PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( еҚҒ )
иҝҷе°ұжҳҜдј з»ҹдёӨйҳ¶ж®өжЁЎејҸдёӯзҡ„第дёҖйҳ¶ж®өгҖӮиҝҷдёӘйҳ¶ж®өдёҚд»…д»…иҝҪжұӮж•ҲжһңеҘҪпјҢд№ҹиҝҪжұӮйўҶеҹҹйҖҡз”ЁжҖ§гҖӮе®ғзҡ„дјҳеҢ–зӣ®ж ҮжҳҜпјҡеңЁе°ҪеҸҜиғҪеӨҡзҡ„дёӢжёёд»»еҠЎеңәжҷҜдёӯпјҢж•ҲжһңйғҪе°ҪеҸҜиғҪеҘҪпјҢдҪҶдёҚеҚ•зӢ¬иҖғиҷ‘жҹҗдёӘзү№ж®ҠйўҶеҹҹзҡ„ж•ҲжһңеҰӮдҪ•гҖӮиҝҷдёӘйҳ¶ж®өпјҢзӣ®еүҚзңӢжҖ»зҡ„еҸ‘еұ•и¶ӢеҠҝжҳҜпјҡеңЁж•°жҚ®иҙЁйҮҸжңүдҝқиҜҒзҡ„еүҚжҸҗдёӢпјҢеўһеҠ ж•°жҚ®ж•°йҮҸпјҢд»ҘеҸҠж•°жҚ®зҡ„еӨҡж ·жҖ§пјҢеҗҢж—¶жҸҗеҚҮжЁЎеһӢеӨҚжқӮеәҰпјҢиҝҷж ·еҸҜд»ҘжҸҗдҫӣжҷ®йҒҚжңүж•Ҳзҡ„жЁЎеһӢеўһејәиғҪеҠӣгҖӮеҫҲжҳҺжҳҫпјҢиҝҷдёӘйҳ¶ж®өпјҢдёҖиҲ¬еҸӘжңүеңҹиұӘе…¬еҸёжүҚиғҪеҒҡеҫ—иө·пјҢиҖҢдё”д»Һи¶ӢеҠҝзңӢпјҢдјҡи¶ҠжқҘи¶ҠеҰӮжӯӨгҖӮе°ҶжқҘзҡ„еҸ‘еұ•жЁЎејҸеҸҜиғҪжҳҜпјҢи¶…зә§еңҹиұӘе…¬еҸёдёҚж–ӯдјҳеҢ–иҝҷдёӘжЁЎеһӢпјҢ然еҗҺж”ҫеҮәжқҘдҫӣеӨ§е®¶з”ЁпјҢжңүиғҪеҠӣеҒҡиҝҷдёӘдәӢжғ…зҡ„дәәпјҢеә”иҜҘдјҡи¶ҠжқҘи¶Ҡе°‘гҖӮ
第дәҢдёӘйҳ¶ж®өпјҡйўҶеҹҹйў„и®ӯз»ғ
еңЁз¬¬дёҖйҳ¶ж®өи®ӯз»ғеҘҪзҡ„йҖҡз”Ёйў„и®ӯз»ғжЁЎеһӢеҹәзЎҖдёҠпјҢеҲ©з”ЁдёҚеҗҢйўҶеҹҹзҡ„иҮӘз”ұж–Үжң¬пјҢжһ„е»әеӨҡдёӘгҖҒдёҚеҗҢйўҶеҹҹзҡ„йўҶеҹҹйў„и®ӯз»ғжЁЎеһӢгҖӮжҜ”еҰӮжҲ‘们еҸҜд»ҘеҲҶеҲ«ж”¶йӣҶи®Ўз®—жңәйўҶеҹҹгҖҒз”ҹзү©йўҶеҹҹгҖҒз”өе•ҶйўҶеҹҹвҖҰ зӯүзӯүпјҢеӨҡдёӘдёҚеҗҢйўҶеҹҹзҡ„ж— ж ҮжіЁиҮӘз”ұж–Үжң¬ж•°жҚ®гҖӮеңЁз¬¬дёҖйҳ¶ж®өйҖҡз”ЁжЁЎеһӢеҹәзЎҖдёҠпјҢеҲҶеҲ«з”Ёеҗ„дёӘйўҶеҹҹж•°жҚ®пјҢеҶҚеҲҶеҲ«еҒҡдёҖж¬Ўйў„и®ӯз»ғпјҢиҝҷж ·жҲ‘们е°ұеҫ—еҲ°дәҶйҖӮеҗҲи§ЈеҶіеҗ„дёӘдёҚеҗҢйўҶеҹҹзҡ„йў„и®ӯз»ғжЁЎеһӢпјҡи®Ўз®—жңәйўҶеҹҹгҖҒз”ҹзү©йўҶеҹҹгҖҒз”өе•ҶйўҶеҹҹвҖҰ.. зӯүзӯүеӨҡдёӘдёҚеҗҢзҡ„йў„и®ӯз»ғжЁЎеһӢгҖӮдёӢжёёд»»еҠЎеҸҜд»Ҙж №жҚ®иҮӘе·ұд»»еҠЎзҡ„йўҶеҹҹпјҢйҖүжӢ©йҖӮй…ҚжҖ§еҘҪзҡ„йўҶеҹҹйў„и®ӯз»ғжЁЎеһӢжқҘдҪҝз”ЁгҖӮ
иҝҷдёӘйҳ¶ж®өзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢеңЁи®ӯз»ғзҡ„ж—¶еҖҷпјҢжңүдёӘзӢ¬зү№зҡ„й—®йўҳйңҖиҰҒи§ЈеҶіпјҡзҒҫйҡҫйҒ—еҝҳй—®йўҳгҖӮжүҖи°“"зҒҫйҡҫйҒ—еҝҳ"пјҢе°ұжҳҜиҜҙпјҢеҪ“дҪ з”ЁйўҶеҹҹж•°жҚ®иҝӣиЎҢйў„и®ӯз»ғзҡ„ж—¶еҖҷпјҢеӣ дёәдјҡи°ғж•ҙ第дёҖйҳ¶ж®өйў„и®ӯз»ғжЁЎеһӢзҡ„еҸӮж•°пјҢиҝҷз§ҚеҒҸеҗ‘йўҶеҹҹжҖ§зҡ„еҸӮж•°и°ғж•ҙпјҢеҸҜиғҪдјҡеҜјиҮҙ第дёҖйҳ¶ж®өжЁЎеһӢеӯҰеҘҪзҡ„еҸӮж•°иў«ж”№еҶҷпјҢиҝҷж„Ҹе‘ізқҖпјҡз»ҸиҝҮ第дәҢйҳ¶ж®өйў„и®ӯз»ғпјҢ第дёҖйҳ¶ж®өйў„и®ӯз»ғжЁЎеһӢйҮҢеӯҰдјҡзҡ„еҫҲеӨҡйҖҡз”ЁиҜӯиЁҖзҹҘиҜҶпјҢеҸҜиғҪдјҡиў«еҶІжҺүгҖӮзҒҫйҡҫйҒ—еҝҳе°ұжҳҜиҝҷдёӘж„ҸжҖқгҖӮзҒҫйҡҫйҒ—еҝҳй—®йўҳпјҢеҜ№дәҺйў„и®ӯз»ғжЁЎеһӢпјҢе°Өе…¶жҳҜйўҶеҹҹйў„и®ӯз»ғжЁЎеһӢжқҘиҜҙпјҢжҳҜдёӘеҫҲе…ій”®д№ҹеҫҲйҮҚиҰҒзҡ„й—®йўҳпјҢзӣ®еүҚд№ҹжңүдёҖдәӣи§ЈеҶіж–№жЎҲпјҢйҷҗдәҺзҜҮе№…пјҢиҝҷйҮҢе°ұдёҚеұ•ејҖдәҶгҖӮ
иҝҷдёӘйҳ¶ж®өзҡ„йў„и®ӯз»ғпјҢеӣ дёәж•°жҚ®йҮҸзӣёжҜ”第дёҖйҳ¶ж®өдјҡе°ҸеҫҲеӨҡпјҢжүҖд»Ҙе…¶е®һдёӯеҶңе…¬еҸёз”ҡиҮіиҙ«еҶңе…¬еҸёд№ҹиғҪеҒҡеҫ—иө·пјҢдёҚеӯҳеңЁеңҹиұӘй—Ёж§ӣпјҢеӨ§е®¶еә”иҜҘйғҪиғҪеҒҡгҖӮеҪ“然пјҢдёҖиҲ¬жҲ‘们еҸӘеҒҡи·ҹиҮӘе·ұжүӢеӨҙд»»еҠЎзӣёе…ізҡ„йўҶеҹҹзҡ„йў„и®ӯз»ғжЁЎеһӢгҖӮеҰӮжһңдҪ жғіеҒҡеҫҲеӨҡйўҶеҹҹзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢйӮЈдј°и®Ўд№ҹиҰҒеӨҮ足银иЎҢеҚЎгҖӮдј°и®ЎеҗҺз»ӯд№ҹдјҡжңүеңҹиұӘе…¬еҸёеҒҡеҘҪеҫҲеӨҡдёҚеҗҢйўҶеҹҹзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢдҫӣеӨ§е®¶дёӘжҖ§еҢ–йҖӮй…ҚдҪҝз”ЁпјҢиҷҪиҜҙзӣ®еүҚиҝҳжІЎжңүпјҢдҪҶжҳҜжҺЁж–ӯиө·жқҘпјҢиҝҷжҳҜдёӘеӨ§жҰӮзҺҮдјҡеҸ‘з”ҹзҡ„дәӢ件гҖӮ
第дёүдёӘйҳ¶ж®өпјҡд»»еҠЎйў„и®ӯз»ғ
еңЁеүҚдёӨдёӘйў„и®ӯз»ғжЁЎеһӢеҹәзЎҖдёҠпјҢжҜ”еҰӮд»Һ第дәҢдёӘйҳ¶ж®өйҮҢйқўзҡ„еӨҡдёӘдёҚеҗҢзҡ„йўҶеҹҹйў„и®ӯз»ғжЁЎеһӢдёӯпјҢйҖүжӢ©е’ҢжүӢеӨҙд»»еҠЎйҖӮй…Қзҡ„йӮЈдёӘйўҶеҹҹйў„и®ӯз»ғжЁЎеһӢпјҢеңЁиҝҷдёӘжЁЎеһӢеҹәзЎҖдёҠпјҢз”ЁжүӢеӨҙж•°жҚ®пјҢжҠӣжҺүж•°жҚ®ж ҮзӯҫпјҢеҶҚеҒҡдёҖж¬Ўйў„и®ӯз»ғпјҢж— и®әжүӢдёҠд»»еҠЎж•°жҚ®жңүеӨҡе°‘гҖӮжҜ”еҰӮжүӢдёҠд»»еҠЎжҳҜи®Ўз®—жңәйўҶеҹҹзҡ„пјҢйӮЈд№Ҳд»Һ第дәҢйҳ¶ж®өзҡ„еӨҡдёӘйўҶеҹҹжЁЎеһӢйҮҢйқўпјҢйҖүжӢ©и®Ўз®—жңәйўҶеҹҹйҖӮй…ҚиҝҮзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢеңЁиҝҷдёӘжЁЎеһӢеҹәзЎҖдёҠиҝӣиЎҢдёҖж¬Ўд»»еҠЎзә§еҲ«зҡ„йў„и®ӯз»ғгҖӮиҝҷж ·еә”иҜҘиғҪжҳҺжҳҫжҸҗеҚҮд»»еҠЎж•ҲжһңгҖӮ
第еӣӣйҳ¶ж®өпјҡд»»еҠЎ Fine-tuning
иҝҷжҳҜдј з»ҹдёӨйҳ¶ж®өзҡ„第дәҢйҳ¶ж®өпјҢеҒҡжі•дёҖж ·пјҢжІЎд»Җд№ҲеҘҪи®Ізҡ„гҖӮ
еҪ“然пјҢеҰӮжһңдҪ жүӢдёҠзҡ„д»»еҠЎжІЎжңүйӮЈд№Ҳејәзҡ„йўҶеҹҹжҖ§пјҢеҸҜд»Ҙи·іиҝҮ第дәҢйҳ¶ж®өпјҢд№ҹе°ұжҳҜйӮЈдёӘйўҶеҹҹйў„и®ӯз»ғжЁЎеһӢйҳ¶ж®өпјҢиө°еү©дҪҷзҡ„дёүйҳ¶ж®өжЁЎејҸеҚіеҸҜпјҢж— и®әеҰӮдҪ•пјҢд»»еҠЎйў„и®ӯз»ғйғҪжҳҜеҖјеҫ—еҒҡзҡ„дёҖдёӘдәӢжғ…гҖӮ
иҒҡжІҷжҲҗеЎ”пјҡеҰӮдҪ•е»әйҖ ејәеӨ§зҡ„йў„и®ӯз»ғжЁЎеһӢ
дёҠж–Үд»ҺдёҚеҗҢи§’еәҰжҲ–з»ҙеәҰпјҢжҖ»з»“дәҶйў„и®ӯз»ғжЁЎеһӢжҹҗдёӘж–№йқўзҡ„дёҖдәӣз»“и®әпјҢжҲ‘们综еҗҲиө·жқҘзңӢдёҖдёӢгҖӮдёҚи®әеҮәдәҺд»Җд№Ҳзӣ®зҡ„пјҢжү“жҰңд№ҹеҘҪпјҢжҠҠжүӢеӨҙеә”з”ЁеҒҡеҫ—жӣҙеҮәиүІд№ҹеҘҪпјҢеҰӮжһңжҲ‘们综еҗҲеҗ„дёӘз»ҙеәҰзҡ„зҺ°жңүдҝЎжҒҜпјҢйӮЈд№ҲпјҢеңЁеҪ“еүҚжҠҖжңҜж°ҙеҮҶдёӢпјҢеҰӮдҪ•жһ„йҖ ејәеӨ§зҡ„йў„и®ӯз»ғжЁЎеһӢпјҢиІҢдјјжҳҜеҸҜд»Ҙеҫ—еҮәзӣёеҜ№жҳҺжҷ°з»“и®әзҡ„гҖӮеӣ дёә NLP йҮҢйқўж—ўжңүиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎпјҢд№ҹжңүиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎпјҢдёӨиҖ…е·®ејӮиҫғеӨ§пјҢжүҖд»ҘжҲ‘们еҲҶеӨҙжқҘзңӢгҖӮ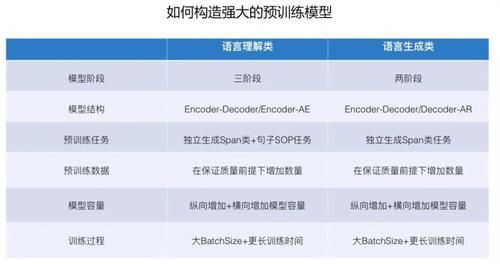
ж–Үз« еӣҫзүҮ
еҜ№дәҺиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎпјҢжҲ‘еҒҮи®ҫдҪ зҡ„д»»еҠЎдёҚжҳҜйўҶеҹҹжҖ§зү№еҲ«ејәйӮЈз§Қзұ»еһӢзҡ„пјҢе»әи®®йҮҮеҸ–еҰӮдёӢжҠҖжңҜж–№жЎҲпјҡдҪҝз”Ёдёүйҳ¶ж®өжЁЎеһӢпјҡйҖҡз”Ёйў„и®ӯз»ғ + д»»еҠЎйў„и®ӯз»ғ + д»»еҠЎ Fine-tuningгҖӮеңЁеҒҡе®Ң第дёҖйҳ¶ж®өйў„и®ӯз»ғеҗҺпјҢз”ЁжүӢеӨҙд»»еҠЎж•°жҚ®пјҢжҠӣжҺүж ҮзӯҫпјҢеҶҚеҒҡдёҖж¬Ўд»»еҠЎйў„и®ӯз»ғпјҢ然еҗҺд»»еҠЎ Fine-tuningгҖӮ
жЁЎеһӢз»“жһ„е»әи®®йҮҮеҸ– Encoder+Decoder з»“жһ„пјҢжҲ–иҖ… Encoder-AE з»“жһ„пјӣйў„и®ӯз»ғд»»еҠЎй…ҚзҪ®дёӨдёӘпјҡзӢ¬з«Ӣз”ҹжҲҗ Span зұ»иҜӯиЁҖжЁЎеһӢеҸҠ SOP еҸҘеӯҗд»»еҠЎпјӣеңЁиҙЁйҮҸдјҳе…Ҳзҡ„еүҚжҸҗдёӢпјҢеўһеҠ йў„и®ӯз»ғж•°жҚ®зҡ„ж•°йҮҸпјӣжҜ”иҫғе…ій”®зҡ„дёҖзӮ№жҳҜпјҢдёҖе®ҡиҰҒеўһеҠ жЁЎеһӢе®№йҮҸпјҡеҸҜд»Ҙзәөеҗ‘еўһеҠ Transformer Block еұӮж·ұпјҢжҲ–иҖ…жЁӘеҗ‘и°ғеӨ§ Transformer зӣёеә”дҪҚзҪ®еҸҜй…ҚзҪ®еҸӮж•°еӨ§е°ҸгҖӮеҪ“然пјҢеҰӮжһңдҪ дёҚе·®й’ұпјҢдёӨдёӘеҸҜд»ҘдёҖиө·дёҠгҖӮеҸҰеӨ–пјҢиҰҒдҪҝеҫ—жЁЎеһӢеҫ—еҲ°е……еҲҶи®ӯз»ғпјҢе°ұжҳҜиҜҙеўһеӨ§и®ӯз»ғиҝҮзЁӢдёӯзҡ„ Batch Size е’Ңи®ӯз»ғжӯҘй•ҝгҖӮ
еҜ№дәҺиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎпјҢе»әи®®йҮҮеҸ–еҰӮдёӢжҠҖжңҜж–№жЎҲпјҡ
дҪҝз”ЁдёӨйҳ¶ж®өжЁЎеһӢпјҡйҖҡз”Ёйў„и®ӯз»ғ + д»»еҠЎ Fine-tuningгҖӮжЁЎеһӢз»“жһ„е»әи®®йҮҮеҸ– Encoder+Decoder з»“жһ„пјҢжҲ–иҖ… Decoder-AR з»“жһ„пјӣйў„и®ӯз»ғд»»еҠЎйҮҮз”ЁзӢ¬з«Ӣз”ҹжҲҗ Span зұ»иҜӯиЁҖжЁЎеһӢпјӣеңЁиҙЁйҮҸдјҳе…Ҳзҡ„еүҚжҸҗдёӢпјҢеўһеҠ йў„и®ӯз»ғж•°жҚ®зҡ„ж•°йҮҸпјӣеҗҢж ·пјҢжҜ”иҫғе…ій”®зҡ„дёҖзӮ№жҳҜпјҢдёҖе®ҡиҰҒеўһеҠ жЁЎеһӢе®№йҮҸпјҡеҸҜд»Ҙзәөеҗ‘еўһеҠ Transformer Block еұӮж·ұпјҢжҲ–иҖ…жЁӘеҗ‘и°ғеӨ§ Transformer зӣёеә”дҪҚзҪ®еҸҜй…ҚзҪ®еҸӮж•°еӨ§е°ҸгҖӮеҪ“然пјҢеҰӮжһңдҪ дёҚе·®й’ұпјҢдёӨдёӘеҸҜд»ҘдёҖиө·дёҠгҖӮеҸҰеӨ–пјҢд№ҹиҰҒдҪҝеҫ—жЁЎеһӢеҫ—еҲ°е……еҲҶи®ӯз»ғпјҢе°ұжҳҜиҜҙеўһеӨ§и®ӯз»ғиҝҮзЁӢдёӯзҡ„ Batch Size е’Ңи®ӯз»ғжӯҘй•ҝгҖӮ
зӣёдҝЎйҮҮеҸ–дёҠиҝ°жҠҖжңҜж–№жЎҲпјҢдҪ иғҪеңЁжү“жҰңиҝҮзЁӢдёӯиҺ·еҫ—еҫҲеҘҪзҡ„еҗҚж¬ЎпјҢжҲ–иҖ…еңЁе®һйҷ…е·ҘдҪңдёӯиғҪжҜ”иҫғеҝ«ең°е®ҢжҲҗиҮӘе·ұзҡ„ KPI жҲ– OKRгҖӮеҪ“然пјҢеҰӮжһңжҳҜиө°иҗҪең°еә”з”Ёзҡ„и·ҜеӯҗпјҢе…ідәҺзҹҘиҜҶи’ёйҰҸзӯүдёҖзі»еҲ—еҰӮдҪ•е°ҶжЁЎеһӢеҒҡе°Ҹиҝҷж–№йқўпјҢи®°еҫ—иҰҒеӨҡиҠұзӮ№еҠҹеӨ«гҖӮ
жҺЁиҚҗйҳ…иҜ»


















- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ