关于分类数据编码所需了解的所有信息(使用Python代码)( 三 )
此外 , 它们可能会导致虚拟变量陷阱 。 这是特征高度相关的现象 。 这意味着使用其他变量 , 我们可以轻松预测变量的值 。
由于数据集的大量增加 , 编码使模型的学习变慢 , 并且整体性能下降 , 最终使模型的计算昂贵 。 此外 , 在使用基于树的模型时 , 这些编码不是最佳选择 。
效果编码(Effect Encoding)这种编码技术也称为偏差编码(Deviation Encoding)或求和编码(Sum Encoding) 。 效果编码几乎与虚拟编码类似 , 只是有一点点差异 。 在虚拟编码中 , 我们使用0和1表示数据 , 但在效果编码中 , 我们使用三个值 , 即1,0和-1 。
在虚拟编码中仅包含0的行在效果编码中被编码为-1 。 在虚拟编码示例中 , 索引为4的班加罗尔城市被编码为0000 。 而在效果编码中 , 它是由-1-1-1-1表示的 。
让我们看看我们如何在python中实现它
import category_encoders as ceimport pandas as pddata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']}) encoder=ce.sum_coding.SumEncoder(cols='City',verbose=False,)# 原始数据data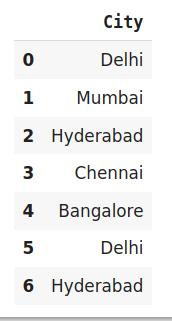 文章插图
文章插图
encoder.fit_transform(data)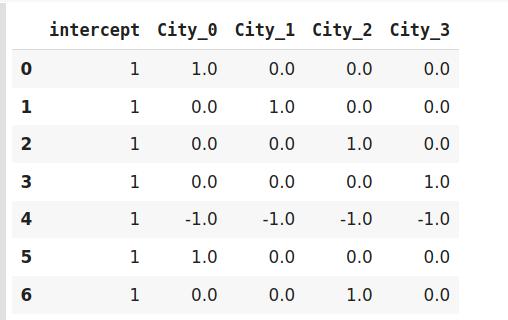 文章插图
文章插图
哈希编码器要理解哈希编码 , 就必须了解哈希 。 哈希是以固定大小值的形式对任意大小的输入进行的转换 。 我们使用哈希算法来执行哈希操作 , 即生成输入的哈希值 。
此外 , 哈希是一个单向过程 , 换句话说 , 不能从哈希表示生成原始输入 。
散列有几个应用 , 如数据检索、检查数据损坏以及数据加密 。 我们有多个哈希函数可用 , 例如消息摘要(MD、MD2、MD5)、安全哈希函数(SHA0、SHA1、SHA2)等等 。
就像独热编码一样 , 哈希编码器使用新的维度来表示分类特性 。 在这里 , 用户可以使用n_component参数来确定转换后的维度数量 。 这就是我的意思——一个有5个类别的特征可以用N个新特征来表示 。 同样 , 一个有100个类别的特征也可以用N个新特征来转换 。 听起来不错吧?
默认情况下 , 哈希编码器使用md5哈希算法 , 但用户可以传递他选择的任何算法 。
import category_encoders as ceimport pandas as pd#Create the dataframedata=http://kandian.youth.cn/index/pd.DataFrame({'Month':['January','April','March','April','Februay','June','July','June','September']})#Create object for hash encoderencoder=ce.HashingEncoder(cols='Month',n_components=6)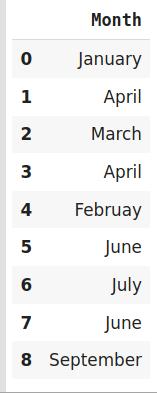 文章插图
文章插图
# 调整和转换数据encoder.fit_transform(data)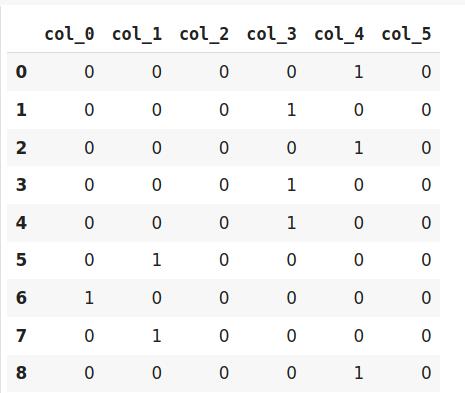 文章插图
文章插图
由于哈希将数据转换为较小的维度 , 因此可能导致信息丢失 。 哈希编码器面临的另一个问题是冲突 。 由于此处将大量特征描绘成较小的尺寸 , 因此可以用相同的哈希值表示多个值 , 这称为冲突 。
此外 , 哈希编码器在某些Kaggle比赛中非常成功 。 最好尝试一下数据集是否具有高基数特征 。
二进制编码二进制编码是哈希编码和独热编码的组合 。 在这种编码方案中 , 首先使用有序编码器将分类特征转换为数值 。 然后将数字转换为二进制数 。 之后 , 该二进制值将拆分为不同的列 。
当类别很多时 , 二进制编码的效果很好 。 例如 , 公司提供产品的国家/地区的城市 。
推荐阅读




![[孙莉]24岁的黄磊为何一眼看中18岁的孙莉,看看孙莉青涩照,难怪黄磊下手这么快!](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/upload/2020/f2e2862a6e6288774657db4b4eb97e5b.jpg)












- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 高下立现!关于核心技术的态度,柳传志和任正非截然不同
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能