特征工程与模型调优( 八 )
因此 , 在 LabelEncoder 类的实例对象 gle 的帮助下生成了一个映射方案 , 成功地将每个风格属性映射到一个数值 。 转换后的标签存储在 genre_labels 中 , 该变量允许我们将其写回数据表中 。
vg_df['GenreLabel'] = genre_labelsvg_df[['Name', 'Platform', 'Year', 'Genre', 'GenreLabel']].iloc[1:7]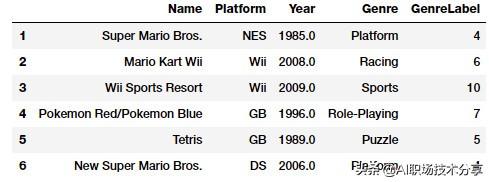 文章插图
文章插图
视频游戏风格及其编码标签
如果你打算将它们用作预测的响应变量 , 那么这些标签通常可以直接用于诸如 sikit-learn 这样的框架 。 但是如前所述 , 我们还需要额外的编码步骤才能将它们用作特征 。
定序属性编码定序属性是一种带有先后顺序概念的分类属性 。 这里我将以本系列文章第一部分所使用的神奇宝贝数据集进行说明 。 让我们先专注于 「世代(Generation)」 属性 。
> poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8')>> poke_df = poke_df.sample(random_state=1, frac=1).reset_index(drop=True)>> np.unique(poke_df['Generation'])>> Output>> \------>> array(['Gen 1', 'Gen 2', 'Gen 3', 'Gen 4', 'Gen 5', 'Gen 6'], dtype=object)根据上面的输出 , 我们可以看到一共有 6 代 , 并且每个神奇宝贝通常属于视频游戏的特定世代(依据发布顺序) , 而且电视系列也遵循了相似的时间线 。 这个属性通常是定序的(需要相关的领域知识才能理解) , 因为属于第一代的大多数神奇宝贝在第二代的视频游戏或者电视节目中也会被更早地引入 。 神奇宝贝的粉丝们可以看下下图 , 然后记住每一代中一些比较受欢迎的神奇宝贝(不同的粉丝可能有不同的看法) 。
 文章插图
文章插图
基于不同类型和世代选出的一些受欢迎的神奇宝贝
因此 , 它们之间存在着先后顺序 。 一般来说 , 没有通用的模块或者函数可以根据这些顺序自动将这些特征转换和映射到数值表示 。 因此 , 我们可以使用自定义的编码\映射方案 。
gen_ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3, 'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6} poke_df['GenerationLabel'] = poke_df['Generation'].map(gen_ord_map)poke_df[['Name', 'Generation', 'GenerationLabel']].iloc[4:10]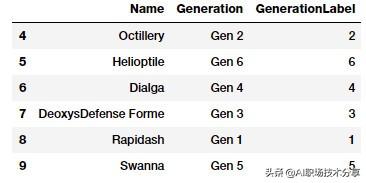 文章插图
文章插图
神奇宝贝世代编码
从上面的代码中可以看出 , 来自 pandas 库的 map(…) 函数在转换这种定序特征的时候非常有用 。
编码分类属性–独热编码方案(One-hot Encoding Scheme)如果你还记得我们之前提到过的内容 , 通常对分类数据进行特征工程就涉及到一个转换过程 , 我们在前一部分描述了一个转换过程 , 还有一个强制编码过程 , 我们应用特定的编码方案为特定的每个类别创建虚拟变量或特征分类属性 。
你可能想知道 , 我们刚刚在上一节说到将类别转换为数字标签 , 为什么现在我们又需要这个?原因很简单 。 考虑到视频游戏风格 , 如果我们直接将 GenereLabel 作为属性特征提供给机器学习模型 , 则模型会认为它是一个连续的数值特征 , 从而认为值 10 (体育)要大于值 6 (赛车) , 然而事实上这种信息是毫无意义的 , 因为体育类型显然并不大于或者小于赛车类型 , 这些不同值或者类别无法直接进行比较 。 因此我们需要另一套编码方案层 , 它要能为每个属性的所有不同类别中的每个唯一值或类别创建虚拟特征 。
考虑到任意具有 m 个标签的分类属性(变换之后)的数字表示 , 独热编码方案将该属性编码或变换成 m 个二进制特征向量(向量中的每一维的值只能为 0 或 1) 。 那么在这个分类特征中每个属性值都被转换成一个 m 维的向量 , 其中只有某一维的值为 1 。 让我们来看看神奇宝贝数据集的一个子集 。
推荐阅读














- 运动计数开发项目的对抗赛:飞算全自动软件工程平台碾压传统模式
- 雷军:2021年的第一件大事,给工程师发百万美金大奖
- 快递员工也能当“教授”?上海快递工程技术高级职称评审实现突破
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 疑似华为P50工程机曝光:正面单挖孔 后置5摄
- 华为P50工程样机真机曝光,小米回应充电器致手机重启问题
- OpenAI推DALL-E模型:能根据文字描述生成图片
- 中国电子信息工程科技发展十四大趋势发布
- 威海高新区2项目获2020年度山东省重点研发计划(重大科技创新工程)立项支持