PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( е…ӯ )
еҜ№дәҺеҸҘеӯҗзә§зҡ„д»»еҠЎпјҢNSP д»»еҠЎеӯҰд№ дёӨдёӘеҸҘеӯҗжҳҜеҗҰиҝһз»ӯеҸҘпјҡжӯЈдҫӢз”ұдёӨдёӘиҝһз»ӯеҸҘеӯҗжһ„жҲҗпјҢиҙҹдҫӢеҲҷйҡҸжңәйҖүжӢ©дёҖеҸҘи·ҹеңЁеүҚдёҖеҸҘд№ӢеҗҺпјҢиҰҒжұӮжЁЎеһӢйў„жөӢдёӨиҖ…жҳҜеҗҰиҝһз»ӯеҸҘеӯҗгҖӮжң¬иҙЁдёҠпјҢNSP еңЁйў„жөӢдёӨдёӘеҸҘеӯҗжҳҜеҗҰиЎЁиҫҫзӣёиҝ‘дё»йўҳпјҢиҖҢиҝҷдёӘд»»еҠЎпјҢзӣёеҜ№ MLM жқҘиҜҙпјҢиҝҮдәҺз®ҖеҚ•дәҶпјҢеҜјиҮҙжЁЎеһӢеӯҰдёҚеҲ°д»Җд№ҲзҹҘиҜҶгҖӮALBERT йҮҮз”ЁдәҶеҸҘеӯҗйЎәеәҸйў„жөӢ SOPпјҲSentence Order Predictionпјүпјҡи·ҹ NSP дёҖж ·пјҢдёӨдёӘиҝһз»ӯеҮәзҺ°зҡ„еҸҘеӯҗдҪңдёәжӯЈдҫӢпјҢдҪҶжҳҜеңЁжһ„йҖ иҙҹдҫӢзҡ„ж—¶еҖҷпјҢеҲҷдәӨжҚўеҸҘеӯҗжӯЈзЎ®йЎәеәҸпјҢиҰҒжұӮжЁЎеһӢйў„жөӢдёӨдёӘеҸҘеӯҗеҮәзҺ°йЎәеәҸжҳҜеҗҰжӯЈзЎ®пјҢиҝҷж ·еўһеҠ д»»еҠЎйҡҫеәҰпјҢStructBERT д№ҹйҮҮеҸ–дәҶзұ»дјјзҡ„еҒҡжі•гҖӮе®һйӘҢиҜҒжҳҺ SOP жҳҜжңүж•Ҳзҡ„еҸҘеӯҗзә§йў„жөӢд»»еҠЎгҖӮ
жҖ»иҖҢиЁҖд№ӢпјҢзӣ®еүҚиҜҒжҳҺ Span зұ»д»»еҠЎжҳҜжңүж•Ҳзҡ„еҚ•иҜҚзә§д»»еҠЎпјҢSOP жҳҜжңүж•Ҳзҡ„еҸҘеӯҗзә§д»»еҠЎгҖӮзӣ®еүҚзңӢпјҢйў„и®ӯз»ғд»»еҠЎи¶ҠжңүйҡҫеәҰпјҢеҲҷйў„и®ӯз»ғжЁЎеһӢи¶ҠиғҪй«ҳж•ҲзҺҮең°еӯҰд№ зҹҘиҜҶпјҢжүҖд»ҘеҜ»жүҫжӣҙж–°зҡ„жӣҙжңүйҡҫеәҰзҡ„йў„и®ӯз»ғд»»еҠЎжҳҜжңүиҫғеӨ§жҺўзҙўз©әй—ҙд»ҘеҸҠжҲҗеҠҹеҸҜиғҪзҡ„гҖӮ
дёҠйқўеҲ—дәҶеӣӣдёӘдё»иҰҒеӣ зҙ пјҢйӮЈд№ҲпјҢиҝҳжңүе…¶е®ғеӣ зҙ д№ҲпјҹжҲ‘зҡ„зҢңжөӢжҳҜеҹәжң¬жІЎжңүдәҶпјҢе°Ҫз®ЎеҸҜиғҪиҝҳжңүдёҖдәӣе·®ејӮеҢ–зҡ„ж”№иҝӣзӮ№жҳҜжңүж•Ҳзҡ„пјҢдҪҶе®ғеҜ№жңҖз»Ҳж•Ҳжһңзҡ„иҙЎзҢ®пјҢеә”иҜҘдёҚжҳҜзү№еҲ«еӨ§пјҢиө·з ҒдёҚеғҸдёҠиҝ°еӣӣдёӘеӣ зҙ йӮЈд№ҲеӨ§гҖӮдёҠйқўеӣӣдёӘеӣ зҙ пјҢеҰӮжһңиҝӣдёҖжӯҘиҰҒеҲ’еҲҶйҮҚиҰҒжҖ§зҡ„иҜқпјҢдј°и®ЎеүҚдёүдёӘйғҪеҫҲйҮҚиҰҒпјҢ第еӣӣдёӘзӣёеҜ№иҖҢиЁҖеҪұе“ҚзЁҚе°ҸдёҖдәӣгҖӮеҪ“然пјҢеҗҢж ·ең°пјҢиҝҷжҳҜжҲ‘дёӘдәәзҡ„зҢңжөӢпјҢи°Ёж…ҺеҸӮиҖғгҖӮ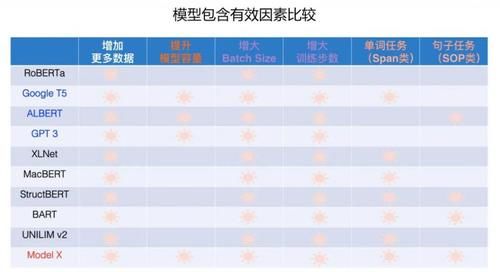
ж–Үз« еӣҫзүҮ
еҰӮжһңжҲ‘д»¬ж №жҚ®дёҠиҝ°еҸҜеҸ еҠ зҡ„жңүж•Ҳеӣ зҙ пјҢжқҘеҲҶжһҗзҺ°жңүжЁЎеһӢпјҢеҸҜеҫ—еҮәеҰӮдёҠеӣҫжүҖзӨәеҲ—иЎЁпјҲе…·еӨҮжҹҗеӣ зҙ зҡ„жЁЎеһӢпјҢеҜ№еә”зҡ„ж јеӯҗеҒҡдәҶж Үи®°пјүгҖӮд»ҺдёҠиЎЁдёӯпјҢжҲ‘们еҸҜд»Ҙеҫ—еҮәдёҖдәӣз»“и®әпјҡйҰ–е…ҲпјҢжүҖжңүиҝҷдәӣж•ҲжһңиЎЁзҺ°зӘҒеҮәзҡ„жЁЎеһӢпјҢйғҪеўһеҠ дәҶжӣҙеӨҡзҡ„й«ҳиҙЁйҮҸйў„и®ӯз»ғж•°жҚ®гҖӮеҸҰеӨ–пјҢйҖҡиҝҮеўһеӨ§ Batch Size д»ҘеҸҠеўһеҠ йў„и®ӯз»ғжӯҘж•°ж–№ејҸпјҢйғҪдҪҝеҫ—жЁЎеһӢеҫ—еҲ°жӣҙе……еҲҶең°и®ӯз»ғгҖӮд№ҹе°ұжҳҜиҜҙпјҢжүҖжңүиҝҷдәӣиЎЁзҺ°зӘҒеҮәзҡ„жЁЎеһӢпјҢйғҪжҳҜз«ҷеңЁ RoBERTa жЁЎеһӢзҡ„иӮ©иҶҖдёҠзҡ„гҖӮе…¶е®һпјҢеҸӘиҰҒдҪ з«ҷеңЁ RoBERTa иӮ©иҶҖдёҠпјҢж•ҲжһңйғҪдёҚдјҡеӨӘе·®пјҢеү©дёӢзҡ„й—®йўҳжҳҜиғҪжҜ”е®ғеҘҪеӨҡе°‘зҡ„й—®йўҳгҖӮ
е…¶ж¬ЎпјҢеҰӮжһңжҲ‘жқҘеҶ’жҳ§ең°еҒҡдёӘеҲӨж–ӯзҡ„иҜқпјҢиІҢдјјеҜ№дәҺиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎжқҘиҜҙпјҢдј°и®Ў Google T5 е’Ң ALBERT жҳҜж•ҲжһңжңҖеҘҪзҡ„йў„и®ӯз»ғжЁЎеһӢпјӣиҖҢеҜ№дәҺиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎжқҘиҜҙпјҢдј°и®Ў GPT3 жҳҜж•ҲжһңжңҖеҘҪзҡ„жЁЎеһӢгҖӮеҜ№дәҺ Google T5 е’Ң ALBERT жЁЎеһӢжқҘиҜҙпјҢдёӨиҖ…йғҪйҮҮзәідәҶз»қеӨ§йғЁеҲҶжңүж•Ҳеӣ зҙ пјҢдё»иҰҒдёҚеҗҢеңЁдәҺйў„и®ӯз»ғд»»еҠЎпјҢGoogle T5 йҮҮз”ЁдәҶ Span зұ»еҚ•иҜҚзә§д»»еҠЎпјҢиҖҢ ALBERT йҮҮз”ЁдәҶ SOP зұ»еҸҘеӯҗзә§д»»еҠЎгҖӮиҝҷдёүдёӘиЎЁзҺ°жңҖзӘҒеҮәзҡ„жЁЎеһӢпјҢе’Ңе…¶е®ғжЁЎеһӢжңҖеӨ§зҡ„еҢәеҲ«пјҢеӨ§жҰӮзҺҮеңЁдәҺе®ғ们еңЁеўһеҠ жӣҙеӨҡй«ҳиҙЁйҮҸж•°жҚ®зҡ„еҗҢж—¶пјҢиө°дәҶеӨ§и§„жЁЎжҸҗеҚҮжЁЎеһӢе®№йҮҸзҡ„и·ҜеӯҗгҖӮд№ҹе°ұжҳҜиҜҙпјҢеңЁеўһеҠ ж•°жҚ®и§„жЁЎеҹәзЎҖдёҠеӨ§и§„жЁЎеўһеҠ жЁЎеһӢе®№йҮҸпјҢиҝҷеә”иҜҘжҳҜжӢүејҖдёҚеҗҢжЁЎеһӢж•ҲжһңжңҖдё»иҰҒзҡ„еӣ зҙ гҖӮ
еҶҚж¬ЎпјҢжҲ‘们еҸҜд»ҘжҚ®жӯӨйў„жөӢпјҢеҰӮжһңдёҖдёӘжЁЎеһӢпјҢйҮҮзәідәҶдёҠиҝ°жүҖжңүжңүж•Ҳеӣ зҙ пјҢйӮЈд№ҲеҸҜд»ҘиҺ·еҫ—еҪ“еүҚжҠҖжңҜж°ҙеҮҶдёӢзҡ„жңҖеҘҪжЁЎеһӢж•ҲжһңпјҢе°ұеҰӮдёҠиЎЁдёӯжңҖеҗҺдёҖиЎҢеұ•зӨәзҡ„пјҢзӣ®еүҚд»ҚжңӘзҹҘзҡ„ Model X йӮЈж ·гҖӮе°ұжҳҜиҜҙпјҢиҝҷдёӘжЁЎеһӢеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡеңЁ RoBERTa жЁЎеһӢеҹәзЎҖдёҠпјҢеўһеҠ жӣҙеӨҡй«ҳиҙЁйҮҸж•°жҚ®зҡ„еҗҢж—¶пјҢе……еҲҶж”ҫеӨ§жЁЎеһӢе®№йҮҸпјҢиҖҢйў„и®ӯз»ғд»»еҠЎеҲҷжҳҜеҚ•иҜҚзұ» Span д»»еҠЎе’ҢеҸҘеӯҗзұ» SOP д»»еҠЎзҡ„з»“еҗҲгҖӮеҪ“然пјҢдј°и®ЎиҝҷйҮҢйқўиө·еҲ°дё»иҰҒдҪңз”Ёзҡ„иҝҳжҳҜеӨ§йҮҸж•°жҚ® + еӨ§жЁЎеһӢзҡ„еӣ зҙ гҖӮ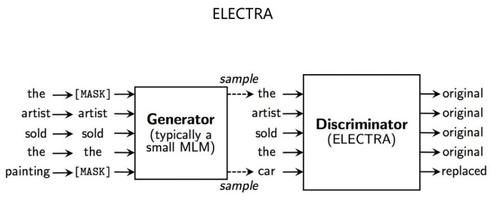
ж–Үз« еӣҫзүҮ
иҝҷйҮҢеҚ•зӢ¬иҜҙдёӢ ELECTRAпјҢиҝҷжҳҜдёҖдёӘжҜ”иҫғзӢ¬зү№зҡ„йў„и®ӯз»ғж–№жі•(еҸӮиҖғдёҠеӣҫ)гҖӮе®ғеҪўејҸдёҠйҮҮеҸ–дәҶзұ»дјј GAN зҡ„жЁЎејҸпјҢдҪҶжҳҜжң¬иҙЁдёҠ并йқһ GANпјҢеӣ дёәзјәд№Ҹ GAN жңҖе…ій”®зҡ„з”ҹжҲҗеҷЁе’ҢеҲӨеҲ«еҷЁзҡ„еҜ№жҠ—и®ӯз»ғиҝҮзЁӢгҖӮELECTRA иҒ”еҗҲи®ӯз»ғдәҶе°Ҹзҡ„з”ҹжҲҗеҷЁд»ҘеҸҠеӨ§зҡ„еҲӨеҲ«еҷЁпјҢе®ғејәиҝ«еҲӨеҲ«еҷЁеҜ№з”ҹжҲҗеҷЁдә§з”ҹзҡ„жүҖжңүеҚ•иҜҚпјҢеҒҡдёӘжҳҜеҗҰз»ҸиҝҮж”№еҶҷзҡ„еҲӨж–ӯпјҢиҝҷж— з–‘еўһеҠ дәҶжЁЎеһӢзҡ„еӯҰд№ ж•ҲзҺҮпјҢеӣ дёәеҺҹе…Ҳзҡ„ MLM еҸӘеӯҰд№ 15% зҡ„иў« Mask еҚ•иҜҚпјҢиҖҢ ELECTRA еҜ№жүҖжңүеҚ•иҜҚйғҪиҰҒиҝӣиЎҢеҲӨж–ӯпјҢ并д»ҺдёӯеӯҰд№ гҖӮELECTRA и®әж–ҮеҒҡдәҶеҲҶжһҗпјҢжЁЎеһӢзҡ„з»қеӨ§еӨҡ数收зӣҠжқҘиҮӘдәҺе…ЁйғЁеҚ•иҜҚеҸӮдёҺи®ӯз»ғиҝҷдёҖжӯҘгҖӮиҝҷж„Ҹе‘ізқҖпјҢELECTRA иҝҷз§ҚжүҖжңүеҚ•иҜҚе…Ёе‘ҳеҸӮдёҺи®ӯз»ғиҝҮзЁӢзҡ„жЁЎејҸпјҢиғҪеӨҹеңЁе…¶е®ғжқЎд»¶зӣёеҗҢзҡ„жғ…еҶөдёӢпјҲжЁЎеһӢеӨҚжқӮеәҰпјҢж•°жҚ®йҮҸзӯүпјүпјҢдҪҝеҫ—жЁЎеһӢиҺ·еҫ—жӣҙй«ҳзҡ„еӯҰд№ ж•ҲзҺҮпјҢиҝҷдёӘз»“и®әе’ҢеҒҡжі•иҝҳжҳҜеҫҲжңүд»·еҖјзҡ„гҖӮжң¬иҙЁдёҠпјҢELECTRA иҝҷз§ҚжҸҗеҚҮжЁЎеһӢж•ҲзҺҮзҡ„ж–№жі•пјҢе’ҢдёҠйқўжүҖиҝ°е…¶е®ғжЁЎеһӢзҡ„еҗ„з§ҚеҒҡжі•пјҢжҳҜзӣёдә’дә’иЎҘзҡ„гҖӮе°ұжҳҜиҜҙпјҢеңЁ ELECTRA зҡ„и®ӯз»ғжЁЎејҸдёӢпјҢеўһеҠ и®ӯз»ғж•°жҚ®гҖҒеўһеҠ жЁЎеһӢ规模гҖҒжЁЎеһӢе……еҲҶи®ӯз»ғпјҢжңүеҸҜиғҪиҺ·еҫ—жӣҙеҘҪзҡ„жЁЎеһӢж•ҲжһңгҖӮжҡҙеҠӣзҫҺеӯҰпјҡз®ҖеҚ•зІ—жҡҙдҪҶжңүж•Ҳ
еүҚж–Үжңүиҝ°пјҢRoBERTa жҳҜдёӘйқһеёёејәзҡ„ BaselineпјҢзӣёеҜ№зӣ®еүҚиЎЁзҺ°жңҖејәзҡ„ Google T5 е’Ң ALBERT жЁЎеһӢпјҢе…¶е®һ RoBERTa дёҺиҝҷдёӨдёӘеӨ©иҠұжқҝжЁЎеһӢд№Ӣй—ҙпјҢе®ғ们д№Ӣй—ҙзҡ„жҖ§иғҪ Gap 并дёҚжҳҜзү№еҲ«еӨ§гҖӮе…¶е®ғиЎЁзҺ°зӘҒеҮәзҡ„жЁЎеһӢпјҢиҰҒжҲ‘зҢңпјҢжҖ§иғҪеә”иҜҘд»ӢдәҺ RoBERTa иҝҷдёӘ Baseline е’ҢдёӨдёӘеӨ©иҠұжқҝжЁЎеһӢд№Ӣй—ҙгҖӮиҖҢжүҖжңүиҝҷдәӣжЁЎеһӢд№Ӣй—ҙзҡ„дё»иҰҒе·®ејӮпјҢжһҒжңүеҸҜиғҪжҳҜжЁЎеһӢе®№йҮҸзҡ„еӨ§е°Ҹе·®ејӮеёҰжқҘзҡ„гҖӮ
д»Һжҹҗз§Қи§’еәҰдёҠзңӢпјҢжҲ‘们еҸҜд»Ҙи®ӨдёәпјҡRoBERTa еҸҜд»Ҙиў«зңӢдҪңжҳҜз»ҸиҝҮжӣҙе……еҲҶи®ӯз»ғзҡ„ Bert жЁЎеһӢпјҢиҖҢ ALBERT/Google T5 еҸҜд»ҘзҗҶи§ЈдёәиҝӣдёҖжӯҘеўһеҠ дәҶжЁЎеһӢеӨҚжқӮеәҰзҡ„ RoBERTa еўһејәзүҲжң¬гҖӮд»Һ Bert еҲ° RoBERTaпјҢеҶҚеҲ° ALBERT/Google T5пјҢиҝҷдёүзұ»жЁЎеһӢпјҢеҫҲеҸҜиғҪд»ЈиЎЁдәҶиҮӘ Bert еҮәзҺ°жқҘзҡ„жңҖдё»иҰҒжҠҖжңҜиҝӣеұ•гҖӮжүҖд»ҘпјҢд»ҺжЁЎеһӢж”№иҝӣзҡ„и§’еәҰзңӢпјҢиҮӘд»Һ Bert иҜһз”ҹеҗҺиҝ‘дёӨе№ҙпјҢ并没жңүеҮәзҺ°зү№еҲ«жңүж•Ҳзҡ„жЁЎеһӢж”№иҝӣж–№жі•гҖӮе°Ҫз®Ўд»Һи§ЈеҶі NLP д»»еҠЎж•Ҳжһңзҡ„и§’еәҰзңӢпјҢж–°зҡ„йў„и®ӯз»ғжЁЎеһӢзӣёжҜ” Bert жңүдәҶе·ЁеӨ§зҡ„жҸҗеҚҮпјҢдҪҶжҳҜиҝҷдәӣжҸҗеҚҮпјҢеӨ§иҮҙеҸҜд»ҘзҗҶи§ЈдёәжҳҜеӣ дёәеј•е…ҘжӣҙеӨҡй«ҳиҙЁйҮҸж•°жҚ®гҖҒйҮҮз”ЁжӣҙеӨҡжЁЎеһӢеҸӮж•°гҖҒжЁЎеһӢи®ӯз»ғжӣҙе……еҲҶд»ҘеҸҠеўһеҠ и®ӯз»ғд»»еҠЎйҡҫеәҰиҝҷеҮ зӮ№з»јеҗҲеҜјиҮҙзҡ„гҖӮиҖҢе…¶дёӯпјҢеңЁ RoBERTa иҝҷз§Қе……еҲҶи®ӯз»ғзҡ„жЁЎеһӢеҹәзЎҖдёҠпјҢеўһеҠ ж•°жҚ®пјҢ并еҠ дёҠжӣҙеӨ§зҡ„жЁЎеһӢпјҢеҸҜиғҪеңЁе…¶дёӯиө·еҲ°дәҶдё»еҜјдҪңз”ЁгҖӮ
жҺЁиҚҗйҳ…иҜ»

![[зҰҸеёғж–Ҝ]зҰҸеёғж–Ҝйҹ©еӣҪеҸ‘еёғ2020йҹ©еӣҪеҗҚдәәжҰңпјҒеӣӣеӨ§йўҶеҹҹеүҚ10еҗҚеҚ•еҮәзӮү](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/upload/2020/8b0299279b94b146a77f684ed31ca1d4.png)














- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ