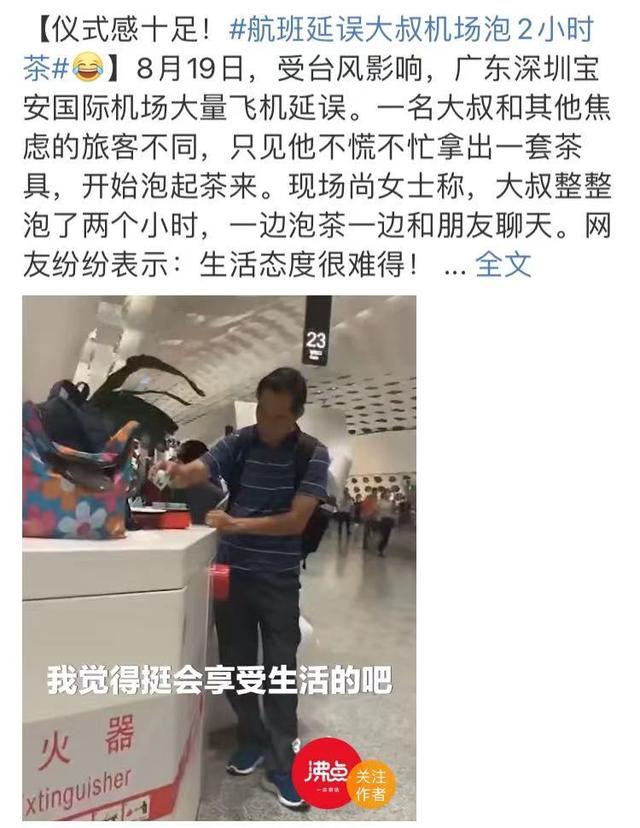
жң¬ж–Үдё»иҰҒд»Ӣз»ҚзҘһз»ҸзҪ‘з»ңдёҮиғҪйҖјиҝ‘зҗҶи®ә пјҢ 并且йҖҡиҝҮPyTorchеұ•зӨәдәҶдёӨдёӘжЎҲдҫӢжқҘиҜҙжҳҺзҘһз»ҸзҪ‘з»ңзҡ„еҮҪж•°йҖјиҝ‘еҠҹиғҪ гҖӮ
еӨ§еӨҡж•°дәәзҗҶи§Ј"еҮҪж•°"дёәй«ҳзӯүд»Јж•°дёӯеҪўеҰӮ"f(x)=2x"зҡ„иЎЁиҫҫејҸ пјҢ дҪҶжҳҜе®һйҷ…дёҠ пјҢ еҮҪж•°еҸӘжҳҜиҫ“е…ҘеҲ°иҫ“еҮәзҡ„жҳ е°„е…ізі» пјҢ е…¶еҪўејҸжҳҜеӨҡж ·зҡ„ гҖӮ

ж–Үз« жҸ’еӣҫ
жӢҝдёӘдәәиЎЈжңҚе°әеҜёйў„жөӢжқҘиҜҙ пјҢ жҲ‘们用жңәеҷЁеӯҰд№ жқҘе®һзҺ°иҝҷдёӘеҠҹиғҪ пјҢ е°ұжҳҜе°ҶдёӘдәәиә«й«ҳгҖҒдҪ“йҮҚгҖҒе№ҙйҫ„дҪңдёәиҫ“е…Ҙ пјҢ е°ҶиЎЈжңҚе°әеҜёдҪңдёәиҫ“еҮә пјҢ е®һзҺ°иҫ“е…Ҙ-иҫ“еҮәжҳ е°„ гҖӮ
е…·дҪ“жқҘиҜҙ пјҢ йңҖиҰҒд»ҘдёӢеҮ дёӘжӯҘйӘӨ:
· 收йӣҶе…ій”®ж•°жҚ®пјҲеӨ§йҮҸдәәеҸЈзҡ„иә«й«ҳ/дҪ“йҮҚ/е№ҙйҫ„ пјҢ е·Із»ҸеҜ№еә”зҡ„е®һйҷ…жңҚиЈ…е°әеҜёпјү гҖӮ
· и®ӯз»ғжЁЎеһӢжқҘе®һзҺ°иҫ“е…Ҙ-иҫ“еҮәзҡ„жҳ е°„йҖјиҝ‘ гҖӮ
· еҜ№жңӘзҹҘж•°жҚ®иҝӣиЎҢйў„жөӢжқҘйӘҢиҜҒжЁЎеһӢ гҖӮ
еҰӮжһңиҫ“еҮәжҳҜиҫ“е…Ҙзү№еҫҒзҡ„зәҝжҖ§жҳ е°„ пјҢ йӮЈд№ҲжЁЎеһӢзҡ„и®ӯз»ғеҫҖеҫҖзӣёеҜ№з®ҖеҚ• пјҢ еҸӘйңҖиҰҒдёҖдёӘзәҝжҖ§еӣһеҪ’е°ұеҸҜд»Ҙе®һзҺ°пјӣsize = a*height + b*weight + c*age + d гҖӮ
дҪҶжҳҜ пјҢ йҖҡеёёеҒҮи®ҫиҫ“еҮәжҳҜиҫ“е…Ҙзү№еҫҒзҡ„зәҝжҖ§жҳ е°„жҳҜдёҚеӨҹеҗҲзҗҶе’ҢдёҚе®Ңе…ЁеҮҶзЎ®зҡ„ гҖӮзҺ°е®һжғ…еҶөеҫҖеҫҖеҫҲеӨҚжқӮ пјҢ еӯҳеңЁдёҖе®ҡзҡ„зү№дҫӢе’ҢдҫӢеӨ– гҖӮеёёи§Ғзҡ„й—®йўҳпјҲеӯ—дҪ“иҜҶеҲ«гҖҒеӣҫеғҸеҲҶзұ»зӯүпјүжҳҫ然ж¶үеҸҠеҲ°еӨҚжқӮзҡ„жЁЎејҸ пјҢ йңҖиҰҒд»Һй«ҳз»ҙиҫ“е…Ҙзү№еҫҒдёӯеӯҰд№ жҳ е°„е…ізі» гҖӮ
дҪҶжҳҜж №жҚ®дёҮиғҪйҖјиҝ‘зҗҶи®ә пјҢ еёҰжңүеҚ•йҡҗи—Ҹзҡ„дәәе·ҘзҘһз»ҸзҪ‘з»ңе°ұиғҪеӨҹйҖјиҝ‘д»»ж„ҸеҮҪж•° пјҢ еӣ жӯӨеҸҜд»Ҙиў«з”ЁдәҺи§ЈеҶіеӨҚжқӮй—®йўҳ гҖӮ
дәәе·ҘзҘһз»ҸзҪ‘з»ңжң¬ж–Үе°ҶеҸӘз ”з©¶е…·жңүиҫ“е…ҘеұӮгҖҒеҚ•дёӘйҡҗи—ҸеұӮе’Ңиҫ“еҮәеұӮзҡ„е®Ңе…ЁиҝһжҺҘзҡ„зҘһз»ҸзҪ‘з»ң гҖӮеңЁжңҚиЈ…е°әеҜёйў„жөӢеҷЁзҡ„дҫӢеӯҗдёӯ пјҢ иҫ“е…ҘеұӮе°ҶжңүдёүдёӘзҘһз»Ҹе…ғпјҲиә«й«ҳгҖҒдҪ“йҮҚе’Ңе№ҙйҫ„пјү пјҢ иҖҢиҫ“еҮәеұӮеҸӘжңүдёҖдёӘпјҲйў„жөӢе°әеҜёпјү гҖӮеңЁиҝҷдёӨиҖ…д№Ӣй—ҙ пјҢ жңүдёҖдёӘйҡҗи—ҸеұӮ пјҢ дёҠйқўжңүдёҖдәӣзҘһз»Ҹе…ғпјҲдёӢеӣҫдёӯжңү5дёӘ пјҢ дҪҶе®һйҷ…дёҠеҸҜиғҪжӣҙеӨ§дёҖдәӣ пјҢ жҜ”еҰӮ1024дёӘпјү гҖӮ

ж–Үз« жҸ’еӣҫ
зҪ‘з»ңдёӯзҡ„жҜҸдёӘиҝһжҺҘйғҪжңүдёҖдәӣеҸҜи°ғж•ҙзҡ„жқғйҮҚ гҖӮи®ӯз»ғж„Ҹе‘ізқҖжүҫеҲ°еҘҪзҡ„жқғйҮҚ пјҢ дҪҝз»ҷе®ҡиҫ“е…ҘйӣҶзҡ„йў„жөӢеӨ§е°ҸдёҺе®һйҷ…еӨ§е°Ҹд№Ӣй—ҙеӯҳеңЁеҫ®е°Ҹе·®ејӮ гҖӮ
жҜҸдёӘзҘһз»Ҹе…ғдёҺдёӢдёҖеұӮзҡ„жҜҸдёӘзҘһз»Ҹе…ғзӣёиҝһ гҖӮиҝҷдәӣиҝһжҺҘйғҪжңүдёҖе®ҡзҡ„жқғйҮҚ гҖӮжҜҸдёӘзҘһз»Ҹе…ғзҡ„еҖјжІҝзқҖжҜҸдёӘиҝһжҺҘдј йҖ’ пјҢ еңЁйӮЈйҮҢе®ғд№ҳд»ҘжқғйҮҚ гҖӮ然еҗҺжүҖжңүзҡ„зҘһз»Ҹе…ғйғҪдјҡеҗ‘еүҚеҸҚйҰҲеҲ°иҫ“еҮәеұӮ пјҢ 然еҗҺиҫ“еҮәдёҖдёӘз»“жһң гҖӮи®ӯз»ғжЁЎеһӢйңҖиҰҒдёәжүҖжңүиҝһжҺҘжүҫеҲ°еҗҲйҖӮзҡ„жқғйҮҚ гҖӮдёҮиғҪйҖјиҝ‘е®ҡзҗҶзҡ„ж ёеҝғдё»еј жҳҜ пјҢ еңЁжңүи¶іеӨҹеӨҡзҡ„йҡҗи—ҸзҘһз»Ҹе…ғзҡ„жғ…еҶөдёӢ пјҢ еӯҳеңЁзқҖдёҖз»„еҸҜд»Ҙиҝ‘дјјд»»дҪ•еҮҪж•°зҡ„иҝһжҺҘжқғеҖј пјҢ еҚідҪҝиҜҘеҮҪж•°дёҚжҳҜеғҸf(x)=x²йӮЈж ·еҸҜд»Ҙз®ҖжҙҒең°еҶҷдёӢжқҘзҡ„еҮҪж•° гҖӮеҚідҪҝжҳҜдёҖдёӘз–ҜзӢӮзҡ„ пјҢ еӨҚжқӮзҡ„еҮҪж•° пјҢ жҜ”еҰӮжҠҠдёҖдёӘ100x100еғҸзҙ зҡ„еӣҫеғҸдҪңдёәиҫ“е…Ҙ пјҢ иҫ“еҮә"зӢ—"жҲ–"зҢ«"зҡ„еҮҪж•°д№ҹиў«иҝҷдёӘе®ҡзҗҶжүҖиҰҶзӣ– гҖӮ
йқһзәҝжҖ§е…ізі»зҘһз»ҸзҪ‘з»ңд№ӢжүҖд»ҘиғҪеӨҹйҖјиҝ‘д»»ж„ҸеҮҪж•° пјҢ е…ій”®еңЁдәҺе°ҶйқһзәҝжҖ§е…ізі»еҮҪж•°ж•ҙеҗҲеҲ°дәҶзҪ‘з»ңдёӯ гҖӮжҜҸеұӮйғҪеҸҜд»Ҙи®ҫзҪ®жҝҖжҙ»еҮҪж•°е®һзҺ°йқһзәҝжҖ§жҳ е°„ пјҢ жҚўиЁҖд№Ӣ пјҢ дәәе·ҘзҘһз»ҸзҪ‘з»ңдёҚеҸӘжҳҜиҝӣиЎҢзәҝжҖ§жҳ е°„и®Ўз®— гҖӮеёёи§Ғзҡ„йқһзәҝжҖ§жҝҖжҙ»еҮҪж•°жңү ReLU, Tanh, Sigmoidзӯү гҖӮ

ж–Үз« жҸ’еӣҫ
ReLUжҳҜдёҖдёӘз®ҖеҚ•зҡ„еҲҶж®өзәҝжҖ§еҮҪж•°-и®Ўз®—ж¶ҲиҖ—е°Ҹ гҖӮеҸҰеӨ–дёӨдёӘйғҪж¶үеҸҠеҲ°жҢҮж•°иҝҗз®— пјҢ еӣ жӯӨи®Ўз®—жҲҗжң¬жӣҙй«ҳ
дёәдәҶеұ•зӨәдәәе·ҘзҘһз»ҸзҪ‘з»ңзҡ„дёҮиғҪйҖјиҝ‘зҡ„иғҪеҠӣ пјҢ жҺҘдёӢжқҘйҖҡиҝҮPyTorchе®һзҺ°дёӨдёӘжЎҲдҫӢ гҖӮ
жЎҲдҫӢдёҖпјҡд»»ж„Ҹж•ЈзӮ№жӣІзәҝжӢҹеҗҲзҘһз»ҸзҪ‘з»ңеҸҜиғҪйқўдёҙзҡ„жңҖеҹәжң¬зҡ„жғ…еҶөд№ӢдёҖе°ұжҳҜеӯҰд№ дёӨдёӘеҸҳйҮҸд№Ӣй—ҙзҡ„жҳ е°„е…ізі» гҖӮдҫӢеҰӮ пјҢ еҒҮи®ҫxеҖјиЎЁзӨәж—¶й—ҙ пјҢ yеқҗж ҮиЎЁзӨәжҹҗжқЎиЎ—йҒ“дёҠзҡ„дәӨйҖҡйҮҸ гҖӮеңЁдёҖеӨ©дёӯзҡ„дёҚеҗҢж—¶й—ҙзӮ№йғҪдјҡеҮәзҺ°й«ҳеі°е’ҢдҪҺи°· пјҢ еӣ жӯӨиҝҷдёҚжҳҜдёҖз§ҚзәҝжҖ§е…ізі» гҖӮ
дёӢйқўзҡ„д»Јз ҒйҰ–е…Ҳз”ҹжҲҗз¬ҰеҗҲжӯЈжҖҒеҲҶеёғзҡ„йҡҸжңәзӮ№ пјҢ 然еҗҺи®ӯз»ғдёҖдёӘзҪ‘з»ң пјҢ иҜҘзҪ‘з»ңе°Ҷxеқҗж ҮдҪңдёәиҫ“е…Ҙ пјҢ yеқҗж ҮдҪңдёәиҫ“еҮә гҖӮжңүе…іжҜҸдёӘжӯҘйӘӨзҡ„иҜҰз»ҶдҝЎжҒҜ пјҢ иҜ·еҸӮи§Ғд»Јз ҒжіЁйҮҠпјҡ
import torchimport plotly.graph_objects as goimport numpy as np# Batch Size, Input Neurons, Hidden Neurons, Output NeuronsN, D_in, H, D_out = 16, 1, 1024, 1# Create random Tensors to hold inputs and outputsx = torch.randn(N, D_in)y = torch.randn(N, D_out)# Use the nn package to define our model# Linear (Input -> Hidden), ReLU (Non-linearity), Linear (Hidden-> Output)model = torch.nn.Sequential(torch.nn.Linear(D_in, H),torch.nn.ReLU(),torch.nn.Linear(H, D_out),)# Define the loss function: Mean Squared Error# The sum of the squares of the differences between prediction and ground truthloss_fn = torch.nn.MSELoss(reduction='sum')# The optimizer does a lot of the work of actually calculating gradients and# Applying backpropagation through the network to update weightslearning_rate = 1e-4optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# Perform 30000 training stepsfor t in range(30000):# Forward pass: compute predicted y by passing x to the model.y_pred = model(x)# Compute loss and print it periodicallyloss = loss_fn(y_pred, y)if t % 100 == 0:print(t, loss.item())# Update the network weights using gradient of the lossoptimizer.zero_grad()loss.backward()optimizer.step()# Draw the original random points as a scatter plotfig = go.Figure()fig.add_trace(go.Scatter(x=x.flatten().numpy(), y=y.flatten().numpy(), mode="markers"))# Generate predictions for evenly spaced x-values between minx and maxxminx = min(list(x.numpy()))maxx = max(list(x.numpy()))c = torch.from_numpy(np.linspace(minx, maxx, num=640)).reshape(-1, 1).float()d = model(c)# Draw the predicted functions as a line graphfig.add_trace(go.Scatter(x=c.flatten().numpy(), y=d.flatten().detach().numpy(), mode="lines"))fig.show()
жҺЁиҚҗйҳ…иҜ»
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- еҲ№иҪҰ|иҪҰдё»жӣқзү№ж–ҜжӢүвҖңиё©еҲ№иҪҰвҖқеүҚиҝӣжҺүжІіпјҒзҪ‘еҸӢпјҡиҪҰе°ҫиҪҰиҙҙе·ІиҜҙжҳҺеҺҹеӣ
- еӨ–жҳҹдәәжҺўзҙў дәәзұ»дёәд»Җд№ҲиҰҒеҜ»жүҫеӨ–жҳҹз”ҹе‘Ҫ
- дёәд»Җд№ҲеҸ«иҮӯе®қ иҮӯе®қжҳҜд»Җд№Ҳж„ҸжҖқиҰҒжҖҺд№Ҳеӣһзӯ”
- йІЁйұјдёҚж–ӯжёёжііжҳҜеӣ дёә йІЁйұјдёәд»Җд№ҲиҰҒдёҚеҒңең°жёёжіі
- Mysqlзҙўеј•дёәд»Җд№ҲдҪҝз”ЁB+ж ‘иҖҢдёҚдҪҝз”Ёи·іиЎЁпјҹ
- й»Һж—Ҹзә№иә«зҡ„иө·еӣ жҳҜд»Җд№Ҳ й»Һж—Ҹдёәд»Җд№ҲиҰҒзә№иә«
- жІіеҢ—иҡ©е°ӨеҸӨеў“ иҡ©е°Өеў“дёәд»Җд№ҲдёҚжҢ–
- дҪ еҗ¬иҜҙдәҶеҗ—пјҹзҰҸйјҺзҷҪиҢ¶жҳҜзі–е°ҝз—…зҡ„е…ӢжҳҹпјҒ[е…»з”ҹиҢ¶]
- жҒ’жҳҹдёәд»Җд№ҲдјҡеқҚеЎҢжҲҗй»‘жҙһ
- жҖҖеӯ•еҗҺеҮәжұ—еӨҡжҖҺд№ҲеӣһдәӢ