特征工程与模型调优( 九 )
poke_df[['Name', 'Generation', 'Legendary']].iloc[4:10]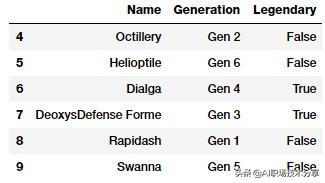 文章插图
文章插图
神奇宝贝数据集子集
这里关注的属性是神奇宝贝的「世代(Generation)」和「传奇(Legendary)」状态 。 第一步是根据之前学到的将这些属性转换为数值表示 。
from sklearn.preprocessing import OneHotEncoder, LabelEncoder\# transform and map pokemon generationsgen_le = LabelEncoder()gen_labels = gen_le.fit_transform(poke_df['Generation'])poke_df['Gen_Label'] = gen_labels\# transform and map pokemon legendary statusleg_le = LabelEncoder()leg_labels = leg_le.fit_transform(poke_df['Legendary'])poke_df['Lgnd_Label'] = leg_labelspoke_df_sub = poke_df[['Name', 'Generation', 'Gen_Label', 'Legendary', 'Lgnd_Label']]poke_df_sub.iloc[4:10]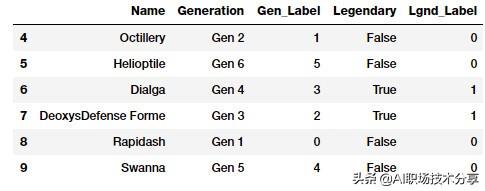 文章插图
文章插图
转换后的标签属性
Gen_Label 和 Lgnd_Label 特征描述了我们分类特征的数值表示 。 现在让我们在这些特征上应用独热编码方案 。
# encode generation labels using one-hot encoding schemegen_ohe = OneHotEncoder()gen_feature_arr = gen_ohe.fit_transform(poke_df[['Gen_Label']]).toarray()gen_feature_labels = list(gen_le.classes_)gen_features = pd.DataFrame(gen_feature_arr, columns=gen_feature_labels)\# encode legendary status labels using one-hot encoding schemeleg_ohe = OneHotEncoder()leg_feature_arr = leg_ohe.fit_transform(poke_df[['Lgnd_Label']]).toarray()leg_feature_labels = ['Legendary_'+str(cls_label) for cls_label in leg_le.classes_]leg_features = pd.DataFrame(leg_feature_arr, columns=leg_feature_labels)通常来说 , 你可以使用 fit_transform 函数将两个特征一起编码(通过将两个特征的二维数组一起传递给函数 , 详情查看文档) 。 但是我们分开编码每个特征 , 这样可以更易于理解 。 除此之外 , 我们还可以创建单独的数据表并相应地标记它们 。 现在让我们链接这些特征表(Feature frames)然后看看最终的结果 。
poke_df_ohe = pd.concat([poke_df_sub, gen_features, leg_features], axis=1)columns = sum([['Name', 'Generation', 'Gen_Label'], gen_feature_labels, ['Legendary', 'Lgnd_Label'], leg_feature_labels], [])poke_df_ohe[columns].iloc[4:10] 文章插图
文章插图
神奇宝贝世代和传奇状态的独热编码特征
此时可以看到已经为「世代(Generation)」生成 6 个虚拟变量或者二进制特征 , 并为「传奇(Legendary)」生成了 2 个特征 。 这些特征数量是这些属性中不同类别的总数 。 某一类别的激活状态通过将对应的虚拟变量置 1 来表示 , 这从上面的数据表中可以非常明显地体现出来 。
考虑你在训练数据上建立了这个编码方案 , 并建立了一些模型 , 现在你有了一些新的数据 , 这些数据必须在预测之前进行如下设计 。
new_poke_df = pd.DataFrame([['PikaZoom', 'Gen 3', True], ['CharMyToast', 'Gen 4', False]], columns=['Name', 'Generation', 'Legendary'])new_poke_df 文章插图
文章插图
新数据
你可以通过调用之前构建的
推荐阅读















- 运动计数开发项目的对抗赛:飞算全自动软件工程平台碾压传统模式
- 雷军:2021年的第一件大事,给工程师发百万美金大奖
- 快递员工也能当“教授”?上海快递工程技术高级职称评审实现突破
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 疑似华为P50工程机曝光:正面单挖孔 后置5摄
- 华为P50工程样机真机曝光,小米回应充电器致手机重启问题
- OpenAI推DALL-E模型:能根据文字描述生成图片
- 中国电子信息工程科技发展十四大趋势发布
- 威海高新区2项目获2020年度山东省重点研发计划(重大科技创新工程)立项支持