҝҷдёӘиҝҮзЁӢдёӯ пјҢ жҲ‘们дёҚж–ӯзҡ„жҠҠиҮӘе·ұеңЁзңҹе®һдё–з•Ңдёӯзҡ„дҝЎжҒҜиҫ“е…ҘеҲ°иҷҡжӢҹдё–з•Ңдёӯ гҖӮ дёҺзңҹе®һдё–з•ҢдёҚеҗҢзҡ„жҳҜ пјҢ еңЁиҷҡжӢҹдё–з•Ңдёӯ пјҢ жҲ‘们еҸҜд»ҘжңүеҫҲеӨҡдёӘиҷҡжӢҹеҪўиұЎ гҖӮ еҰӮжһңиҝҷдәӣиҷҡжӢҹеҪўиұЎзҡ„дҝЎжҒҜжҳҜе’Ңзңҹе®һдё–з•Ңзҡ„дҝЎжҒҜе®Ңе…ЁдёҖиҮҙ пјҢ йӮЈе°ұжҳҜеұһдәҺж•°еӯ—еҢ–зҡ„зңҹе®һдё–з•ҢпјӣеҰӮжһңжҳҜе®Ңе…ЁдёҚдёҖиҮҙ пјҢ йӮЈе°ұжҳҜеұһдәҺеҺҹз”ҹзҡ„иҷҡжӢҹдё–з•ҢпјӣиҖҢдёҖйғЁеҲҶзӣёеҗҢ пјҢ дёҖйғЁеҲҶдёҚеҗҢж—¶ пјҢ еҲҷеұһдәҺдёӨдёӘдё–з•Ңд№Ӣй—ҙзҡ„иҝҮжёЎйҳ¶ж®ө гҖӮеӣ жӯӨ пјҢ жҲ‘们д№ҹе°Ҷд»ҺвҖңй•ңеғҸдҪ“вҖқеҲ°вҖңжҷәиғҪдҪ“вҖқиҝҷдёҖйғЁеҲҶ пјҢ з»ҹз§°дёәвҖңиҷҡжӢҹеҪўиұЎвҖқ гҖӮ еҸӘдёҚиҝҮз”ұдәҺжҠҖжңҜзҡ„еҸ‘еұ• пјҢ йҷҗеҲ¶дәҶвҖңиҷҡжӢҹеҪўиұЎвҖқзҡ„е‘ҲзҺ°ж–№ејҸдёҺдҝЎжҒҜ гҖӮ дёҖејҖе§Ӣзҡ„иҷҡжӢҹеҪўиұЎжҳҜйқҷжҖҒзҡ„ пјҢ еҗҺжқҘеҸҳжҲҗдәҶеҸҜд»ҘеҠЁжҖҒе‘ҲзҺ°зҡ„ пјҢ дҪҶйңҖиҰҒж¶ҲиҖ—йқһеёёеӨҡдәәеҠӣе’Ңзү©еҠӣ гҖӮдәӢе®һдёҠ пјҢ йқҷжҖҒеӣҫеғҸжҳҜвҖңиҷҡжӢҹеҪўиұЎвҖқзҡ„жңҖеҲқйҳ¶ж®ө пјҢ йӮЈеҹәдәҺдәәе·Ҙйў„е…Ҳи®ҫе®ҡзҡ„еҠЁжҖҒдәӨдә’规еҲҷжүҖжү“йҖ зҡ„вҖңеҠЁжҖҒеҪўиұЎвҖқеҲҷжҳҜвҖңиҷҡжӢҹеҪўиұЎвҖқзҡ„иҝӣдёҖжӯҘеҸ‘еұ• гҖӮдәә们еҸӘйңҖиҰҒй’ҲеҜ№дёҚеҗҢзҡ„з”ЁжҲ·е’ҢеңәжҷҜ пјҢ и®ҫе®ҡдёҚеҗҢзҡ„дәӨдә’еҸҚеә” пјҢ жҜ”еҰӮеҜ№иҜқгҖҒеҠЁдҪңзӯү пјҢ е°ұиғҪи®©иҷҡжӢҹеҪўиұЎеҠЁиө·жқҘ гҖӮ дҪҶиҝҷж— жі•еҒҡеҲ°зңҹжӯЈзҡ„еҠЁжҖҒ пјҢ еӣ дёәиҝҷз§ҚдәӨдә’жҳҜеҹәдәҺ规еҲҷе’Ңи®ҫе®ҡжқҘй©ұеҠЁзҡ„ пјҢ еҸӘиҰҒз”ЁжҲ·жІЎжңүжҢүз…§йў„е…Ҳи®ҫе®ҡеҘҪзҡ„ж–№ејҸиҝӣиЎҢдәӨдә’ пјҢ еҲҷиҷҡжӢҹеҪўиұЎе°ұж— жі•жңүеҜ№еә”зҡ„еҸҚеә” гҖӮдҫӢеҰӮ пјҢ зҺ©е®¶е’ҢжёёжҲҸдёӯ NPC еҜ№иҜқжҲ–иҖ…еҸ‘з”ҹеҠЁдҪңдәӨдә’ж—¶ пјҢ NPC 们еҸӘдјҡжңүеӣәе®ҡзҡ„еҮ з§ҚеҸҚеә”ж–№ејҸпјӣеҗ„з§ҚиҷҡжӢҹеҒ¶еғҸеңЁе’Ңз”ЁжҲ·дәӨдә’ж—¶ пјҢ з”ЁжҲ·иҜҙдәҶи¶…еҮәи®ҫе®ҡзҡ„еҜ№иҜқж—¶ пјҢ иҷҡжӢҹеҒ¶еғҸеҲҷдјҡеҫҲвҖңи®Ёе·§вҖқең°з”ЁдёҖдәӣеӣәе®ҡеә”зӯ”жқҘзіҠеј„иҝҮе…і гҖӮд№ӢеүҚжҲ‘们жҸҗеҲ°дәҶ пјҢ дҝЎжҒҜзҡ„еўһеҠ дјҡеёҰжқҘд»·еҖј пјҢ еҰӮжһңиғҪи®©иҷҡжӢҹеҪўиұЎдә§з”ҹжӣҙеӨҡзҡ„дҝЎжҒҜ пјҢ еҲҷдјҡеҲӣйҖ жӣҙеӨҡзҡ„д»·еҖј гҖӮ д»ҺвҖңй•ңеғҸдҪ“вҖқеҲ°вҖңжҷәиғҪдҪ“вҖқзҡ„иҝҷжқЎеҸ‘еұ•и·Ҝеҫ„ пјҢ жҳҜз”ұдәҺжҠҖжңҜзҡ„зӘҒз ҙжқҘй©ұеҠЁзҡ„ гҖӮ еҰӮжһңдәәе·ҘжҷәиғҪеҸҜд»Ҙи®©з”ЁжҲ·е’ҢиҷҡжӢҹеҪўиұЎзҡ„дәӨдә’еҸҳеҫ—йқһеёёеҠЁжҖҒ пјҢ иҝҷдёӘиҝҮзЁӢд№ҹдёҖе®ҡдјҡиҜһз”ҹйқһеёёеӨҡзҡ„дҝЎжҒҜе’Ңд»·еҖј гҖӮ еҗҢж—¶ пјҢ иҝҷж ·зҡ„еҠЁжҖҒиҷҡжӢҹеҪўиұЎд№ҹжӣҙеҠ еҒҸеҗ‘дәҺвҖңжҷәиғҪдҪ“вҖқ пјҢ д»ҺиҖҢеҸҜд»ҘеңЁиҷҡжӢҹдё–з•ҢдёӯиҝӣиЎҢдё»и§ӮеҶізӯ– гҖӮеңЁиҝҷжқЎеҸ‘еұ•и·Ҝеҫ„дёӯ пјҢ жҜҸдёҖдёӘйҳ¶ж®өзҡ„вҖңжҷәиғҪдҪ“вҖқйғҪдјҡдә§з”ҹдёҚеҗҢйҮҸзә§зҡ„дҝЎжҒҜ пјҢ з»“еҗҲдёҚеҗҢзҡ„дәӨдә’еңәжҷҜ пјҢ иҝӣдёҖжӯҘдә§з”ҹжӣҙеӨҡзҡ„дҝЎжҒҜ гҖӮ3. зңҹе®һдё–з•Ңе’ҢиҷҡжӢҹдё–з•Ңзҡ„з»“еҗҲж–№ејҸ
жҺЁиҚҗйҳ…иҜ»













- зү№жң—жҷ®ж—¶д»Јзҡ„еҪўжҲҗ
- иҒ”йҖҡ2Gе’Ң3Gе°Ҷе…ЁйқўйҖҖзҪ‘пјҢзҪ‘еҸӢпјҡиҖҒдәәжңәе’ӢеҠһпјҹ
- дёӯеӣҪиҪ°иҪ°зғҲзғҲзҡ„з”өе•Ҷж—¶д»Је°ұеҝ«з»“жқҹдәҶгҖӮ
- зҫҺеӣҪеҲ¶еәҰиғҪжңүж•Ҳйў„йҳІеӨ§и§„жЁЎиҲһејҠпјҹйӮЈжҳҜеӨ§жё…ж—¶д»Ј
- зҫҺеӣҪйҖүдёҫд№ұеғҸиғҢеҗҺвҖ”вҖ”дәә们йңҖиҰҒж–°зҡ„йҖүдёҫдҪ“еҲ¶
- жҷ®дё–д»·еҖјеҲ°дәҶжӣҙж–°зҡ„ж—¶еҖҷ
- иҝҷеӣҪз”·дәәиүІиғҶдёҚиЎҢ
- еҗҺз–«жғ…ж—¶д»ЈпјҡжҲ‘们йқ д»Җд№Ҳиө°еҮәе…Ёзҗғз»ҸжөҺеҚұжңә
- зҫҺеӣҪеҠЎеҚҝеҠқиҜҙзҰҒеҚҺдёәпјҢ4家з”өдҝЎе·ЁеӨҙжӢ’з»қпјҡж—¶д»ЈеҸҳдәҶ
- иә«еӨ„вҖңжӮ¬жө®ж—¶д»ЈвҖқпјҢеғҸзӨҫдјҡеӯҰ家дёҖж ·жҖқиҖғ