算法|用AI削弱跟单不确定性,深挖超兔CRM背后算法
_原题为 用AI削弱跟单不确定性 , 深挖超兔CRM背后算法
信息论创始人克劳德·艾尔伍德·香农提出 , 信息是对不确定性的消除 。 香农开创了用数学描述信息的先河 , 让信息变得可测 。
香农提出的信息熵成为如今机器学习的一大理论基础 。
超兔CRM一直致力于研究用AI打单 , 本质上是用机器学习处理信息 , 通过算法解析数据 , 最终帮助销售削弱跟单过程中的不确定性 。 下面 , 与您分享一下超兔CRM正在使用的算法 。 纯干货!两大主题:1.LSTM 详解;2.传统机器学习与深度学习对比 。
LSTM 详解
1.RNN(循环神经网络):在介绍LSTM之前 , 先介绍RNN
a) 普通神经网络:
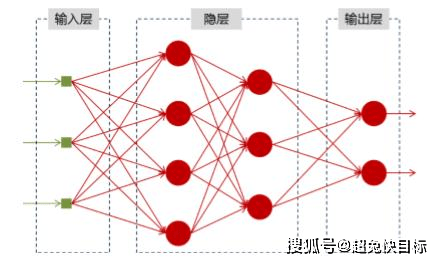
文章图片
图为:神经网络的结构图
神经网络可以当做是能够拟合任意函数的黑盒子 , 只要训练数据足够 , 给定特定的x , 就能得到希望的y 。
举一个情感分析的例子 , 输入一句话 , 判断这句话的的情感是正向的还是负向的 。
其中x就是输入层 , 如上图有3个输入 , 比如为 “我” , “喜欢” , “你” 。 经过隐藏层的计算 , 输出两个值:正向的概率和负向的概率 。 (在XTool中的客户意向 , 会设置三个输出) 。
那么既然普通的神经网络(如上)已经可以完成意向判断的功能 , 为什么还要循环神经网络呢?
他们都只能单独的去处理一个个的输入 , 前一个输入和后一个输入是完全没有关系的 。 但是 , 某些任务需要能够更好的处理序列的信息 , 即前面的输入和后面的输入是有关系的 。
比如 , 当我们在理解一句话意思时 , 孤立的理解这句话的每个词是不够的 , 我们需要处理这些词连接起来的整个序列
所以为了解决一些这样类似的问题 , 能够更好的处理序列的信息 , 就有了RNN:
b) 循环神经网络:
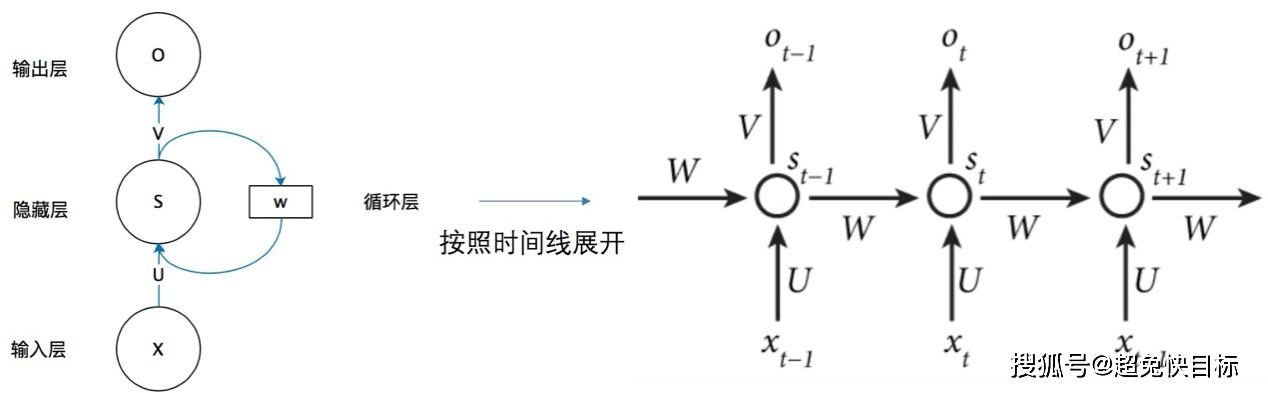
文章图片
图为:循环神经网络结构图
但看上图左边部分可能有点晕 , 右边为左边按序列展开的样式:
还拿上边情感分析为例:

文章图片
以此往后推 。
这样当输入完这句话时 , 最后的结果会把整个句子的信息都带上 。
但是这样还不完美 , 为什么呢?上边的举的例子“我” , “喜欢” , “你”只有三个词 , 但在实际运用中一句话可能会很长 , 几十个词 。
如果把每个词的信息都记录下来 , 数据会很大 , 而且最前边的词对最后边的词的意思可能也没影响 。 还有就是从算法上 , 反向求导时 , 可能会造成梯度消失或梯度爆炸 。
这里简单介绍一下梯度问题:机器学习都是靠梯度来找最优模型的 , 梯度越小 , 模型越好 。
为什么梯度会消失或爆炸呢 , 如果一句话很长 , 系数很小的话(比如0.002) , 一直相乘 , 会越来越接近0 , 最后消失 , 如果系数很大 , 一直相乘结果会越来越大 , 造成梯度爆炸 。
2.LSTM:
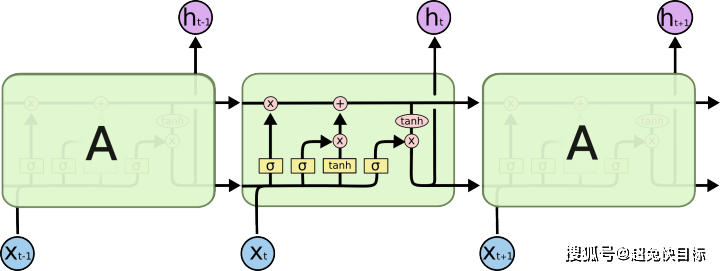
文章图片
图为:长短期记忆网
从上图和RNN对比发现 , 每个隐藏层内又做了许多的运算
1)第1个运算为忘记门:
就是决定什么信息应该被神经元遗忘 。 它会输出 “0”或“1” , “1”表示“完全保留这个” , “0”表示“完全遗忘这个” 。
2)第2个就是输入门
就是决定我们要在神经元细胞中保存什么信息
3)然后就是输出门
决定哪一部分的神经元状态需要被输出
3.LSTM在思想上是与RNN相通的 , 不同之处都在算法上 。
传统机器学习与深度学习对比
一、理论对比:
首先 , 深度学习是机器学习的一种
1. 数据:
a) 随着数据的增加 , 相比机器学习深度学习的性能会越来越好 。
b) 深度学习不需要对数据处理 , 会自动学习提取特征 , 而机器学习需要先对数据进行 格式转化 , 数据清洗 , 压缩纬度等操作 。
2. 规则:
a) 具有特定规则的数据 , 使用机器学习比较好 。 一些简单的场景没必要使用深度学习
3. 硬件
a) 深度学习需要进行大量的矩阵计算 , 对硬件要求比较高 。
4. 执行时间
a) 深度学习训练模型需要的时间较长 。
二、实践对比:
分别使用贝叶斯算法及深度学习算法进行文本分类预测:
图为:神经网络与贝叶斯算法对意向分析对比图
实例1:

文章图片
分析:从结果可以看出 , 不同的数据顺序 , 预测的结果会不同 。
实例2:

推荐阅读














- 教育部|英国高考评分“算法”引全国混乱 教育部高官被免职
- 算法模型|英国高考评分“算法”引全国混乱 教育部高官被免职
- 英国高考评分“算法”引全国混乱 教育部高官被免职
- 开普勒望远镜|新机器学习算法确认50颗系外行星
- 再次|王者荣耀8.26更新:体验服五位英雄调整,重伤装备再次削弱
- 故事传记|人工智能骗人工智能:黑客如何“弄瞎”人脸识别算法?
- 为加快建立现代财政制度提供法治保障——财政部部长刘昆详解新修订的预算法实施条例
- 成绩|英国因疫情取消中高考 利用算法算出成绩引学生不满
- 政府|解读预算法实施条例:防控地方债务风险将更有章法
- 解读预算法实施条例:防控地方债务风险将更有章法