关于分类数据编码所需了解的所有信息(使用Python代码)( 四 )
#Import the librariesimport category_encoders as ceimport pandas as pd#Create the Dataframedata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})#Create object for binary encodingencoder= ce.BinaryEncoder(cols=['city'],return_df=True)# 原始数据data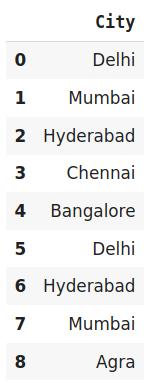 文章插图
文章插图
# 调整和转换数据 data_encoded=encoder.fit_transform(data) data_encoded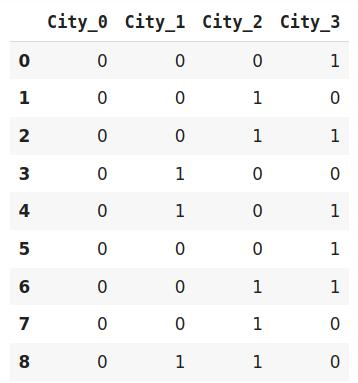 文章插图
文章插图
二进制编码是一种节省内存的编码方案 , 因为它比独热编码使用更少的特性 。 此外 , 它还减少了高基数数据的维数灾难 。
BaseN编码在开始使用BaseN编码之前 , 我们首先尝试了解什么是Base 。
在数字系统中 , “底数”或“基数”是数字的数目或用于表示数字的数字和字母的组合 。 我们一生中最常用的基数是10或十进制 , 因为在这里我们使用10个唯一数字 , 即0到9来代表所有数字 。 另一个广泛使用的系统是二进制 , 即基数为2 。 它使用0和1 , 即2位数字来表示所有数字 。
对于二进制编码 , 基数为2 , 这意味着它将类别的数值转换为其各自的二进制形式 。 如果要更改基本编码方案 , 则可以使用BaseN编码器 。 如果类别更多 , 而二进制编码无法处理维数 , 则可以使用更大的底数 , 例如4或8 。
#Import the librariesimport category_encoders as ceimport pandas as pd#Create the dataframedata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})#Create an object for Base N Encodingencoder= ce.BaseNEncoder(cols=['city'],return_df=True,base=5)# 原始数据data文章插图
# 调整和转换数据data_encoded=encoder.fit_transform(data)data_encoded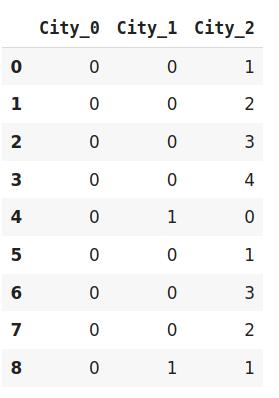 文章插图
文章插图
在上面的例子中 , 我使用了base5 , 也就是所谓的五元体系 。 它类似于二进制编码的例子 。 二进制编码用4个新特性表示相同的数据 , 而BaseN编码只使用3个新变量 。
因此 , BaseN编码技术进一步减少了有效表示数据和提高内存使用率所需的特征数量 。 基数N的默认基数是2 , 这相当于二进制编码 。
目标编码目标编码是一种贝叶斯编码技术 。
贝叶斯编码器使用来自相关/目标变量的信息对分类数据进行编码 。
在目标编码中 , 我们计算每个类别的目标变量的平均值 , 并用平均值替换类别变量 。 在分类目标变量的情况下 , 目标的后验概率代替每个类别 。
#import the librariesimport pandas as pdimport category_encoders as ce#创建数据框data=http://kandian.youth.cn/index/pd.DataFrame({'class':['A,','B','C','B','C','A','A','A'],'Marks':[50,30,70,80,45,97,80,68]})#创建目标编码对象encoder=ce.TargetEncoder(cols='class') # 原始数据Data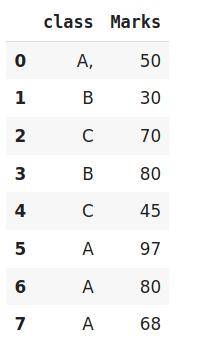 文章插图
文章插图
# 调整并转换数据encoder.fit_transform(data['class'],data['Marks'])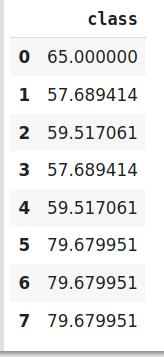 文章插图
文章插图
推荐阅读











![[时尚最美]当众人面“内搭外穿”,这谁顶得住啊,39岁蔡依林是真放的开](https://imgcdn.toutiaoyule.com/20200407/20200407061325055739a_t.jpeg)

![[百科鉴闻]曝光OPPO Ace2 5G超级玩家,Reno Ace大量现货价格狂跌!](http://ttbs.guangsuss.com/image/61beda6375b9eae808fb8d28da8e3d73)






- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 高下立现!关于核心技术的态度,柳传志和任正非截然不同
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能