PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( дә” )
иҝҷж ·пјҢжҲ‘зӯӣеҮәдәҶдёҖжү№иЎЁзҺ°дјҳз§Җзҡ„жЁЎеһӢпјҢеҢ…жӢ¬пјҡRoBERTaпјҢGoogle T5пјҢALBERTпјҢELECTRAпјҢXLNetпјҢGPT3пјҢBARTпјҢUNILM v2, StructBertпјҢMacBertгҖӮиҝҷдәӣжЁЎеһӢиҰҒд№ҲеңЁжҹҗдёӘжҰңеҚ•еүҚеҮ еҗҚпјҢиҰҒд№Ҳи®әж–Үе®һйӘҢз»“жһңжҳҫзӨәж•ҲжһңйқһеёёеҘҪпјҢдәҢиҖ…еҚ е…¶дёҖгҖӮиҝҷйҮҢйқўпјҢGPT3 жҳҜдёӘзәҜз”ҹжҲҗжЁЎеһӢпјҢELECTRA зӣёеҜ№иҖҢиЁҖж–№жі•жҜ”иҫғзү№ж®ҠпјҢеңЁеҗҺйқўжҲ‘дјҡеҚ•зӢ¬иҜҙдёӢе®ғгҖӮйңҖиҰҒиҜҙжҳҺзҡ„жҳҜпјҢERNIE е’Ң NEZHA жЁЎеһӢпјҢж•Ҳжһңд№ҹжҳҜйқһеёёеҘҪзҡ„пјҢиғҪеӨҹжҺ’еңЁжҹҗдәӣжҰңеҚ•еүҚеҲ—гҖӮдҪҶжҳҜеӣ дёәе®ғ们еҜ№еә”зҡ„и®әж–ҮжҜ”иҫғж—©пјҢжҲ‘зҢңжөӢзҺ°еңЁжү“жҰңзҡ„жЁЎеһӢпјҢдј°и®Ўе’ҢеҺҹе§Ӣи®әж–Үдёӯзҡ„еҒҡжі•пјҢе·Із»ҸеҒҡдәҶеҸҳеҠЁпјҢдҪҶжҳҜе…·дҪ“жҖҺд№ҲеҸҳзҡ„дёҚжё…жҘҡпјҢжүҖд»ҘжІЎжңүеңЁдёҠйқўеҲ—иЎЁдёӯеҲ—еҮәгҖӮдёҠиҝ°иЎЁеҚ•пјҢеә”иҜҘеҹәжң¬еӣҠжӢ¬дәҶзӣ®еүҚж—¶й—ҙпјҲ2020 е№ҙ 9 жңҲпјүз»қеӨ§еӨҡж•°ж•ҲжһңжңҖеҘҪзҡ„йў„и®ӯз»ғжЁЎеһӢдәҶгҖӮ
дёҠиҝ°жЁЎеһӢпјҢйғҪиғҪжүҫеҲ°еҜ№еә”зҡ„ж–Үз« пјҢеҸҜдҫӣд»”з»ҶеҲҶжһҗжЁЎеһӢзҡ„жңүж•Ҳеӣ зҙ гҖӮеҰӮжһңдҪ д»”з»ҶеҲҶжһҗдёҠиҝ°еҗ„дёӘжЁЎеһӢзҡ„е…ұжҖ§пјҢдјҡеҸ‘зҺ°пјҢйӮЈдәӣзңҹжӯЈжңүж•Ҳзҡ„еӣ зҙ дјҡж…ўж…ўжө®еҮәж°ҙйқўгҖӮжҲ‘еңЁиҝҷйҮҢеҪ’зәідёҖдёӢпјҡдҝғиҝӣжЁЎеһӢжҖ§иғҪеҝ«йҖҹжҸҗй«ҳзҡ„еӣ зҙ пјҢдё»иҰҒеҢ…еҗ«дёӢеҲ—еҮ ж–№йқўгҖӮиҖҢдё”пјҢиҝҷеҮ ж–№йқўзҡ„еӣ зҙ жҳҜеҸҜеҸ еҠ зҡ„пјҢе°ұжҳҜиҜҙпјҢеҰӮжһңдёҖдёӘжЁЎеһӢйҮҮзәіе…¶дёӯи¶ҠеӨҡзҡ„еӣ зҙ пјҢйӮЈд№ҲиҝҷдёӘжЁЎеһӢзҡ„ж•ҲжһңиЎЁзҺ°еҸҜиғҪдјҡжӣҙеҘҪгҖӮ
йҰ–е…ҲпјҢжӣҙй«ҳиҙЁйҮҸгҖҒжӣҙеӨҡж•°йҮҸзҡ„йў„и®ӯз»ғж•°жҚ®гҖӮ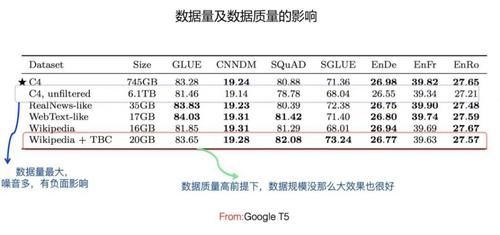
ж–Үз« еӣҫзүҮ
е…ідәҺйў„и®ӯз»ғж•°жҚ®еҜ№жЁЎеһӢж•Ҳжһңзҡ„еҪұе“ҚпјҢGoogle T5 еҒҡдәҶеӨ§йҮҸеҜ№жҜ”е®һйӘҢпјҢзӣ®еүҚзҡ„з»“и®әпјҢеҰӮжһңеҪ’зәідёҖдёӢзҡ„иҜқпјҢеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡеңЁдҝқиҜҒйў„и®ӯз»ғж•°жҚ®иҙЁйҮҸзҡ„еүҚжҸҗдёӢпјҢж•°жҚ®и§„жЁЎи¶ҠеӨ§жЁЎеһӢж•Ҳжһңи¶ҠеҘҪгҖӮиҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢж•°жҚ®и§„жЁЎи¶ҠеӨ§и¶ҠеҘҪпјҢиҝҷзӮ№е…¶е®һд»Һ Bert дёҖеҮәжқҘпјҢе°ұжҳҜдёҖдёӘе®№жҳ“жғіеҲ°зҡ„йҮҚиҰҒеӣ зҙ гҖӮеӣ дёәж•°жҚ®йҮҸи¶ҠеӨҡпјҢж•°жҚ®йҮҢи•ҙеҗ«зҡ„зҹҘиҜҶд№ҹи¶ҠеӨҡпјҢйӮЈд№ҲжЁЎеһӢиғҪеӯҰеҲ°зҡ„дёңиҘҝи¶ҠеӨҡпјҢжүҖд»ҘжЁЎеһӢж•ҲжһңдјҡжӣҙеҘҪпјҢиҝҷжҳҜдёҖдёӘйқ з®ҖеҚ•жҺЁзҗҶе°ұиғҪеҫ—еҮәзҡ„з»“и®әгҖӮдҪҶжҳҜпјҢе®ғжҳҜжңүеүҚжҸҗзҡ„пјҢеүҚжҸҗжҳҜж•°жҚ®иҙЁйҮҸиҰҒй«ҳпјҢе…үж•°жҚ®йҮҸеӨ§дёҚиЎҢпјҢеҫҲеӨҡд№ұдёғе…«зіҹзҡ„ж•°жҚ®пјҢеҸҚиҖҢдјҡеҜ№жЁЎеһӢж•ҲжһңеёҰжқҘиҙҹйқўеҪұе“ҚгҖӮ第дәҢпјҢеўһеҠ жЁЎеһӢе®№йҮҸеҸҠеӨҚжқӮеәҰгҖӮ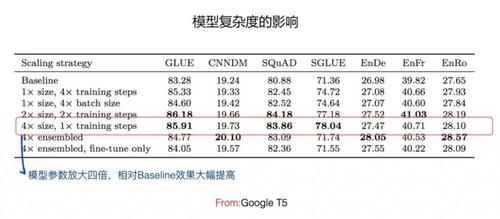
ж–Үз« еӣҫзүҮ
жүҖи°“еўһеҠ жЁЎеһӢе®№йҮҸеҸҠеӨҚжқӮеәҰпјҢжҢҮзҡ„жҳҜеўһеҠ Transformer жЁЎеһӢзҡ„еҸӮж•°йҮҸпјҢдёҖиҲ¬иҖҢиЁҖпјҢжЁЎеһӢе®№йҮҸи¶ҠеӨ§пјҢжЁЎеһӢзҡ„иЎЁиҫҫиғҪеҠӣи¶ҠејәгҖӮжңҖзӣҙжҺҘзҡ„еўһеҠ жЁЎеһӢе®№йҮҸзҡ„ж–№ејҸе°ұжҳҜеўһеҠ Transformer Block еұӮж·ұпјҢжҜ”еҰӮеҸҜд»Ҙд»Һ Bert base зҡ„ 12 еұӮпјҢеўһеҠ еҲ° Bert Large зҡ„ 24 еұӮпјҢиҝҳеҸҜд»Ҙ继з»ӯеўһеҠ еҲ°жҜ”еҰӮ 36 еұӮпјҢиҝҷжҳҜзәөеҗ‘еўһеҠ еӨҚжқӮеәҰпјҢGoogle T5 иө°зҡ„иҝҷжқЎи·ҜпјҲд»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢжЁЎеһӢе®№йҮҸеўһеҠ еҲ° 4 еҖҚеҗҺпјҢжңүдәӣж•°жҚ®йӣҶж•ҲжһңзӣёеҜ№ Baseline жңүеӨ§е№…еәҰзҡ„жҸҗеҚҮпјүгҖӮйҷӨжӯӨеӨ–пјҢиҝҳеҸҜд»ҘжЁӘеҗ‘еўһеҠ жЁЎеһӢеӨҚжқӮеәҰпјҢжҜ”еҰӮеңЁеӣәе®ҡ Transformer еұӮж·ұзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘйҖҡиҝҮж”ҫеӨ§ Transformer дёӯжһ„件зҡ„еӨ§е°ҸпјҢжҜ”еҰӮ Hidden Size зҡ„еўһеӨ§пјҢFFN еұӮеҜ№йҡҗеұӮзҡ„ж”ҫеӨ§пјҢMulti-Head Self Attention зҡ„ Attention еӨҙзҡ„еўһеҠ пјҢзӯүеӨҡз§Қж–№ејҸжқҘеҒҡеҲ°иҝҷдёҖзӮ№гҖӮALBERT иө°зҡ„иҝҷжқЎи·ҜпјҢе®ғзҡ„ xxLarge жЁЎеһӢж•ҲжһңжңҖеҘҪпјҢеҸӘз”ЁдәҶ 12 еұӮ Transformer BlockпјҢдҪҶжҳҜ Hidden Size иҫҫеҲ°дәҶ 4096гҖӮиҝҷдёӨз§ҚжЁЎејҸиҝҳеҸҜд»Ҙзӣёдә’з»“еҗҲпјҢе°ұжҳҜеҗҢж—¶зәөеҗ‘е’ҢжЁӘеҗ‘еўһеҠ жЁЎеһӢеӨҚжқӮеәҰпјҢGPT 3 еҚіжҳҜеҰӮжӯӨпјҢе°ҶжЁЎеһӢеӨҚжқӮеәҰиҝҷзӮ№жҺЁеҲ°дәҶжһҒиҮҙгҖӮеҚ•иҜҚзү№еҫҒзҡ„ Embedding дёҚдјҡж”ҫзҡ„еӨӘеӨ§пјҢдёҖиҲ¬йҮҮз”Ё 64 жҲ–иҖ… 128 еӨ§е°ҸпјҢALBERT иҜҒжҳҺдәҶеҰӮжһңеҚ•иҜҚзү№еҫҒ Embedding и·ҹзқҖ Transformer еҶ…йғЁзҡ„ Hidden Size еҗҢжӯҘж”ҫеӨ§пјҢж•ҲжһңеҸҚиҖҢдјҡйҷҚдҪҺгҖӮд№ҹе°ұжҳҜиҜҙпјҢеўһеҠ жЁЎеһӢе®№йҮҸжҢҮзҡ„жҳҜж”ҫеӨ§ Transformer жЁЎеһӢжң¬иә«зҡ„еҸӮж•°йҮҸпјҢдҪҶдёҚеҢ…жӢ¬иҫ“е…ҘеұӮ Embedding зҡ„еҸӮж•°гҖӮ
第дёүпјҢжӣҙе……еҲҶең°и®ӯз»ғжЁЎеһӢгҖӮ
иҝҷйҮҢжүҖи°“зҡ„"жӣҙе……еҲҶ"пјҢдёҖиҲ¬жҢҮзҡ„жҳҜж”ҫеӨ§ Batch SizeгҖҒеўһеҠ йў„и®ӯз»ғжӯҘж•°пјҢе°ұжҳҜ RoBERTa еҒҡзҡ„йӮЈдёӨдёӘдәӢжғ…гҖӮиҝҷеқ—дёҠж–Үжңүиҝ°пјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°гҖӮ
第еӣӣпјҢжңүйҡҫеәҰзҡ„йў„и®ӯз»ғд»»еҠЎгҖӮ
ж–Үз« еӣҫзүҮ
еҺҹе§Ӣзҡ„ Bert йў„и®ӯз»ғпјҢжңүдёӨдёӘи®ӯз»ғд»»еҠЎпјҡдёҖдёӘжҳҜеҚ•иҜҚзә§зҡ„ Mask иҜӯиЁҖжЁЎеһӢ MLMпјҢдёҖдёӘжҳҜеҸҘеӯҗзә§зҡ„дёӢдёҖеҸҘйў„жөӢд»»еҠЎ NSPгҖӮRoBERTa иҜҒжҳҺдәҶ NSP еҜ№дәҺжЁЎеһӢж•ҲжһңжІЎд»Җд№ҲеҪұе“ҚпјҢжүҖд»ҘжӢҝжҺүдәҶиҝҷдёӘд»»еҠЎгҖӮжңүеҫҲеӨҡз ”з©¶йӣҶдёӯеңЁиҝҷдёҖеқ—пјҢйҮҮеҸ–дәҶдә”иҠұе…«й—Ёзҡ„йў„и®ӯз»ғд»»еҠЎпјҲеҰӮдёҠеӣҫжүҖзӨәпјүгҖӮйӮЈд№Ҳе“Әдәӣйў„и®ӯз»ғд»»еҠЎзӣёеҜ№иҖҢиЁҖжӣҙжңүж•Ҳе‘ўпјҹзӣ®еүҚе·Із»ҸиғҪеӨҹеҫ—еҮәдәӣжҜ”иҫғжҳҺзЎ®зҡ„з»“и®әгҖӮеҰӮжһңеҪ’зәідёҖдёӢзҡ„иҜқпјҢеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡеҜ№дәҺеҚ•иҜҚзә§зҡ„ Mask иҜӯиЁҖжЁЎеһӢжқҘиҜҙпјҢSpan зұ»зҡ„йў„и®ӯз»ғд»»еҠЎж•ҲжһңжңҖеҘҪгҖӮжүҖи°“ Span зұ»зҡ„д»»еҠЎпјҢе°ұжҳҜ Mask жҺүзҡ„дёҚжҳҜдёҖдёӘзӢ¬з«Ӣзҡ„еҚ•иҜҚпјҢиҖҢжҳҜдёҖдёӘиҝһз»ӯзҡ„еҚ•иҜҚзүҮж–ӯпјҢиҰҒжұӮжЁЎеһӢжӯЈзЎ®йў„жөӢзүҮж–ӯеҶ…зҡ„жүҖжңүеҚ•иҜҚгҖӮSpan зұ»д»»еҠЎпјҢеҸӘжҳҜдёҖдёӘз»ҹз§°пјҢе®ғдјҡжңүдёҖдәӣиЎҚз”ҹзҡ„еҸҳдҪ“пјҢжҜ”еҰӮ N-GramпјҢе°ұжҳҜ Span жЁЎеһӢзҡ„дёҖдёӘеҸҳдҪ“пјҢеҶҚжҜ”еҰӮ Mask жҺүзҡ„дёҚжҳҜеҚ•иҜҚиҖҢжҳҜзҹӯиҜӯпјҢжң¬иҙЁдёҠд№ҹжҳҜ Span зұ»д»»еҠЎзҡ„еҸҳдҪ“пјҢиҝҷйҮҢжҲ‘们з»ҹз§°дёә Span зұ»д»»еҠЎгҖӮ
зӣ®еүҚжңүзӣёеҪ“еӨҡзҡ„з ”з©¶иҜҒжҳҺ Span зұ»д»»еҠЎжҳҜж•ҲжһңжңҖеҘҪзҡ„пјҢжңҖиҝ‘жңүдәӣе·ҘдҪңпјҲеҫ®иҪҜзҡ„ ProphetNet е’ҢзҷҫеәҰзҡ„ ERNIE-GENпјүиҝӣдёҖжӯҘиҜҙжҳҺпјҢSpan еҶ…еӨҡдёӘеҚ•иҜҚзӢ¬з«Ӣиў«з”ҹжҲҗж•ҲжһңдјҡжӣҙеҘҪгҖӮжүҖи°“зӢ¬з«Ӣз”ҹжҲҗпјҢдёҫдёӘдҫӢеӯҗпјҢеҒҮи®ҫиў« Mask жҺүзҡ„зүҮж–ӯжҳҜпјҡ[е…¬ејҸ] [е…¬ејҸ] [е…¬ејҸ] пјҢд№ӢеүҚдёҖиҲ¬ Span зұ»зҡ„йў„и®ӯз»ғжҳҜйЎәеәҸз”ҹжҲҗзүҮж–ӯеҶ…зҡ„еҚ•иҜҚпјҢе°ұжҳҜе…Ҳз”ҹжҲҗ [е…¬ејҸ] пјҢ然еҗҺж №жҚ®дёҠдёӢж–ҮеҸҠ [е…¬ејҸ] пјҢз”ҹжҲҗ [е…¬ејҸ] пјҢиҝҷд№ҲдёӘйЎәеәҸпјҢе°ұжҳҜиҜҙеәҸеҲ—з”ҹжҲҗзүҮж–ӯеҶ…еҚ•иҜҚгҖӮиҖҢзӢ¬з«Ӣз”ҹжҲҗпјҢе°ұжҳҜж №жҚ®дёҠдёӢж–ҮпјҢеҗҢж—¶з”ҹжҲҗ [е…¬ејҸ] пјҢ [е…¬ејҸ] е’Ң [е…¬ејҸ] пјҢиў«з”ҹжҲҗзҡ„еҚ•иҜҚд№Ӣй—ҙж— еҪұе“ҚгҖӮжүҖд»Ҙзӣ®еүҚеҚ•иҜҚзә§зҡ„ Mask иҜӯиЁҖжЁЎеһӢпјҢзӢ¬з«Ӣз”ҹжҲҗзҡ„ Span зұ»д»»еҠЎпјҢеә”иҜҘжҳҜзӣ®еүҚж•ҲжһңжңҖеҘҪзҡ„гҖӮ
жҺЁиҚҗйҳ…иҜ»





![[з»јиүәиҠӮзӣ®]ж—©еә”иҜҘиў«еҒңж’ӯзҡ„еҮ дёӘз»јиүәиҠӮзӣ®пјҢдёҚд»…еҶ…幕让дәәж°”ж„ӨпјҢз”ҡиҮіиҝҳиҜҜеҜјйқ’е°‘е№ҙ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/4d71220ab187d1a1594708332a467e22.jpg)









- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
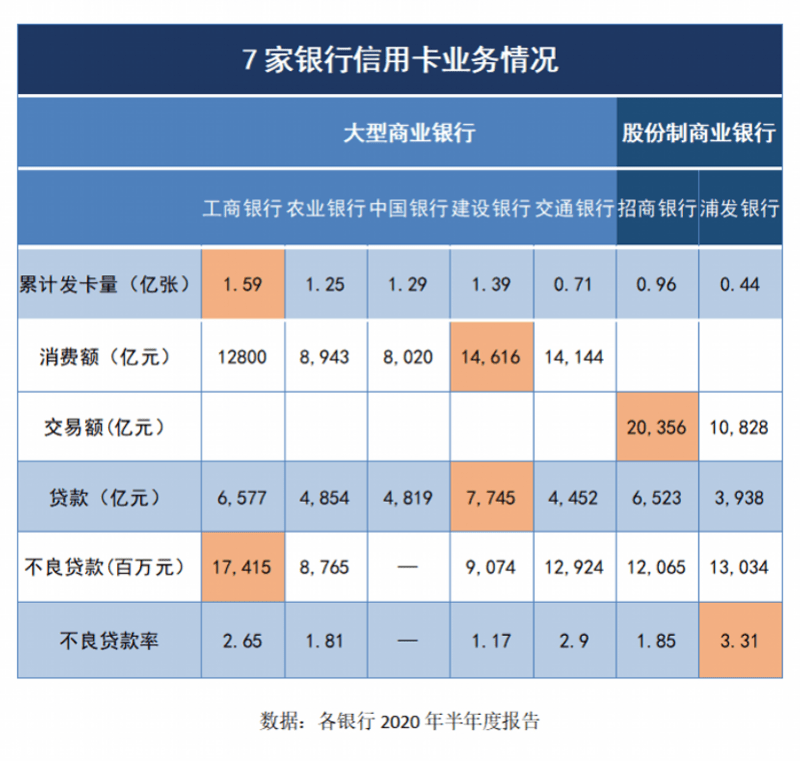
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ