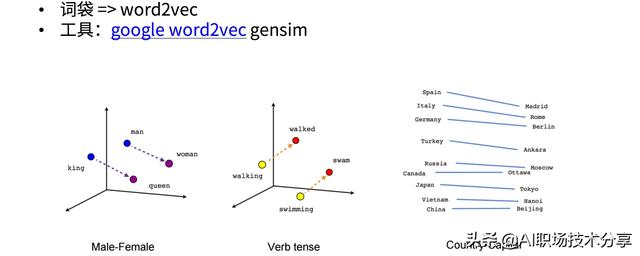
特征工程与模型调优(11)
哈希方案适用于字符串、数字和其它结构(如向量) 。 你可以将哈希输出看作一个有限的 b bins 集合 , 以便于当将哈希函数应用于相同的值\类别时 , 哈希函数能根据哈希值将其分配到 b bins 中的同一个 bin(或者 bins 的子集) 。 我们可以预先定义 b 的值 , 它成为我们使用特征哈希方案编码的每个分类属性的编码特征向量的最终尺寸 。
因此 , 即使我们有一个特征拥有超过 1000 个不同的类别 , 我们设置 b = 10 作为最终的特征向量长度 , 那么最终输出的特征将只有 10 个特征 。 而采用独热编码方案则有 1000 个二进制特征 。 我们来考虑下视频游戏数据集中的「风格(Genre)」属性 。
unique_genres = np.unique(vg_df[['Genre']])print("Total game genres:", len(unique_genres))print(unique_genres)Output\------Total game genres: 12['Action' 'Adventure' 'Fighting' 'Misc' 'Platform' 'Puzzle' 'Racing' 'Role-Playing' 'Shooter' 'Simulation' 'Sports' 'Strategy']我们可以看到 , 总共有 12 中风格的游戏 。 如果我们在“风格”特征中采用独热编码方案 , 则将得到 12 个二进制特征 。 而这次 , 我们将通过 scikit-learn 的 FeatureHasher 类来使用特征哈希方案 , 该类使用了一个有符号的 32 位版本的 Murmurhash3 哈希函数 。 在这种情况下 , 我们将预先定义最终的特征向量大小为 6 。
from sklearn.feature_extraction import FeatureHasherfh = FeatureHasher(n_features=6, input_type='string')hashed_features = fh.fit_transform(vg_df['Genre'])hashed_features = hashed_features.toarray()pd.concat([vg_df[['Name', 'Genre']], pd.DataFrame(hashed_features)], axis=1).iloc[1:7]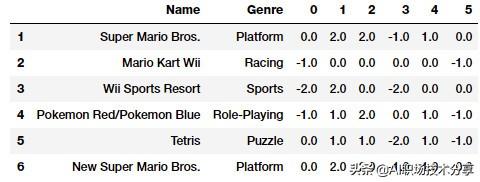 文章插图
文章插图
风格属性的特征哈希
基于上述输出 , 「风格(Genre)」属性已经使用哈希方案编码成 6 个特征而不是 12 个 。 我们还可以看到 , 第 1 行和第 6 行表示相同风格的游戏「平台(Platform)」 , 而它们也被正确编码成了相同的特征向量 。
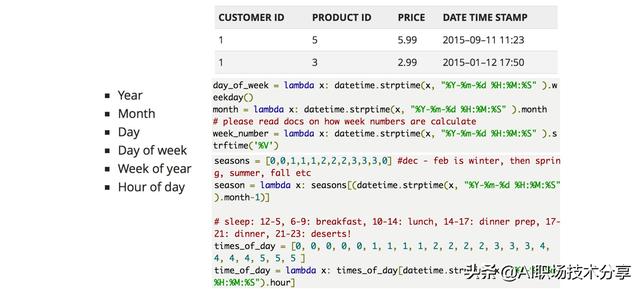
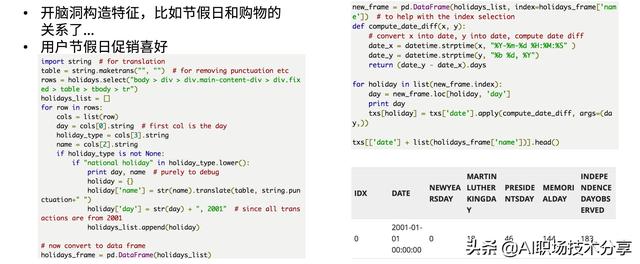
时间型 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
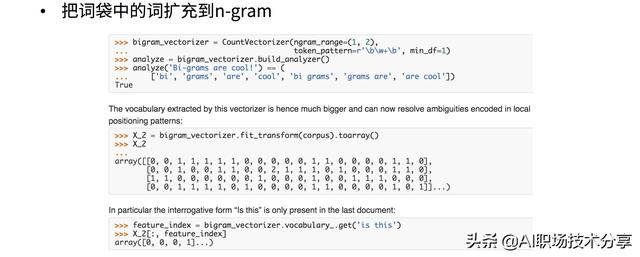
文本型 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
推荐阅读











- 运动计数开发项目的对抗赛:飞算全自动软件工程平台碾压传统模式
- 雷军:2021年的第一件大事,给工程师发百万美金大奖
- 快递员工也能当“教授”?上海快递工程技术高级职称评审实现突破
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 疑似华为P50工程机曝光:正面单挖孔 后置5摄
- 华为P50工程样机真机曝光,小米回应充电器致手机重启问题
- OpenAI推DALL-E模型:能根据文字描述生成图片
- 中国电子信息工程科技发展十四大趋势发布
- 威海高新区2项目获2020年度山东省重点研发计划(重大科技创新工程)立项支持