特征工程与模型调优( 十 )
LabelEncoder 和 OneHotEncoder 对象的 transform() 方法来处理新数据 。 请记得我们的工作流程 , 首先我们要做转换 。
new_gen_labels = gen_le.transform(new_poke_df['Generation'])new_poke_df['Gen_Label'] = new_gen_labelsnew_leg_labels = leg_le.transform(new_poke_df['Legendary'])new_poke_df['Lgnd_Label'] = new_leg_labelsnew_poke_df[['Name', 'Generation', 'Gen_Label', 'Legendary', 'Lgnd_Label']]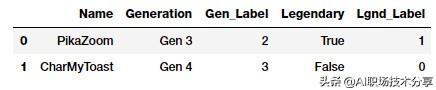 文章插图
文章插图
转换之后的分类属性
在得到了数值标签之后 , 接下来让我们应用编码方案吧!
new_gen_feature_arr = gen_ohe.transform(new_poke_df[['Gen_Label']]).toarray()new_gen_features = pd.DataFrame(new_gen_feature_arr, columns=gen_feature_labels)new_leg_feature_arr = leg_ohe.transform(new_poke_df[['Lgnd_Label']]).toarray()new_leg_features = pd.DataFrame(new_leg_feature_arr, columns=leg_feature_labels)new_poke_ohe = pd.concat([new_poke_df, new_gen_features, new_leg_features], axis=1)columns = sum([['Name', 'Generation', 'Gen_Label'], gen_feature_labels, ['Legendary', 'Lgnd_Label'], leg_feature_labels], [])new_poke_ohe[columns] 文章插图
文章插图
独热编码之后的分类属性
因此 , 通过利用 scikit-learn 强大的 API , 我们可以很容易将编码方案应用于新数据 。
你也可以通过利用来自 pandas 的 to_dummies() 函数轻松应用独热编码方案 。
gen_onehot_features = pd.get_dummies(poke_df['Generation'])pd.concat([poke_df[['Name', 'Generation']], gen_onehot_features], axis=1).iloc[4:10]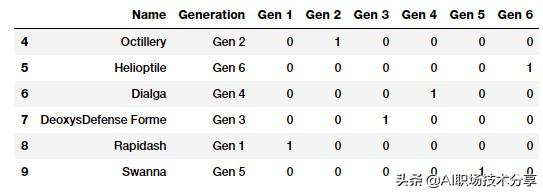 文章插图
文章插图
使用 pandas 实现的独热编码特征
上面的数据表描述了应用在「世代(Generation)」属性上的独热编码方案 , 结果与之前的一致 。
区间计数方案(Bin-counting Scheme)到目前为止 , 我们所讨论的编码方案在分类数据方面效果还不错 , 但是当任意特征的不同类别数量变得很大的时候 , 问题开始出现 。 对于具有 m 个不同标签的任意分类特征这点非常重要 , 你将得到 m 个独立的特征 。 这会很容易地增加特征集的大小 , 从而导致在时间、空间和内存方面出现存储问题或者模型训练问题 。 除此之外 , 我们还必须处理“维度诅咒”问题 , 通常指的是拥有大量的特征 , 却缺乏足够的代表性样本 , 然后模型的性能开始受到影响并导致过拟合 。
 文章插图
文章插图
因此 , 我们需要针对那些可能具有非常多种类别的特征(如 IP 地址) , 研究其它分类数据特征工程方案 。 区间计数方案是处理具有多个类别的分类变量的有效方案 。 在这个方案中 , 我们使用基于概率的统计信息和在建模过程中所要预测的实际目标或者响应值 , 而不是使用实际的标签值进行编码 。 一个简单的例子是 , 基于过去的 IP 地址历史数据和 DDOS 攻击中所使用的历史数据 , 我们可以为任一 IP 地址会被 DDOS 攻击的可能性建立概率模型 。 使用这些信息 , 我们可以对输入特征进行编码 , 该输入特征描述了如果将来出现相同的 IP 地址 , 则引起 DDOS 攻击的概率值是多少 。 这个方案需要历史数据作为先决条件 , 并且要求数据非常详尽 。
特征哈希方案特征哈希方案(Feature Hashing Scheme)是处理大规模分类特征的另一个有用的特征工程方案 。 在该方案中 , 哈希函数通常与预设的编码特征的数量(作为预定义长度向量)一起使用 , 使得特征的哈希值被用作这个预定义向量中的索引 , 并且值也要做相应的更新 。 由于哈希函数将大量的值映射到一个小的有限集合中 , 因此多个不同值可能会创建相同的哈希 , 这一现象称为冲突 。 典型地 , 使用带符号的哈希函数 , 使得从哈希获得的值的符号被用作那些在适当的索引处存储在最终特征向量中的值的符号 。 这样能够确保实现较少的冲突和由于冲突导致的误差累积 。
推荐阅读















- 运动计数开发项目的对抗赛:飞算全自动软件工程平台碾压传统模式
- 雷军:2021年的第一件大事,给工程师发百万美金大奖
- 快递员工也能当“教授”?上海快递工程技术高级职称评审实现突破
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 疑似华为P50工程机曝光:正面单挖孔 后置5摄
- 华为P50工程样机真机曝光,小米回应充电器致手机重启问题
- OpenAI推DALL-E模型:能根据文字描述生成图片
- 中国电子信息工程科技发展十四大趋势发布
- 威海高新区2项目获2020年度山东省重点研发计划(重大科技创新工程)立项支持