PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( еӣӣ )
ж–Үз« ең°еқҖпјҡhttps://zhuanlan.zhihu.com/p/70257427
PLM дёҖж ·йҮҮз”ЁеҚ•дёӘ Transformer жЁЎеһӢдҪңдёәдё»е№Із»“жһ„пјҢдҪҶжҳҜд»Һи®ӯз»ғж–№жі•дёҠжқҘиҜҙпјҢжҳҜдёӘеҫҲеҸҰзұ»д№ҹеҫҲжңүеҲӣж„Ҹзҡ„еҒҡжі•пјҢжҳҜз§Қ "еҪўдёә ARпјҢе®һдёә AE" зҡ„еҒҡжі•гҖӮеңЁиҜӯиЁҖжЁЎеһӢйў„и®ӯз»ғиҝҮзЁӢдёӯпјҢе®ғзңӢдёҠеҺ»йҒөеҫӘ AR д»Һе·ҰеҲ°еҸізҡ„иҫ“е…ҘиҝҮзЁӢпјҢиҝҷз¬ҰеҗҲдёҖиҲ¬з”ҹжҲҗд»»еҠЎзҡ„еӨ–еңЁиЎЁзҺ°еҪўејҸпјҢдҪҶжҳҜеңЁеҶ…йғЁйҖҡиҝҮ Attention MaskпјҢе®һйҷ…еҒҡжі•е…¶е®һжҳҜ AE зҡ„еҒҡжі•пјҢж— йқһжҳҜжҠҠ AE зҡ„еҒҡжі•йҡҗи—ҸеңЁ Transformer еҶ…йғЁгҖӮе®ғе’Ң AE д»Һз»ҶиҠӮжқҘиҜҙпјҢдё»иҰҒжңүдёӨдёӘеҢәеҲ«пјҡйҰ–е…ҲпјҢйў„и®ӯз»ғиҝҮзЁӢдёӯпјҢиҫ“е…ҘеҸҘеӯҗеҺ»жҺүдәҶ Mask ж Үи®°пјҢж”№дёәеҶ…йғЁ Attention MaskпјҢд»ҘдҝқжҢҒйў„и®ӯз»ғиҝҮзЁӢе’ҢдёӢжёёд»»еҠЎ Fine-tuning зҡ„дёҖиҮҙжҖ§гҖӮе…ідәҺиҝҷдёҖзӮ№пјҢзӣ®еүҚжңүе®һйӘҢиҜҒжҳҺиҝҷдёӘиҷҪ然жңүз§ҜжһҒеҪұе“ҚпјҢдҪҶжҳҜеҪұе“ҚдёҚеӨ§пјҲELECTRA й’ҲеҜ№йў„и®ӯз»ғиҝҮзЁӢжҳҜеҗҰеёҰ Mask ж Үи®°еҒҡдәҶж•ҲжһңеҜ№жҜ”пјҢеёҰ Mask ж Үи®°зҡ„ Bert жЁЎеһӢ GLUE еҫ—еҲҶ 82.2пјҢеҺ»жҺү Mask ж Үи®°еҲ©з”Ёе…¶е®ғеҚ•иҜҚд»Јжӣҝзҡ„еҜ№жҜ”жЁЎеһӢ GLUE еҫ—еҲҶ 82.4пјүпјӣе…¶ж¬ЎпјҢд№ҹжҳҜе®ғе’Ң AE зҡ„жңҖдё»иҰҒеҢәеҲ«пјҢPLM и®Өдёәиў« Mask жҺүзҡ„еҚ•иҜҚд№Ӣй—ҙжҳҜзӣёдә’жңүеҪұе“Қзҡ„пјҢе…Ҳдә§з”ҹзҡ„иў« Mask жҺүзҡ„еҚ•иҜҚпјҢеә”иҜҘеҜ№еҗҺз”ҹжҲҗзҡ„иў« Mask жҺүзҡ„еҚ•иҜҚпјҢеңЁйў„жөӢзҡ„ж—¶еҖҷеҸ‘з”ҹдҪңз”ЁпјҢиҖҢж ҮеҮҶзҡ„ AE еҲҷи®Өдёәиў« Mask жҺүзҡ„еҚ•иҜҚжҳҜзӣёдә’зӢ¬з«Ӣзҡ„пјҢзӣёдә’д№Ӣй—ҙдёҚдә§з”ҹдҪңз”ЁгҖӮ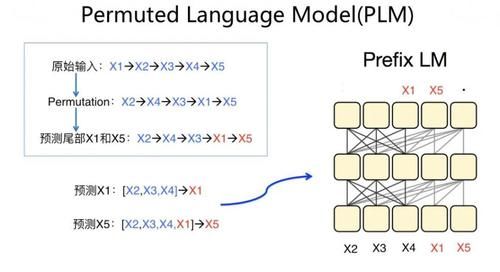
ж–Үз« еӣҫзүҮ
е…¶е®һпјҢ еҰӮжһңдҪ д»”з»ҶеҲҶжһҗдёӢ PLM зҡ„йў„и®ӯз»ғиҝҮзЁӢпјҢдјҡеҸ‘зҺ°жң¬иҙЁдёҠ PLM жҳҜ Prefix LM зҡ„дёҖз§ҚеҸҳдҪ“гҖӮдёҠеӣҫз»ҷеҮәдәҶдёӘдҫӢеӯҗжқҘиҜҙжҳҺиҝҷз§Қжғ…еҶөпјҢеҜ№дәҺжҹҗдёӘиҫ“е…ҘеҸҘеӯҗпјҢPLM йҰ–е…ҲдјҡиҝӣиЎҢеҚ•иҜҚйЎәеәҸйҡҸжңәеҸҳжҚўпјҢ然еҗҺйҖүе®ҡеҸҳжҚўеҗҺеҸҘеӯҗзҡ„жң«е°ҫдёҖйғЁеҲҶеҚ•иҜҚиҝӣиЎҢ MaskпјҢиў« Mask зҡ„еҚ•иҜҚйў„жөӢйЎәеәҸжҳҜжңүеәҸзҡ„пјҢжҢүз…§еҸҳжҚўеҗҺеңЁеҸҘдёӯе…ҲеҗҺйЎәеәҸжқҘйў„жөӢпјҢдёҠйқўдҫӢеӯҗдёӯдјҡе…Ҳйў„жөӢпјҢ然еҗҺеҶҚйў„жөӢгҖӮеңЁйў„жөӢзҡ„ж—¶еҖҷпјҢжңӘиў« Mask зҡ„дёҠдёӢж–ҮдјҡеҜ№йў„жөӢжңүеё®еҠ©пјӣеҒҮи®ҫе·Із»Ҹйў„жөӢ并иҫ“еҮәдәҶпјҢеңЁйў„жөӢзҡ„ж—¶еҖҷпјҢжңӘиў« Mask жҺүзҡ„дёҠдёӢж–ҮпјҢд»ҘеҸҠеҲҡйў„жөӢеҮәзҡ„пјҢдјҡеҜ№йў„жөӢжңүеё®еҠ©гҖӮе…¶е®һдҪ жғіпјҢиҝҷзӯүд»·дәҺд»Җд№Ҳпјҹзӯүд»·дәҺд»ҘдҪңдёәиҫ№з•ҢеҲҮеүІејҖзҡ„ Prefix LM жЁЎеһӢпјҢEncoder з«ҜеҢ…еҗ«пјҢDecoder дҫ§еҢ…еҗ«пјҢеңЁйў„жөӢзҡ„ж—¶еҖҷпјҢдёҚд»…иғҪзңӢеҲ° Encoder дҫ§зҡ„жүҖжңүиҫ“е…ҘпјҢд№ҹиғҪзңӢеҲ° Decoder дҫ§д№ӢеүҚзҡ„иҫ“еҮәгҖӮеҪ“然пјҢеӣ дёәжҜҸдёӘиҫ“е…ҘеҸҘеӯҗзҡ„й•ҝеәҰеҗ„ејӮпјҢиў« Mask жҺүзҡ„еҚ•иҜҚдёӘж•°д№ҹдёҚеӣәе®ҡпјҢжүҖд»ҘзңӢдёҠеҺ» Encoder е’Ң Decoder зҡ„иҫ№з•Ңж №жҚ®иҫ“е…ҘеҸҘеӯҗпјҢиҫ№з•ҢжҳҜеңЁеҠЁжҖҒеҸҳеҢ–зҡ„гҖӮжүҖд»ҘпјҢPLM е…¶е®һжҳҜдёҖз§Қиҫ№з•ҢеҸҳеҢ–зҡ„ Prefix LM еҸҳдҪ“з»“жһ„гҖӮеҪ“然пјҢдёҠйқўзәҜеұһдёӘдәәжҺЁзҗҶиҝҮзЁӢпјҢдёҚдҝқиҜҒжӯЈзЎ®жҖ§пјҢи°Ёж…ҺеҸӮиҖғгҖӮеҰӮжһңдёҚиҖғиҷ‘ XLNet йҮҢзҡ„е…¶е®ғеӣ зҙ пјҢеҚ•зәҜзңӢ PLM з»“жһ„зҡ„иҜқпјҢзӣ®еүҚжңүдәӣеҜ№жҜ”е®һйӘҢпјҢиІҢдјј PLM еңЁиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎдёӯпјҢж•ҲжһңдёҚеҸҠ Encoder-AEпјҲеҸӮиҖғ UniLM v2 и®әж–Үдёӯзҡ„еҜ№жҜ”е®һйӘҢпјҢжңӘеңЁжң¬ж–ҮеҲ—еҮәпјҢеҸҜеҸӮиҖғи®әж–ҮпјүпјӣеңЁиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎдёӯпјҢж•Ҳжһңз•Ҙеҫ®дјҳдәҺ Encoder-AEпјҢдҪҶжҳҜи·қзҰ» Decoder-AR е·®и·қиҫғеӨ§пјҲеҸӮиҖғ Encoder-AE жҸҸиҝ°йғЁеҲҶ BART зҡ„еҜ№жҜ”е®һйӘҢпјүгҖӮеңЁдёӨзұ»д»»еҠЎдёӯпјҢйғҪжңүзӮ№дёҠдёҚзқҖжқ‘пјҢдёӢдёҚзқҖеә—зҡ„ж„ҹи§үпјҢе°ұжҳҜйғҪиҝҳеҸҜд»ҘпјҢдҪҶйғҪдёҚеӨҹеҘҪзҡ„ж„ҹи§үгҖӮXLNet ж•ҲжһңзЎ®е®һжҳҜеҫҲеҘҪзҡ„пјҢдҪҶжҳҜпјҢиҝҷиҜҙжҳҺ XLNet ж•ҲжһңеҘҪпјҢзңҹжӯЈиө·дҪңз”Ёзҡ„иІҢдјјдёҚжҳҜ PLMпјҢиҖҢжҳҜе…¶е®ғеӣ зҙ гҖӮ
дёҠйқўеҶ…е®№з®Җиҝ°дәҶеёёи§Ғзҡ„дә”з§Қйў„и®ӯз»ғжЁЎеһӢз»“жһ„пјҢеҰӮжһңжҖ»з»“дёҖдёӢзҡ„иҜқпјҡ
йҰ–е…ҲпјҢд»ҺжЁЎеһӢж•ҲжһңжқҘзңӢпјҢEncoder-Decoder з»“жһ„ж— и®әеңЁиҜӯиЁҖзҗҶи§Јзұ»иҝҳжҳҜиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎдёӯпјҢйғҪжҳҜж•ҲжһңжңҖеҘҪзҡ„гҖӮеҪ“然пјҢж•ҲжһңеҘҪзҡ„еҺҹеӣ еҫҲеҸҜиғҪеңЁдәҺжЁЎеһӢеҸӮж•°еӨҡпјҢжЁЎеһӢе®№йҮҸеӨ§пјҢиҖҢдёҚдёҖе®ҡжҳҜиҮӘиә«з»“жһ„еёҰжқҘзҡ„дјҳеҠҝгҖӮе®ғзҡ„дјҳзӮ№дёҖдёӘжҳҜж•ҲжһңеҘҪпјҢдёҖдёӘжҳҜиғҪеӨҹе°ҶзҗҶи§Је’Ңз”ҹжҲҗд»»еҠЎз»ҹдёҖеңЁдёҖдёӘжЎҶжһ¶дёӢпјӣзјәзӮ№жҳҜеҸӮж•°еӨҡи®Ўз®—еӨҡпјҢжүҖд»ҘжЁЎеһӢжҜ”иҫғйҮҚгҖӮйҮҮз”ЁиҝҷдёӘз»“жһ„зҡ„д»ЈиЎЁжЁЎеһӢеҢ…жӢ¬ Google T5 е’Ң BARTгҖӮ
е…¶ж¬ЎпјҢеӣ дёә Encoder-Decoder жЁЎеһӢжҜ”иҫғйҮҚпјҢжүҖд»ҘпјҢеҰӮжһңд»ҺзӣёеҜ№иҪ»йҮҸз»“жһ„йҮҢиҝӣиЎҢйҖүжӢ©зҡ„иҜқпјҢеҜ№дәҺиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎпјҢEncoder-AE з»“жһ„зӣёеҜ№иҖҢиЁҖж•ҲжһңиҫғеҘҪпјҢд»ЈиЎЁжЁЎеһӢеҫҲеӨҡпјҢе…ёеһӢзҡ„жҜ”еҰӮ ALBertгҖҒRoBERTaпјӣеҜ№дәҺиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎпјҢDecoder-AR з»“жһ„е’Ң Prefix LM з»“жһ„зӣёеҜ№иҖҢиЁҖж•ҲжһңиҫғеҘҪпјҢйғҪеҸҜиҖғиҷ‘пјҢDecoder-AR зҡ„д»ЈиЎЁжЁЎеһӢжҳҜ GPT зі»еҲ—пјҢPrefix LM зҡ„д»ЈиЎЁжЁЎеһӢжҳҜ UniLMгҖӮиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎеә”иҜҘз”Ё AE д»»еҠЎпјҢиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎеә”иҜҘз”Ё AR д»»еҠЎпјҢиҝҷзӮ№д№ҹеҫҲжҳҺзЎ®дәҶгҖӮ
и°Ҳе®ҢдәҶжЁЎеһӢз»“жһ„пјҢдёӢйқўжҲ‘们жқҘзӣҳзӮ№дёӢиЎЁзҺ°жҜ”иҫғеҘҪзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢ并еҲҶжһҗдёӢж•ҲжһңеҘҪиғҢеҗҺзҡ„еҺҹеӣ гҖӮ
ејәиҖ…зҡ„зӢӮж¬ўпјҡдёәд»Җд№ҲжңүдәӣжЁЎеһӢиЎЁзҺ°иҝҷд№ҲеҘҪ
зӣ®еүҚ Bert зҡ„ж”№иҝӣжЁЎеһӢжңүеҫҲеӨҡпјҢжңүзҡ„иЎЁзҺ°йқһеёёзӘҒеҮәпјҢжңүзҡ„иЎЁзҺ°дёҖиҲ¬гҖӮжҲ‘зҡ„дё»иҰҒзӣ®зҡ„жҳҜжғіжүҫеҮәйӮЈдәӣиЎЁзҺ°еҘҪзҡ„жЁЎеһӢпјҢ并еҲҶжһҗдёӢпјҢеҲ°еә•жҳҜе“Әдәӣеӣ зҙ еҜјиҮҙиҝҷдәӣжЁЎеһӢж•Ҳжһңи¶…зҫӨзҡ„гҖӮ
йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒе…ҲжүҫеҮәйӮЈдәӣиЎЁзҺ°зү№еҲ«еҘҪзҡ„жЁЎеһӢеҮәжқҘпјҢжҲ‘иҝҷйҮҢиҜҙзҡ„иЎЁзҺ°еҘҪпјҢдё»иҰҒжҳҜд»ҺжЁЎеһӢж•Ҳжһңи§’еәҰжқҘиҜҙзҡ„пјҢе°ұжҳҜйӮЈдәӣеңЁе…¬ејҖж•°жҚ®йӣҶдёҠжҢҮж ҮжҜ”иҫғй«ҳзҡ„жЁЎеһӢгҖӮдёҖз§ҚжҜ”иҫғз®ҖеҚ•зҡ„ж–№жі•е°ұжҳҜпјҡжүҫ GLUEгҖҒSuperGLUEгҖҒSQuAD 2.0 иҝҷеҮ дёӘеӨ§и§„жЁЎ NLP ж•°жҚ®дёҠпјҢйӮЈдәӣжү“жҰңжЁЎеһӢдёӯжҺ’еҗҚеүҚеҲ—зҡ„гҖӮдҪ еҸҜд»ҘзңӢдёҖдёӢпјҢиҮӘд»Һ Bert еҮәзҺ°еҗҺпјҢиҝҷеҮ дёӘжҰңеҚ•пјҢйғҪй•ҝе№ҙиў«йў„и®ӯз»ғжЁЎеһӢйңёжҰңпјҢжҢҮж ҮеңЁиў«еҗ„з§Қж–°зҡ„йў„и®ӯз»ғжЁЎеһӢеҝ«йҖҹеҲ·й«ҳпјҢзӣҙеҲ°и¶…иҝҮдәәзұ»зҡ„ж°ҙеҮҶгҖӮдёҖиҲ¬иҖҢиЁҖпјҢиғҪеӨҹжү“жҰңжҠҠжҢҮж ҮеҲ·еҲ°еүҚеҲ—зҡ„пјҢйғҪжҳҜеҘҪжЁЎеһӢпјҢиҜҙжҳҺиҝҷдәӣжЁЎеһӢзңҹзҡ„иғҪжү“пјҲжҸ’еҸҘй—ІиҜқпјҢиҝҷзӮ№е…¶е®һзү№еҲ«еҖјеҫ—жҺЁиҚҗйўҶеҹҹеҖҹйүҙпјҢе°ұжҳҜжңүдёӘеӨ§и§„жЁЎй«ҳйҡҫеәҰж•°жҚ®йӣҶпјҢдҫӣеҗ„з§ҚжЁЎеһӢй•ҝе№ҙеҲ·жҰңпјҢиҝҷе…¶е®һжҳҜдҝғиҝӣйўҶеҹҹжҠҖжңҜиҝӣжӯҘеҫҲеҘҪзҡ„жүӢж®өпјүгҖӮ
еҪ“然пјҢд№ҹжңүдёҖдәӣж–°жЁЎеһӢпјҢеҸҜиғҪжңӘеҝ…дјҡеҺ»жү“жҰңпјҢжүҖд»ҘдҪңдёәиЎҘе……жҺӘж–ҪпјҢжҲ‘еҸҲд»ҺжҜ”иҫғж–°зҡ„ж–ҮзҢ®дёӯпјҢжүҫеҮәдёҖдәӣжЁЎеһӢпјҢеүҚжҸҗжҳҜе®ғеңЁж–ҮзҢ®дёӯжҠҘйҒ“зҡ„ж•ҲжһңиҰҒжҜ” RoBERTa еҘҪгҖӮ
жҺЁиҚҗйҳ…иҜ»

















- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ