PTM|乘风破浪的 PTM,深度解读预训练模型的进展( 九 )

文章图片
经过多模态预训练之后,是否模型能够建立起不同模态信息之间的语义映射关系呢?答案可以参考上图:经过预训练后,输入一句话以及对应的图片进入模型,对于文本中的某个单词,我们可以观察这个单词与图片中哪块区域联系密切(根据 Attention 强度信息可以看出)。从上图示例可以看出,预训练模型确实学会了不同模态单词语义之间的映射关系。多模态模型经过预训练之后,针对具体的应用任务,可以采取第二阶段 Fine-tuning 的模式增强应用效果。从上述描述可见,单流模型结构相对简单,模型参数也相对少些,而且能够在模型底层及早对不同模态之间的语义直接建立联系,所以看起来比双流模式更有发展前景,但是从目前的各种研究对比实验结果看,貌似两种方法的效果在伯仲之间。不过,可以得出的结论是,采用预训练模型的多模态方法,比不用预训练的传统方法,在应用效果上是有明显提升的。
目前来看,如果希望多模态预训练有更快速的技术发展,以下几个方面是需要重点关注的:
首先,也是最重要的,可能是急需构建不同模态间的大规模对齐数据。目前,"图片 - 文本"类型的对齐数据规模尚可,但是继续扩大数据规模无疑是有益的;对其它类型的模态组合而言,大规模的标准对齐数据比较缺乏,这会严重制约多模态预训练的发展。所以明显需要数据先行,这是发展技术的前提条件;
其次,感觉在自由文本预训练研究领域中,目前得到的一些得到验证的经验,推理起来,应该是能够直接迁移到多模态预训练领域的。典型的经验,比如:在扩大数据规模的同时,增加模型复杂度。增加模型复杂度包括图片特征抽取器模型复杂度(已经有实验验证加深 ResNet 模型对效果提升明显),以及增加对应的 Transformer 层深,放大 Transformer 的 Hidden Size 等,相信这是能够大幅提升多模态预训练的首选手段;再比如文本预训练任务中的 Mask 对象,采用 Span 方式而非单词方式(已有工作这么做了),加大 Batch Size 延长训练时间等训练方法优化手段,想来都应该是有益的;从训练目标来说,目前的模态间对齐任务还是有点类似 NSP 这种句子分类任务,明显偏简单了一些,这块可以考虑引入更有难度的对齐任务,以及实体级别细粒度的对齐任务,来增强模态对齐模型的效果。
再次,可以考虑由目前的两模态向真正的多模态扩展,比如三模态动态联合训练,目前常见的是 "文本 - 图片",或者"文本 - 视频",通常是两模态结构,后面可以考虑"文本 - 图片 - 音频",或者"文本 - 视频 - 音频" 等三模态甚至更多模态的联合预训练。当然,这么做的前提,仍然是得先有多模态的对齐数据。
多多益善:从两阶段模型到四阶段模型
经典的预训练模型框架下,一般我们解决 NLP 问题有两个阶段:第一阶段是模型预训练阶段,预训练模型从文本等信息中学习语言知识;第二阶段是 Fine-tuning 阶段,根据手上的有监督数据,对模型参数进行微调,以获得更好的任务效果。
前文有述,预训练阶段的最明显发展趋势是大数据 + 大模型,在数据质量有保障的前提下,数据量越大,模型容量越大,预训练阶段学到的语言知识效果越好。其实,关于预训练数据,目前还有很多研究,能够得出另外一个结论:从领域、题材、类型等不同角度看,如果预训练数据和手上任务数据越接近,则预训练模型带来的收益就越大。
很多时候,我们手头上的任务数据有很强的领域性,比如可能是计算机领域的,因为预训练数据一般具备通用性,即使大量预训练文本里包含部分计算机类的文本,整体占比也很小。于是,这种情况下,由于领域差异比较大,预训练模型带给手头任务的收益,就没期望中那么大。一种直观的,也是不少人在用的解决方案是:把领域性文本,也加入到预训练数据中,一同参与预训练过程,这样能够增加预训练文本和手上任务的相似性,就能提升任务效果。事实上,这样做也确实能解决这个问题。但是,有一个问题:预训练阶段往往会兼顾模型的通用性,尽可能兼顾各种下游任务,希望模型能在不同领域都有效。而且,从趋势看,数据规模和模型规模会越来越大,也就是训练成本会越来越高。所以,这种把领域数据添加到预训练数据一起训练的做法,一则影响模型通用性,二则实现成本高,看上去就不是特别好的方法。
目前看,要解决这个问题,比较好的方法是把两个阶段分离:第一阶段仍然采取大数据、大模型,走通用普适、各种任务都能受益的路子,不特意考虑领域特点,因为兼顾不过来;第二阶段,在第一阶段训练好的通用预训练模型基础上,利用领域数据,再做一次预训练,等于把通用的预训练模型往领域方向拉动一下。这样两个阶段各司其职,有独立的优化目标,也能兼顾通用性和领域适配性。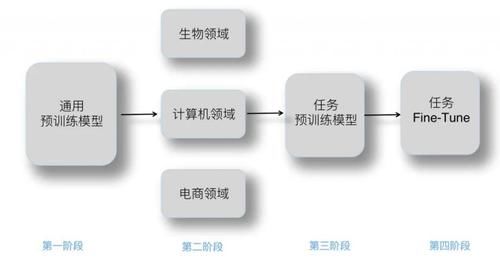
文章图片
上面这个方法,我猜应该不少人都已经在这么做了,论文 "Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks" 也通过大量实验验证了领域数据预训练(DAPT)的有效性,再结合它得出的另外一个重要结论:用手上的任务数据,无论大小,如果做一次任务级数据预训练(TAPT),也就是拿着手上任务数据,在通用预训练模型基础上,再做一次预训练,也能够有效提升任务效果。综合这个文章和其它有关文章的结论,我们不难看出,要想更好地提升任务效果,我们应该从传统的两阶段模型,拓展到如下四阶段模型(参考上图):第一个阶段:通用预训练
推荐阅读








![[献血]一腔热血献战“疫”!一五七医院百名医务人员献血](https://pic.nfapp.southcn.com/nfplus/ossfs/pic/xy/202003/01/9be8b43769df49fc8633a2d28e383f6b_zsize_b)





- 队友|沈梦辰曝光队友“丑照”,但显示出良好的人气
- 公演|《乘风破浪的姐姐》,第五次公演现场,李斯丹妮组《情人》太惊艳
- 缺位|《乘风破浪的姐姐》,青春从来不缺位,也不让位,而是自信归位
- 时尚狂想曲|《乘风破浪的姐姐》录制团综,张雨绮站C位,简约衬衣罕见秀知性
- 归位|《乘风破浪的姐姐》,青春从来不缺位,也不让位,而是自信归位
- 10月|印度发生5.1级地震,震源深度40千米
- 陈赫|《乘风破浪的姐姐》成团夜请了17位男嘉宾,陈赫惹来一片争议
- 节目组|孟佳,别挣扎了,《乘风破浪》节目组明摆着想把你淘汰
- 宁静|《乘风破浪的姐姐》录团综,宁静万茜破不和传闻,路演视频欢乐多
- 消息资讯|乘风破浪 | 变革转型:人才培养——企业转型与创新的核心驱动力