关于分类数据编码所需了解的所有信息(使用Python代码)( 二 )
这些新创建的二进制特性称为虚拟变量 。 虚拟变量的数量取决于类别变量中的级别 。 这听起来可能很复杂 。
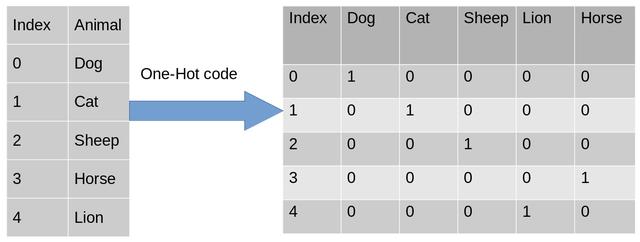
让我们举个例子来更好地理解这一点 。 假设我们有一个动物分类数据集 , 有不同的动物 , 如狗、猫、羊、牛、狮子 。 现在我们必须对这些数据进行独热编码 。
 文章插图
文章插图
编码后 , 在第二个表中 , 我们有一个虚拟变量 , 每个变量代表动物的类别 。 现在 , 对于每个存在的类别 , 我们在该类别的列中都有1 , 其他列为0 。 让我们看看如何在python中实现独热编码 。
import category_encoders as ceimport pandas as pddata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hydrabad','Chennai','Bangalore','Delhi','Hydrabad','Bangalore','Delhi']})#创建用于独热编码的对象encoder=ce.OneHotEncoder(cols='City',handle_unknown='return_nan',return_df=True,use_cat_names=True)# 原始数据data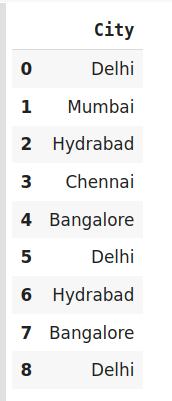 文章插图
文章插图
# 调整和转换数据data_encoded = encoder.fit_transform(data)data_encoded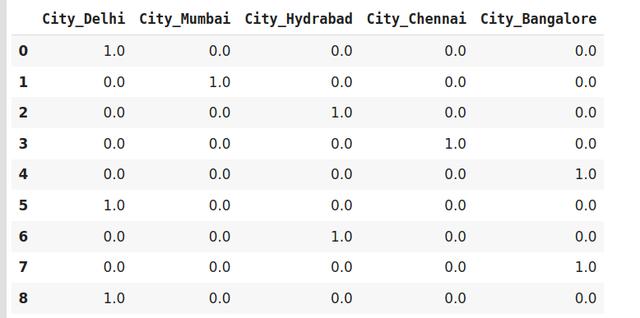 文章插图
文章插图
现在 , 让我们转到另一种非常有趣且广泛使用的编码技术 , 即虚拟编码 。
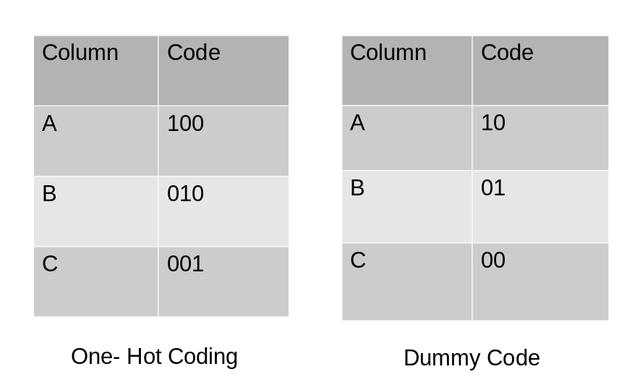
虚拟编码虚拟编码方案类似于独热编码 。 这种分类数据编码方法将分类变量转换为一组二进制变量(也称为虚拟变量) 。 在独热编码的情况下 , 对于变量中的N个类别 , 它使用N个二进制变量 。 虚拟编码是对独热编码的一个小改进 。 虚拟编码使用N-1个特征来表示N个标签/类别 。
为了更好地理解这一点 , 让我们看下面的图片 。 在这里 , 我们使用独热编码和虚拟编码技术对相同的数据进行编码 。 独热编码使用3个变量表示数据 , 而虚拟编码使用2个变量编码3个类别 。
 文章插图
文章插图
让我们在python中实现它 。
import category_encoders as ceimport pandas as pddata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']})# 原始数据data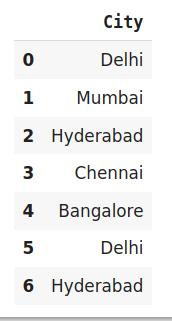 文章插图
文章插图
#编码数据data_encoded=pd.get_dummies(data=http://kandian.youth.cn/index/data,drop_first=True)data_encoded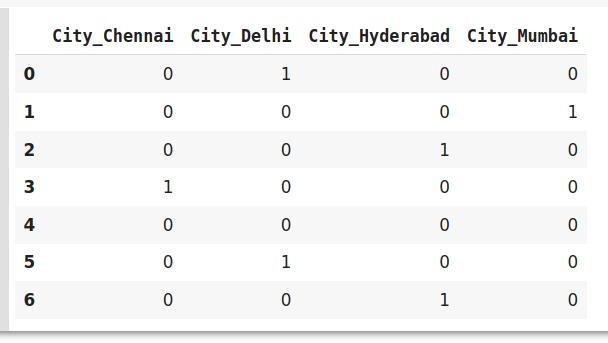 文章插图
文章插图
在这里 , 使用drop_first参数 , 我们使用0表示第一个标签Bangalore 。
独热和虚拟编码的缺点独热编码器和虚拟编码器是两种功能强大且有效的编码方案 。 它们在数据科学家中也很受欢迎 , 但在以下这些情况下可能不那么有效:
- 数据中存在大量级别 。 在这种情况下 , 如果一个特征变量中有多个类别 , 则我们需要相似数量的虚拟变量来对数据进行编码 。 例如 , 具有30个不同值的列将需要30个新变量进行编码 。
- 如果我们在数据集中具有多个分类特征 , 则将发生类似的情况 , 并且我们最终会有几个二进制特征 , 每一个都代表分类特征和它们的多个类别 , 例如一个包含10个或更多分类列的数据集 。
推荐阅读












- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 高下立现!关于核心技术的态度,柳传志和任正非截然不同
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能